Virtual Partitions
Virtual Partitions allow you to parallelize the processing of data from a single partition. This can drastically increase throughput when IO operations are involved.
While the default scaling strategy for Kafka consumers is to increase partitions count and number of consumers, in many cases, this will not provide you with desired effects. In the end, you cannot go with this strategy beyond assigning one process per single topic partition. That means that without a way to parallelize the work further, IO may become your biggest bottleneck.
Virtual Partitions solve this problem by providing you with the means to further parallelize work by creating "virtual" partitions that will operate independently but will, as a collective processing unit, obey all the Kafka warranties.
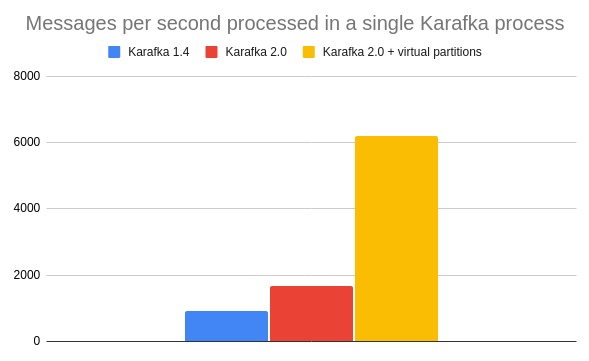
*This example illustrates the throughput difference for IO intense work, where the IO cost of processing a single message is 1ms.
Using Virtual Partitions
The only thing you need to add to your setup is the virtual_partitions definition for topics for which you want to enable it:
class KarafkaApp < Karafka::App
setup do |config|
# ...
end
routes.draw do
topic :orders_states do
consumer OrdersStatesConsumer
# Distribute work to virtual partitions per order id
virtual_partitions(
partitioner: ->(message) { message.headers['order_id'] },
# Defines how many concurrent virtual partitions will be created for this
# topic partition. When not specified, Karafka global concurrency setting
# will be used to make sure to accommodate as many worker threads as possible.
max_partitions: 5
)
end
end
end
No other changes are needed.
The virtual partitioner requires to respond to a #call method, and it accepts a single Karafka message as an argument.
The return value of this partitioner needs to classify messages that should be grouped uniquely. We recommend using simple types like strings or integers.
User-Handled Errors in Partitioner
Handling errors within the partitioner is primarily the user's responsibility. However, Karafka will catch partitioning errors. Suppose an error occurs even once for a given message in a batch. In that case, Karafka will emit an error via error.occurred and will proceed by assigning all messages from that batch to a single virtual partition. Despite this safeguard, users must manage and mitigate any exceptions or errors in their custom partitioning logic to ensure their application's smooth operation and prevent unexpected behavior and potential data processing issues.
Available Options
Below is a list of arguments the #virtual_partitions topic method accepts.
| Parameter | Type | Description |
|---|---|---|
max_partitions |
Integer | Max number of virtual partitions that can come from the single distribution flow. When set to more than the Karafka threading, it will create more work than workers. When less, we can ensure we have spare resources to process other things in parallel. |
partitioner |
#call |
Virtual Partitioner we want to use to distribute the work. |
offset_metadata_strategy |
Symbol | How we should match the metadata for the offset. :exact will match the offset matching metadata and :current will select the most recently reported metadata. |
reducer |
#call |
Reducer for VPs key. It allows for a custom reducer to achieve enhanced parallelization when the default reducer is insufficient. |
distribution |
Symbol |
Strategy used to distribute messages across virtual partitions:
|
Messages Distribution
Message distribution is based on the outcome of the virtual_partitions settings. Karafka will make sure to distribute work into jobs with a similar number of messages in them (as long as possible). It will also take into consideration the current concurrency setting and the max_partitions setting defined within the virtual_partitions method and will take into consideration appropriate :strategy.
Below is a diagram illustrating an example partitioning flow of a single partition data. Each job will be picked by a separate worker and executed in parallel (or concurrently when IO is involved).

Partitioning Based on the Message Key
Suppose you already use message keys to direct messages to partitions automatically. In that case, you can use those keys to distribute work to virtual partitions without any risks of distributing data incorrectly (splitting dependent data to different virtual partitions):
routes.draw do
topic :orders_states do
consumer OrdersStatesConsumer
# Distribute work to virtual partitions based on the message key
virtual_partitions(
partitioner: ->(message) { message.key }
)
end
end
Partitioning Based on the Message Payload
Since the virtual partitioner accepts the message as the argument, you can use both #raw_payload as well as #payload to compute your distribution key:
routes.draw do
topic :orders_states do
consumer OrdersStatesConsumer
# Distribute work to virtual partitions based on the user id, ensuring,
# that per user, everything is in order
virtual_partitions(
partitioner: ->(message) { message.payload.fetch('user_id') }
)
end
end
Lazy Deserialization Advisory
Keep in mind that Karafka provides lazy deserialization. If you decide to use payload data, deserialization will happen in the main thread before the processing. That is why, unless needed, it is not recommended.
Partitioning Randomly
If your messages are independent, you can distribute them randomly by running rand(Karafka::App.config.concurrency) for even work distribution:
routes.draw do
topic :orders_states do
consumer OrdersStatesConsumer
# Distribute work to virtual partitions based on the user id, ensuring,
# that per user, everything is in order
virtual_partitions(
partitioner: ->(_) { rand(Karafka::App.config.concurrency) }
)
end
end
Round-Robin Partitioning
If your messages are independent, you can also distribute them round-robin, ensuring their even distribution even during periods of lower traffic.
# Create your partitioner
class RoundRobinPartitioner
def initialize
# You can replace the general concurrency with a VPs limit
@cycle = (0...Karafka::App.config.concurrency).cycle
end
# @param _message [Karafka::Messages::Message] ignored as partitioner not message based
# @return [Integer] VP assignment partition
# @note This always runs in the partitioner within the listener thread,
# so standard Ruby iterator is ok as no thread-safety issues are expected
def call(_message)
@cycle.next
end
end
# Assign it to the topics you want
routes.draw do
topic :orders_states do
consumer OrdersStatesConsumer
# Distribute work to virtual partitions based on the user id, ensuring,
# that per user, everything is in order
virtual_partitions(
partitioner: RoundRobinPartitioner.new
)
end
end
Distribution Strategies
Karafka's Virtual Partitions feature provides two distribution strategies to determine how messages are allocated across consumer instances:
:consistent(default):balanced.
These strategies give you flexibility in optimizing message distribution based on your specific workload characteristics and processing approach.
Consistent Distribution (Default)
By default, Karafka uses a consistent distribution strategy that ensures messages with the same partitioner result are always assigned to the same virtual partition consumer. This provides predictable and stable message routing, particularly important for stateful processing or when message order within a key group must be preserved across multiple batches.
routes.draw do
topic :orders_states do
consumer OrdersStatesConsumer
virtual_partitions(
partitioner: ->(message) { message.headers['order_id'] },
# Default - each key always gets routed to the same virtual partition
# This provides consistent multi-batch distribution
distribution: :consistent
)
end
end
The consistent distribution strategy ensures that:
- The same virtual partition always processes messages with the same partitioner outcome
- Distribution remains stable between batches
- Per-key ordering is strictly maintained
However, consistent distribution can sometimes lead to suboptimal resource utilization when certain keys contain significantly more messages than others, potentially leaving some worker threads idle while others are overloaded.
Balanced Distribution
Karafka also supports a balanced distribution strategy that dynamically distributes workloads across available workers, potentially improving resource utilization by up to 50%. This strategy prioritizes even work distribution while maintaining message order within each key group.
routes.draw do
topic :orders_states do
consumer OrdersStatesConsumer
virtual_partitions(
partitioner: ->(message) { message.headers['order_id'] },
# Balanced distribution for more even workload distribution
distribution: :balanced
)
end
end
The balanced distribution strategy operates as follows:
- Messages are grouped by their partition key (as determined by the partitioner)
- Key groups are sorted by size (number of messages) in descending order
- Each key group is assigned to the worker with the least current workload
- Messages within each group maintain their offset order
This approach ensures that:
- Larger message groups are processed first
- Work is distributed more evenly across available workers
- Message order within each key group is preserved within a single batch
- All available worker threads are utilized effectively
Important Considerations for Balanced Distribution
When using the balanced distribution strategy, keep in mind:
- Cross-batch assignment is not guaranteed - Unlike consistent distribution, the same key may be assigned to different virtual partitions across different batches
- Stateful processing considerations - If your consumer maintains state for specific keys across multiple batches, consistent distribution may still be more appropriate
- Messages with the same key are never split - While keys may be assigned to different virtual partitions in different batches, all messages with the same key in a single batch will be processed together
Choosing the Right Distribution Strategy
Consider these factors when selecting a distribution strategy:
Use :consistent when: |
Use :balanced when: |
|---|---|
| Processing requires stable assignment of keys to workers across batches | Processing is stateless or state is managed externally |
| You're implementing window-based aggregations spanning multiple polls | Maximizing worker thread utilization is a priority |
| Predictable routing is more important than even utilization | Message keys have highly variable message counts |
| Keys have relatively similar message counts | You want to optimize for throughput with uneven workloads |
Performance Comparison
The balanced distribution strategy can significantly improve resource utilization in high-throughput scenarios with uneven message distribution. Internal benchmarks show improvements of up to 50% in throughput for workloads where:
- Message keys have highly variable message counts
- Processing is IO-bound (such as database operations)
- Worker threads would otherwise be underutilized with consistent distribution
The performance gains are most significant when:
- Some keys contain many more messages than others
- The total number of keys is greater than the number of available worker threads
- Message processing involves IO operations that can benefit from concurrent execution
Managing Number of Virtual Partitions
By default, Karafka will create at most Karafka::App.config.concurrency concurrent Virtual Partitions. This approach allows Karafka to occupy all the threads under optimal conditions.
Limiting Number of Virtual Partitions
However, it also means that other topics may not get their fair share of resources. To mitigate this, you may dedicate only 80% of the available threads to Virtual Partitions.
setup do |config|
config.concurrency = 10
end
routes.draw do
topic :orders_states do
consumer OrdersStatesConsumer
virtual_partitions(
partitioner: ->(message) { message.payload.fetch('user_id') },
# Leave two threads for other work of other topics partitions
# (non VP or VP of other partitions)
max_partitions: 8
)
end
end
Virtual Partitions Workload Distribution
Virtual Partitions max_partitions setting applies per topic partition. In the case of processing multiple partitions, there may be a case where all the work happens on behalf of Virtual Partitions.
Increasing Number of Virtual Partitions
There are specific scenarios where you may be interested in having more Virtual Partitions than threads. One example would be to create one Virtual Partition for the data of each user. If you set the max_partitions to match the max_messages, Karafka will create each Virtual Partition based on your grouping without reducing it to match number of worker threads.
setup do |config|
config.concurrency = 10
config.max_messages = 200
end
routes.draw do
topic :orders_states do
consumer OrdersStatesConsumer
virtual_partitions(
partitioner: ->(message) { message.payload.fetch('user_id') },
# Make sure, that each virtual partition always contains data of only a single user
max_partitions: 200
)
end
end
Virtual Partitions Lifespan
Please remember that Virtual Partitions are long-lived and will stay in the memory for as long as the Karafka process owns the given partition.
Virtual Offset Management
When Karafka consumes messages with Virtual Partitions, it uses Virtual Offset Management, which is built on top of the regular offset management mechanism. This innovative approach enables a significant reduction in potentially double-processed messages. By employing Virtual Offset Management, Karafka intelligently tracks the offsets of messages consumed in all the virtual partitions, ensuring that each message is consumed only once, regardless of errors. This powerful feature enhances the reliability and efficiency of message processing, eliminating the risk of duplicate processing and minimizing any associated complications, thereby enabling seamless and streamlined data flow within your system.
This feature operates on a few layers to provide as good warranties as possible while ensuring that each virtual partition can work independently. Below you can find a detailed explanation of each component making Virtual Offset Management.
Collective State Materialization
While each of the Virtual Partitions operates independently, they are bound together to a single Kafka Partition. Collective State Materialization transforms the knowledge of messages marked as consumed in each virtual partition into a Kafka offset that can be committed. This process involves computing the highest possible offset by considering all the messages marked as consumed from all the virtual partitions. By analyzing the offsets across virtual partitions, Karafka can determine the maximum offset reached, allowing for an accurate and reliable offset commit to Kafka. This ensures that the state of consumption is properly synchronized and maintained.
Whenever you mark_as_consumed when using Virtual Partitions, Karafka will ensure that Kafka receives the highest possible continuous offset matching the underlying partition.
Below you can find a few examples of how Karafka transforms messages marked as consumed in virtual partitions into an appropriate offset that can be committed to Kafka.

Virtual Partition Collective Marking
When a message is marked as consumed, Karafka recognizes that all previous messages in that virtual partition have been processed as well, even if they were not explicitly marked as consumed.
This functionality seamlessly integrates with collective marking to materialize the highest possible Kafka offset. With collective marking, Karafka can efficiently track the progress of message consumption across different virtual consumers.
Below you can find an example illustrating which of the messages will be virtually marked as consumed when given message in a virtual partition is marked.

Reprocessing Exclusions
When using Virtual Partitions, Karafka automatically skips previously consumed messages upon retries. This feature ensures that in the event of an error during message processing in one virtual partition, Karafka will not attempt to reprocess the messages that have already been marked as consumed in any of the virtual partitions.
By automatically skipping already consumed messages upon encountering an error, Karafka helps ensure the reliability and consistency of message processing. It prevents the application from reprocessing messages unnecessarily and avoids potential data duplication issues during error recovery scenarios.
This behavior is advantageous in scenarios where message processing involves external systems or operations that are not idempotent. Skipping previously consumed messages reduces the risk of executing duplicate actions and helps maintain the integrity of the overall system.

Behaviour on Errors
For a single partition-based Virtual Partitions group, offset management and retries policies are entangled. They behave on errors precisely the same way as regular partitions with one difference: back-offs and retries are applied to the underlying regular partition. This means that if an error occurs in one of the virtual partitions, Karafka will pause based on the highest possible Virtual Offset computed using the Virtual Offset Management feature and will exclude all the messages that were marked as consumed in any of the virtual partitions.

If processing in all virtual partitions ends up successfully, Karafka will mark the last message from the underlying partition as consumed.
Impact of Pausing on Message Count
Since pausing happens in Kafka, the re-fetched data may contain more or fewer messages. This means that after retry, the number of messages and their partition distribution may differ. Despite that, all ordering warranties will be maintained.
Collapsing
When an error occurs in virtual partitions, pause, retry and collapse will occur. Collapsing allows virtual partitions to temporarily restore all the Kafka ordering warranties allowing for the usage of things like offset marking and Dead-Letter Queue.
You can detect that your Virtual Partitions consumers are operating in the collapsed mode by invoking the #collapsed? method:
class EventsConsumer < ApplicationConsumer
def consume
messages.each do |message|
Event.store!(message.payload)
puts 'We operate in a collapsed mode' if collapsed?
end
end
end

*This example illustrates the retry and collapse of two virtual partitions into one upon errors.
Usage with Dead Letter Queue
Virtual Partitions can be used together with the Dead Letter Queue. This can be done due to Virtual Partitions' ability to collapse upon errors.
The only limitation when combining Virtual Partitions with the Dead Letter Queue is the minimum number of retries. It needs to be set to at least 1:
routes.draw do
topic :orders_states do
consumer OrdersStatesConsumer
virtual_partitions(
partitioner: ->(message) { message.headers['order_id'] }
)
dead_letter_queue(
topic: 'dead_messages',
# Minimum one retry because VPs needs to switch to the collapsed mode
max_retries: 1
)
end
end
DLQ independent mode usage with Virtual Partitions
The independent DLQ flag in Karafka can be used with the Virtual Partitions. When an error occurs in virtual partitions, pause, retry, and collapse will occur. Collapsing allows virtual partitions to temporarily restore all the Kafka ordering warranties, meaning that the independent flag can operate in the same fashion as if virtual partitions were not used.
Manual Collapsing
When working with Virtual Partitions in Karafka, users can manually invoke a collapsing operation. This provides flexibility and control, especially when non-linear message processing is required.
Just as an error in a Virtual Partition will trigger a collapse, ensuring adherence to Kafka's ordering warranties upon retries, users can also initiate this collapse process manually. By doing so, the Virtual Partitions temporarily collapse and restore the natural message processing order established by Kafka.
To manually collapse your Virtual Partitions, you need to invoke the #collapse_until! method as follows:
class EventsConsumer < ApplicationConsumer
def consume
imported, failed = import(messages)
return if failed.empty?
# Collapse until last broken message
collapse_until!(failed.last.offset)
# Note, that pausing is collective for all VPs, hence we need to make sure, that when we pause
# we select the lowest offset out of all VPs for a given topic partition
synchronize do
lowest_offset = PauseManager.pause(topic, partition, failed.first.offset)
pause(lowest_offset, 5_000)
end
end
end
When multiple Virtual Partitions invoke the #collapse_until! method concurrently, Karafka ensures consistency by considering all requested offsets. If different partitions request different offsets, the system will prioritize and collapse until the highest requested offset. This ensures that no messages before that offset are processed out of order, maintaining the integrity of your message stream even in complex processing scenarios. So, if multiple collapses are requested simultaneously, the most conservative (highest offset) collapse request takes precedence.
Ordering Warranties
Virtual Partitions provide three types of warranties in regards to order:
- Standard warranties per virtual partitions group - that is, from the "outside" of the virtual partitions group Kafka ordering warranties are preserved.
- Inside each virtual partition - the partitioner order is always preserved. That is, offsets may not be continuous (1, 2, 3, 4), but lower offsets will always precede larger (1, 2, 4, 9). This depends on the
virtual_partitionspartitionerused for partitioning a given topic. - Strong Kafka ordering warranties when operating in the
collapsedmode with automatic exclusion of messages virtually marked as consumed.

*Example distribution of messages in between two virtual partitions.
Consumers Synchronization
When using Virtual Partitions in Karafka, multiple consumers will concurrently operate on data from the same topic partition. This can lead to potential data races and inconsistencies if not properly managed. To help with this, Karafka provides a mechanism to synchronize access among these consumers using the #synchronize method.
Karafka's #synchronize method uses a mutex to guarantee that the code inside its block will not face race conditions with other consumers. This ensures that only one consumer can execute the synchronized block of code at a time, thus providing a way to perform operations that should be atomic safely.
class EventsConsumer < ApplicationConsumer
def consume
sum = messages.payloads.map { |data| data.fetch(:count) }.sum
# Make sure that the counter is not in a race-condition with other
# consumers from same partition
synchronize do
counts = Cache.fetch(topic, partition) || 0
Cache.set(topic, partition, counts + sum)
end
end
end
Thread Management and Consumers Assignment
Karafka assigns each virtual partition a dedicated, long-lived consumer instance. This design ensures that messages within a virtual partition are processed consistently and independently from other partitions and that those consumers can implement things like accumulators and buffers. However, there is no fixed relationship between threads and consumer instances, allowing for flexible and efficient use of resources.
One of Karafka's key strengths is the adaptability of its worker threads. Any available thread can run any consumer instance, a dynamic allocation that ensures efficient utilization of all available resources. This flexibility prevents idle threads, maximizing throughput. The dynamic nature of thread assignment also means that different threads can seamlessly pick up the work of a particular virtual partition between batches, giving users a sense of control.
The assignment of messages to virtual partitions is consistent and based on a partitioner key. This key ensures that messages with the same key are consistently routed to the same virtual partition. Consequently, the same consumer instance processes these messages, maintaining the order and integrity required for reliable multi-batch message handling.
Karafka's architecture involves maintaining a map of consumer instances mapped to virtual partitions. These instances are managed dynamically and persist as long as the partition assignment is active. This persistence ensures stability and consistency in message processing, even as threads are reassigned between batches.
By decoupling thread assignment from consumer instances and ensuring dedicated, long-lived consumer instances per virtual partition, Karafka achieves a balance between flexibility and consistency. This design allows for efficient resource utilization, consistent message processing, and the ability to handle high-throughput scenarios effectively.

*This example illustrates the flow of message distribution through virtualization and scheduling until the worker threads jobs pickup for processing.
Reducer Replacement
In Karafka, the default reducer for Virtual Partitions is a method designed to distribute messages across virtual partitions. It does this by using a simple mathematical operation on the sum of the stringified version of the virtual key. While this method is generally effective, it may not be fully optimal under certain configurations. For example, it could consistently use only 60% or less of the available threads, leading to inefficiencies and underutilization of resources.
Karafka allows you to replace the default reducer with a custom one to address this. This can be particularly useful when implementing a more sophisticated partitioning strategy to enhance parallelization and balance the load more effectively. By customizing the reducer, you can ensure that all available threads are optimally utilized, leading to better performance and throughput for your application.
Implementing a Custom Reducer
A custom reducer must respond to the #call method, accepting a virtual key and returning an integer representing the assigned virtual partition. Below is an example of how to implement and configure a custom reducer:
# Custom reducer that uses a different strategy for distributing messages
class CustomReducer
def call(virtual_key)
concurrency = Karafka::App.config.concurrency
# Implement your custom logic here
# For example, you could use a hash function or any other distribution logic
Digest::MD5.hexdigest(virtual_key.to_s).to_i(16) % concurrency
end
end
# Configure the custom reducer in your Karafka application
class KarafkaApp < Karafka::App
setup do |config|
config.concurrency = 10
end
routes.draw do
topic :orders_states do
consumer OrdersStatesConsumer
# Use the custom reducer for virtual partitions
virtual_partitions(
partitioner: ->(message) { message.headers['order_id'] },
reducer: CustomReducer.new
)
end
end
end
This class defines a custom reducer with a #call method. The method uses an MD5 hash function to compute an integer based on the virtual key, ensuring a more distributed and potentially collision-resistant assignment of messages to virtual partitions.
Benefits of Using a Custom Reducer
-
Enhanced Distribution: Custom reducers allow for more complex and nuanced distribution strategies, which can better balance the load and reduce hotspots.
-
Adaptability: Different applications have different needs. A custom reducer can be tailored to specific requirements, whether that's handling unique data distributions, optimizing for specific performance characteristics, or integrating with other systems.
-
Scalability: By refining how messages are distributed across virtual partitions, custom reducers can help ensure that processing scales efficiently as the volume of messages increases.
When to Use a Custom Reducer
-
Complex Workflows: If your application has complex workflows that require fine-tuned distribution of messages.
-
Performance Optimization: When you need to optimize the performance and efficiency of message processing.
-
Specialized Requirements: If your data and processing requirements are unique and cannot be effectively managed by the default reducer.
Monitoring
Karafka default monitor and the Web UI dashboard work with virtual partitions out of the box. No changes are needed. Virtual batches are reported as they would be regular batches.
Shutdown and Revocation Handlers
Both #shutdown and #revoked handlers work the same as within regular consumers.
For each virtual consumer instance, both are executed when shutdown or revocation occurs. Please keep in mind that those are executed for each instance. That is, upon shutdown, if you used ten threads and they were all used with virtual partitions, the #shutdown method will be called ten times. Once per each virtual consumer instance that was in use.

Virtual Partitions vs. Increasing Number of Partitions
When building a scalable Kafka consumer application with Karafka, you'll likely be faced with a decision: Should you increase the number of physical partitions or leverage the power of Virtual Partitions? Both strategies aim to parallelize work to boost processing speed but offer different advantages and considerations. This section delves into the differences between these two methods and provides insights to help you make an informed decision.
Conceptual Differences
-
Physical Partitions: These are actual divisions of a Kafka topic. Messages within a topic are divided amongst these partitions. Consumers can read from multiple partitions concurrently, but a single partition's data can only be read by one consumer at a time.
-
Virtual Partitions: VPs are a feature provided by Karafka. They allow for further parallelization of work within a physical partition. Using VPs, multiple workers can simultaneously process different chunks of data from the same physical partition.
Work Distribution
-
Physical Partitions: Increasing the number of partitions allows more consumer processes to read data concurrently. However, you're constrained by the fact that only one consumer can read from a partition at a given time.
-
Virtual Partitions: VPs enable multiple workers to process data from a single partition. This is useful when data within a partition can be divided into independent logical chunks. The result is better work distribution and utilization of worker threads, especially in heavy-load scenarios.
Polling Characteristics
-
Physical Partitions: Efficient polling requires a consistent distribution of messages across all partitions. Challenges arise when there's uneven message distribution or when polled batches do not include data from multiple partitions, leading to some consumers being under-utilized.
-
Virtual Partitions: VPs compensate for uneven polling. Even if polling fetches data mainly from one partition, VPs ensure that multiple workers distribute and process the data. This mitigates the impact of uneven distribution.
Virtual partitions in a Kafka context serve as a mechanism to enhance parallel processing without directly influencing the underlying partition-polling mechanism. When consumers poll data from Kafka, they rely on the actual partitions. The introduction of virtual partitions keeps this fundamental process the same. Instead, the true benefit of virtual partitions arises from the ability to distribute and parallelize work across multiple consumer threads or instances, allowing for improved scalability and performance without necessitating changes to the core Kafka infrastructure or the way data is polled.
Comparative Scenario
Consider a single-topic scenario where IO is involved, and data can be further partitioned into Virtual Partitions:
-
Scenario #1: 200 partitions with 20 Karafka consumer processes and a concurrency of 10 results in 200 total worker threads.
-
Scenario #2: 100 partitions, 20 Karafka consumer processes with a concurrency of 10, and Virtual Partitions enabled, also results in 200 total worker threads.
In both scenarios, the number of worker threads remains the same. However, with VPs (Scenario #2), Karafka will perform better due to a more effective distribution of work among worker threads. This enhanced performance is especially pronounced when messages are uneven across topic partitions or batches polled from Kafka contain data from a few or even one topic partition.
Conclusion
While increasing the number of Kafka partitions offers a more native way to parallelize data processing, VPs provide a more efficient, flexible, and Karafka-optimized approach. Your choice should be based on your application's specific needs, the nature of your data, and the load you anticipate. However, when aiming for maximum throughput and efficient resource utilization, especially under heavy load, Virtual Partitions together with well-partitioned topics are a more favorable choice.
Scalability Constraints
-
Physical Partitions: There's a limit to how many physical partitions you can have, and re-partitioning a topic can be a complex task. Also, there's overhead associated with managing more partitions.
-
Virtual Partitions: VPs provide scalability within the confines of existing physical partitions. They don't add to the management overhead of Kafka and offer a more flexible way to scale processing power without altering the topic's physical partitioning.
Customizing the partitioning engine / Load aware partitioning
There are scenarios upon which you can differentiate your partitioning strategy based on the number of received messages per topic partition. It is impossible to set it easily using the default partitioning API, as this partitioner accepts single messages. However, Pro users can use the Karafka::Pro::Processing::Partitioner as a base for a custom partitioner that can achieve something like this.
One great example of this is a scenario where you may want to partition messages in such a way as to always end up with at most 5 000 messages in a single Virtual Partition.
# This is a whole process partitioner, not a per topic one
class CustomPartitioner < Karafka::Pro::Processing::Partitioner
def call(topic_name, messages, coordinator, &block)
# Apply the "special" strategy for this special topic unless VPs were collapsed
# In the case of collapse you want to process with the default flow.
if topic_name == 'balanced_topic' && !coordinator.collapsed?
balanced_strategy(messages, &block)
else
# Apply standard behaviours to other topics
super
end
end
private
# Make sure you end up with virtual partitions that always have at most 5 000 messages and create
# as few partitions as possible
def balanced_strategy(messages)
messages.each_slice(5_000).with_index do |slice, index|
yield(index, slice)
end
end
end
Once you create your custom partitioner, you need to overwrite the default one in your configuration:
class KarafkaApp < Karafka::App
setup do |config|
config.internal.processing.partitioner_class = CustomPartitioner
end
end
When used that way, your balanced_topic will not use the per topic partitioner nor max_partitions. This topic data distribution will solely rely on your balanced_strategy logic.
Example Use Cases
Here are some use cases from various industries where Karafka's virtual partition feature can be beneficial:
-
Adtech: An ad-tech company may need to process a large number of ad impressions or clicks coming in from a single Kafka topic partition. By using virtual partitions to parallelize the processing of these events, they can improve the efficiency and speed of their ad-serving system, which often involves database operations.
-
E-commerce: In the e-commerce industry, processing many product orders or inventory updates can be IO bound. By using virtual partitions to parallelize the processing of these events, e-commerce companies can improve the efficiency and speed of their systems, enabling them to serve more customers and update inventory more quickly.
-
Logistics: A logistics company may need to process a large volume of shipment or tracking data coming in from a single Kafka topic partition. By using virtual partitions to parallelize the processing of this data, they can improve the efficiency of their logistics operations and reduce delivery times.
-
Healthcare: In healthcare, processing a large volume of patient data can be IO bound, particularly when interacting with electronic health records (EHR) or other databases. By using virtual partitions to parallelize the processing of patient data coming from a single Kafka topic partition, healthcare organizations can improve the efficiency of their data analysis and provide more timely care to patients.
-
Social Media: Social media platforms often need to process many user interactions, such as likes, comments, and shares, coming in from a single Kafka topic partition. By using virtual partitions to parallelize the processing of these events, they can improve the responsiveness of their platform and enhance the user experience.
Overall, virtual partitions can be beneficial in any industry where large volumes of data need to be processed quickly and efficiently, particularly when processing is IO bound. By parallelizing the processing of data from a single Kafka topic partition, organizations can improve the performance and scalability of their systems, enabling them to make more informed decisions and deliver better results.
Last modified: 2025-05-17 10:43:50