FAQ
- Does Karafka require Ruby on Rails?
- Why there used to be an ApplicationController mentioned in the Wiki and some articles?
- Does Karafka require Redis and/or Sidekiq to work?
- Could an HTTP controller also consume a fetched message through the Karafka router?
- Does Karafka require a separate process running?
- Can I start Karafka process with only particular consumer groups running for given topics?
- Can I use
#seekto start processing topics partition from a certain point? - Why Karafka does not pre-initializes consumers prior to first message from a given topic being received?
- Does Karafka restart dead PG connections?
- Does Karafka require gems to be thread-safe?
- When Karafka is loaded via railtie in test env, SimpleCov does not track code changes
- Can I use Thread.current to store data in between batches?
- Why Karafka process does not pick up newly created topics until restarted?
- Why is Karafka not doing work in parallel when I started two processes?
- Can I remove a topic while the Karafka server is running?
- What is a forceful Karafka stop?
- Can I use AWS MSK Serverless with IAM authentication?
- Why can't I connect to Kafka from another Docker container?
- How can I configure multiple bootstrap servers?
- Why, when using
cooperative-stickyrebalance strategy, all topics get revoked on rebalance? - What will happen with uncommitted offsets during a rebalance?
- Can I use Karafka with Ruby on Rails as a part of an internal gem?
- Can I skip messages on errors?
- What does static consumer fenced by other consumer with same group.instance.id mean?
- Why, in the Long-Running Jobs case,
#revokedis executed even if#consumedid not run because of revocation? - Why am I seeing
Rdkafka::RdkafkaError (Local: Timed out (timed_out)error when producing larger quantities of messages? - Do I need to use
#revoked?when not using Long-Running jobs? - Can I consume from more than one Kafka cluster at the same time?
- Why Karafka uses
karafka-rdkafkainstead ofrdkafkadirectly? - Why am I seeing an
Implement this in a subclasserror? - What is Karafka
client_idused for? - How can I increase Kafka and Karafka max message size?
- Why do DLQ messages in my system keep disappearing?
- What is the optimal number of threads to use?
- Can I use several producers with different configurations with Karafka?
- What is the Unsupported value "SSL" for configuration property "security.protocol": OpenSSL not available at build time?
- Can Karafka ask Kafka to list available topics?
- Why Karafka prints some of the logs with a time delay?
- Why is increasing
concurrencynot helping upon a sudden burst of messages? - Why am I seeing a "needs to be consistent namespacing style" error?
- Why, despite setting
initial_offsettoearliest, Karafka is not picking up messages from the beginning? - Should I TSTP, wait a while, then send TERM or set a longer
shutdown_timeoutand only send a TERM signal? - Why am I getting
error:0A000086:SSL routines::certificate verify failedafter upgrading Karafka? - Why am I seeing a
karafka_adminconsumer group with a constant lag present? - Can I consume the same topic independently using two consumers within the same application?
- Why am I seeing Broker failed to validate record (invalid_record) error?
- How can I make polling faster?
- Can I dynamically add consumer groups and topics to a running Karafka process?
- Can a consumer instance be called multiple times from multiple threads?
- Can multiple threads reuse a single consumer instance?
- What does
Broker: Unknown topic or partitionerror mean? - Why some of consumer subscriptions are not visible in the Web UI?
- Is there a way to run Karafka in a producer-only mode?
- Why am I getting the
can't alloc thread (ThreadError)error from the producer? - Can I create all the topics needed by the Web UI manually?
- Can I consume messages from a Rake task?
- Do you provide an upgrade support when upgrading from EOL versions?
- Why there are so many Karafka strategies in the codebase?
- Why am I having problems running Karafka and Karafka Web with remote Kafka?
- Why after moving from Racecar to Karafka, my Confluent Datadog integration stopped working?
- Why am I getting
env: can't execute 'bash'when installing Karafka in an Alpine Docker? - Can I intercept WaterDrop messages in tests?
- Does Karafka Expiring Messages remove messages from Kafka?
- Can you actively ping the cluster from Karafka to check the cluster availability?
- How do I specify Karafka's environment?
- How can I configure WaterDrop with SCRAM?
- Why am I getting a
Local: Broker transport failure (transport)error with theDisconnectedinfo? - Why am I getting a
All broker connections are down (all_brokers_down)error together with theDisconnectedinfo? - What is the difference between
partition_keyandkeyin the WaterDrop gem? - How can I set up WaterDrop with SCRAM?
- Is there a way to mark messages as consumed in bulk?
- How can I consume all the messages from a Kafka topic without a consumer process?
- What does
Broker: Invalid message (invalid_msg)error mean? - Is there an option in Karafka to re-consume all the messages from a topic even though all were already consumed?
- How can I make sure, that
Karafka.producerdoes not block/delay my processing? - Can
at_exitbe used to close the WaterDrop producer? - Why, when DLQ is used with
max_retriesset to0, Karafka also applies a back-off? - Can I use
rdkafkaandkarafka-rdkafkatogether in the same project? - Does using consumer
#seekresets the committed offset? - Is it recommended to use public consumer methods from outside the consumer?
- Why do I see
SASL authentication errorafter AWS MSK finished theHeal clusteroperation? - Why Karafka and WaterDrop are behaving differently than
rdkafka? - Why am I seeing
Inconsistent group protocolin Karafka logs? - What is the difference between WaterDrop's
max_payload_sizeand librdkafka'smessage.max.bytes? - What are consumer groups used for?
- Why am I getting the
all topic names within a single consumer group must be uniqueerror? - Why am I getting
WaterDrop::Errors::ProduceError, and how can I know the underlying cause? - Can extra information be added to the messages dispatched to the DLQ?
- Why does WaterDrop hang when I attempt to close it?
- Why Karafka commits offsets on rebalances and librdkafka does not?
- What is Karafka's assignment strategy for topics and partitions?
- Why can't I see the assignment strategy/protocol for some Karafka consumer groups?
- What can be done to log why the
produce_synchas failed? - Can I password-protect Karafka Web UI?
- Can I use a Karafka producer without setting up a consumer?
- What will happen when a message is dispatched to a dead letter queue topic that does not exist?
- Why do Karafka reports lag when processes are not overloaded and consume data in real-time?
- Does Kafka guarantee message processing orders within a single partition for single or multiple topics? And does this mean Kafka topics consumption run on a single thread?
- Why can I produce messages to my local Kafka docker instance but cannot consume?
- What is the release schedule for Karafka and its components?
- Can I pass custom parameters during consumer initialization?
- Where can I find producer idempotence settings?
- How can I control or limit the number of PostgreSQL database connections when using Karafka?
- Why is my Karafka application consuming more memory than expected?
- How can I optimize memory usage in Karafka?
- Why am I getting
No such file or directory - ps (Errno::ENOENT)from the Web UI? - Can I retrieve all records produced in a single topic using Karafka?
- How can I get the total number of messages in a topic?
- Why am I getting
Broker: Group authorization failed (group_authorization_failed)when using Admin API or the Web UI? - Why am I getting an
ArgumentError: undefined class/module YAML::Syckwhen trying to installkarafka-license? - Are Virtual Partitions effective in case of not having IO or not having a lot of data?
- Is the "one process per one topic partition" recommendation in Kafka also applicable to Karafka?
- Does running
#mark_as_consumedincrease the processing time? - Does it make sense to have multiple worker threads when operating on one partition in Karafka?
- Why don't Virtual Partitions provide me with any performance benefits?
- What are Long Running Jobs in Kafka and Karafka, and when should I consider using them?
- What can I do to optimize the latency in Karafka?
- What is the maximum recommended concurrency value for Karafka?
- Are there concerns about having unused worker threads for a Karafka consumer process?
- How can you effectively scale Karafka during busy periods?
- What are the benefits of using Virtual Partitions (VPs) in Karafka?
- What's the difference between increasing topic partition count and using VPs in terms of concurrency?
- How do VPs compare to multiple subscription groups regarding performance?
- What is the principle of strong ordering in Kafka and its implications?
- Why do I see
Rdkafka::Config::ClientCreationErrorwhen changing thepartition.assignment.strategy? - Is it recommended to add the
waterdropgem to the Gemfile, or justkarafkaandkarafka-testing? - Can I use
Karafka.producerto produce messages that will then be consumed by ActiveJob jobs? - Why am I getting the
Broker: Policy violation (policy_violation)error? - Why am I getting a
Error querying watermark offsets for partition 0 of karafka_consumers_stateserror? - Why Karafka is consuming the same message multiple times?
- Why do Karafka Web UI topics contain binary/Unicode data instead of text?
- Can I use same Karafka Web UI topics for multiple environments like production and staging?
- Does Karafka plan to submit metrics via a supported Datadog integration, ensuring the metrics aren't considered custom metrics?
- How can I make Karafka not retry processing, and what are the implications?
- We faced downtime due to a failure in updating the SSL certs. How can we retrieve messages that were sent during this downtime?
- How can the retention policy of Kafka affect the data sent during the downtime?
- Is it possible to fetch messages per topic based on a specific time period in Karafka?
- Where can I find details on troubleshooting and debugging for Karafka?
- Does the open-source (OSS) version of Karafka offer time-based offset lookup features?
- I see a "JoinGroup error: Broker: Invalid session timeout" error. What does this mean, and how can I resolve it?
- The "Producer Network Latency" metric in DD seems too high. Is there something wrong with it?
- What is the purpose of the
karafka_consumers_reportstopic? - Can I use
Karafka.producerfrom within ActiveJob jobs running in the karafka server? - Do you recommend using the singleton producer in Karafka for all apps/consumers/jobs in a system?
- Is it acceptable to declare short-living producers in each app/jobs as needed?
- What are the consequences if you call a
#produce_asyncand immediately close the producer afterward? - Is it problematic if a developer creates a new producer, calls
#produce_async, and then closes the producer whenever they need to send a message? - Could the async process remain open somewhere, even after the producer has been closed?
- Could a single producer be saturated, and if so, what kind of max rate of message production would be the limit?
- How does the batching process in WaterDrop works?
- Can you control the batching process in WaterDrop?
- Is it possible to exclude
karafka-webrelated reporting counts from the web UI dashboard? - Can I log errors in Karafka with topic, partition, and other consumer details?
- Why did our Kafka consumer start from the beginning after a 2-week downtime, but resumed correctly after a brief stop and restart?
- Why am I experiencing a load error when using Karafka with Ruby 2.7, and how can I fix it?
- Why am I getting
+[NSCharacterSet initialize] may have been in progress in another thread when fork()error when forking on macOS? - How does Karafka handle messages with undefined topics, and can they be routed to a default consumer?
- What happens if an error occurs while consuming a message in Karafka? Will the message be marked as not consumed and automatically retried?
- What does setting the
initial_offsettoearliestmean in Karafka? Does it mean the consumer starts consuming from the earliest message that has not been consumed yet? - Why is the "Dead" tab in Web UI empty in my Multi App setup?
- What causes a "Broker: Policy violation (policy_violation)" error when using Karafka, and how can I resolve it?
- Why do I see hundreds of repeat exceptions with
pause_with_exponential_backoffenabled? - Does Karafka store the Kafka server address anywhere, and are any extra steps required to make it work after changing the server IP/hostname?
- What should I do if I encounter a loading issue with Karafka after upgrading Bundler to version
2.3.22? - Is there a good way to quiet down
bundle exec karafka serverextensive logging in development? - How can I namespace messages for producing in Karafka?
- Why am I getting the
all topic names within a single consumer group must be uniqueerror when changing the location of the boot file usingKARAFKA_BOOT_FILE? - Why Is Kafka Using Only 7 Out of 12 Partitions Despite Specific Settings?
- Why does the Dead Letter Queue (DLQ) use the default deserializer instead of the one specified for the original topic in Karafka?
- What should I consider when manually dispatching messages to the DLQ in Karafka?
- How can I ensure that my Karafka consumers process data in parallel?
- How should I handle the migration to different consumer groups for parallel processing?
- What are the best practices for setting up consumer groups in Karafka for optimal parallel processing?
- How can I set up custom, per-message tracing in Karafka?
- When Karafka reaches
max.poll.interval.mstime and the consumer is removed from the group, does this mean my code stops executing? - Which component is responsible for committing the offset after consuming? Is it the listener or the worker?
- Can the
on_idleandhandle_idlemethods be changed for a specific consumer? - Is Multiplexing an alternative to running multiple Karafka processes but using Threads?
- Is it possible to get watermark offsets from inside a consumer class without using Admin?
- Why are message and batch numbers increasing even though I haven't sent any messages?
- What does
config.ui.sessions.secretdo for the Karafka Web UI? Do we need it if we are using our authentication layer? - Is there middleware for consuming messages similar to the middleware for producing messages?
- Can we change the name of Karafka's internal topic for the Web UI?
- Is there a way to control which pages we show in the Karafka Web UI Explorer to prevent exposing PII data?
- What does the
strict_topics_namespacingconfiguration setting control? - Does librdkafka queue messages when using Waterdrop's
#produce_syncmethod? - How reliable is the Waterdrop async produce? Will messages be recovered if the Karafka process dies before producing the message?
- Will WaterDrop start dropping messages upon librdkafka buffer overflow?
- How can I handle
dispatch_to_dlqmethod errors when using the same consumer for a topic and its DLQ? - What should I do if I encounter the
Broker: Not enough in-sync replicaserror? - Is there any way to measure message sizes post-compression in Waterdrop?
- What happens to a topic partition when a message fails, and the exponential backoff strategy is applied? Is the partition paused during the retry period?
- How can Virtual Partitions help with handling increased consumer lag in Karafka?
- Is scaling more processes a viable alternative to using Virtual Partitions?
- What is the optimal strategy for scaling in Karafka to handle high consumer lag?
- How does Karafka behave under heavy lag, and what should be considered in configuration?
- Is there an undo of Quiet for a consumer to get it consuming again?
- Can two Karafka server processes with the same group_id consume messages from the same partition in parallel?
- What are some good default settings for sending large "trace" batches of messages for load testing?
- Is it worth pursuing transactions for a low throughput but high-importance topic?
- Does the Waterdrop producer retry to deliver messages after errors such as
librdkafka.errorandlibrdkafka.dispatch_error, or are the messages lost? - In a Rails request, can I publish a message asynchronously, continue the request, and block at the end to wait for the publish to finish?
- Why am I getting the error: "No provider for SASL mechanism GSSAPI: recompile librdkafka with libsasl2 or openssl support"?
- How can I check if
librdkafkawas compiled with SSL and SASL support in Karafka? - Why does
librdkafkalose SSL and SASL support in my multi-stage Docker build? - Why do I see WaterDrop error events but no raised exceptions in sync producer?
- When does EOF (End of File) handling occur in Karafka, and how does it work?
- How can I determine if a message is a retry or a new message?
- Why does Karafka Web UI stop working after upgrading the Ruby slim/alpine Docker images?
- Why does installing
karafka-webtake exceptionally long? - Why does Karafka routing accept consumer classes rather than instances?
- Why does Karafka define routing separate from consumer classes, unlike Sidekiq or Racecar?
- What's the difference between
keyandpartition_keyin WaterDrop? - Can I disable logging for Karafka Web UI consumer operations while keeping it for my application consumers?
- How can I distinguish between sync and async producer errors in the
error.occurrednotification?
Does Karafka require Ruby on Rails?
No. Karafka is a fully independent framework that can operate in a standalone mode. It can be easily integrated with any Ruby-based application, including those written with Ruby on Rails. Please follow the Integrating with Ruby on Rails and other frameworks Wiki section.
Why there used to be an ApplicationController mentioned in the Wiki and some articles?
You can name the main application consumer with any name. You can even call it ApplicationController or anything else you want. Karafka will sort that out, as long as your root application consumer inherits from the Karafka::BaseConsumer. It's not related to Ruby on Rails controllers. Karafka framework used to use the *Controller naming convention up until Karafka 1.2 where it was changed because many people had problems with name collisions.
Does Karafka require Redis and/or Sidekiq to work?
No. Karafka is a standalone framework, with an additional process that will be used to consume Kafka messages.
Could an HTTP controller also consume a fetched message through the Karafka router?
No. Kafka messages can be consumed only using Karafka consumers. You cannot use your Ruby on Rails HTTP consumers to consume Kafka messages, as Karafka is not an HTTP Kafka proxy. Karafka uses Kafka API for messages consumption.
Does Karafka require a separate process running?
No, however, it is recommended. By default, Karafka requires a separate process (Karafka server) to consume and process messages. You can read about it in the Consuming messages section of the Wiki.
Karafka can also be embedded within another process so you do not need to run a separate process. You can read about it here.
Can I start Karafka process with only particular consumer groups running for given topics?
Yes. Karafka allows you to listen with a single consumer group on multiple topics, which means that you can tune up the number of threads that Karafka server runs, accordingly to your needs. You can also run multiple Karafka instances, specifying consumer groups that should be running per each process using the --include-consumer-groups server flag as follows:
bundle exec karafka server --include-consumer-groups group_name1 group_name3
You can also exclude particular groups the same way:
bundle exec karafka server --exclude-consumer-groups group_name1 group_name3
Visit the CLI section of our docs to learn more about how to limit the scope of things to which the server subscribes.
Can I use #seek to start processing topics partition from a certain point?
Karafka has a #seek consumer method that can be used to do that.
Why Karafka does not pre-initializes consumers prior to first message from a given topic being received?
Because Karafka does not have knowledge about the whole topology of a given Kafka cluster. We work on what we receive dynamically building consumers when it is required.
Does Karafka restart dead PG connections?
Karafka, starting from 2.0.16 will automatically release no longer used ActiveRecord connections. They should be handled and reconnected by the Rails connection reaper. You can implement custom logic to reconnect them yourself if needed beyond the reaping frequency. More details on that can be found here(https://karafka.io/docs/Active-Record-Connections-Management/#dealing-with-dead-database-connections).
Does Karafka require gems to be thread-safe?
Yes. Karafka uses multiple threads to process data, similar to how Puma or Sidekiq does it. The same rules apply.
When Karafka is loaded via a railtie in test env, SimpleCov does not track code changes
Karafka hooks with railtie to load karafka.rb. Simplecov needs to be required before any code is loaded.
Can I use Thread.current to store data between batches?
No. The first available thread will pick up work from the queue to better distribute work. This means that you should not use Thread.current for any type of data storage.
Why Karafka process does not pick up newly created topics until restarted?
- Karafka in the
developmentmode will refresh cluster metadata every 5 seconds. It means that it will detect topic changes fairly fast. - Karafka in
productionwill refresh cluster metadata every 5 minutes. It is recommended to create production topics before running consumers.
The frequency of cluster metadata refreshes can be changed via topic.metadata.refresh.interval.ms in the kafka config section.
Why is Karafka not doing work in parallel when I started two processes?
Please make sure your topic contains more than one partition. Only then Karafka can distribute the work to more processes. Keep in mind, that all the topics create automatically with the first message sent will always contain only one partition. Use the Admin API to create topics with more partitions.
Can I remove a topic while the Karafka server is running?
Not recommended. You may encounter the following errors if you decide to do so:
ERROR -- : librdkafka internal error occurred: Local: Unknown partition (unknown_partition)
ERROR -- :
INFO -- : rdkafka: [thrd:main]: Topic extractor partition count changed from 1 to 0
ERROR -- : librdkafka internal error occurred: Broker: Unknown topic or partition (unknown_topic_or_part)
It is recommended to stop Karafka server instances and then remove and recreate the topic.
What is a forceful Karafka stop?
When you attempt to stop Karafka, you may notice the following information in your logs:
Received SIGINT system signal
Stopping Karafka server
Forceful Karafka server stop
When you ask Karafka to stop, it will wait for all the currently running jobs to finish. The shutdown_timeout configuration setting limits the time it waits. After this time passes and any work in listeners or workers are still being performed, Karafka will attempt to forcefully close itself, stopping all the work in the middle. If you see it happen, it means you need to either:
- extend the
shutdown_timeoutvalue to match your processing patterns - debug your code to check what is causing the extensive processing beyond the
shutdown_timeout
In any case, it is not recommended to ignore this if it happens frequently.
Can I use AWS MSK Serverless with IAM authentication?
No. IAM is a custom authentication engine that is not a part of the Kafka protocol and is not supported by librdkafka.
Karafka supports following methods that work with AWS MSK:
Why can't I connect to Kafka from another Docker container?
You need to modify the docker-compose.yml KAFKA_ADVERTISED_HOST_NAME value. You can read more about it here.
How can I configure multiple bootstrap servers?
You need to define them comma-separated under kafka bootstrap.servers configuration key:
class KarafkaApp < Karafka::App
setup do |config|
config.client_id = 'my_application'
# This value needs to be a string string with comma separated servers
config.kafka = {
'bootstrap.servers': 'server1.address:9092, server2.address:9092'
}
end
end
Why, when using cooperative-sticky rebalance strategy, all topics get revoked on rebalance?
This behavior can occur if you are using blocking mark_as_consumed! method and the offsets commit happens during rebalance. When using cooperative-sticky we recommend using mark_as_consumed instead.
What will happen with uncommitted offsets during a rebalance?
When using mark_as_consumed, offsets are stored locally and periodically flushed to Kafka asynchronously.
Upon rebalance, all uncommitted offsets will be committed before a given partition is re-assigned.
Can I use Karafka with Ruby on Rails as a part of an internal gem?
Karafka 2.x has Rails auto-detection, and it is loaded early, so some components may be available later, e.g., when ApplicationConsumer inherits from BaseConsumer that is provided by the separate gem that needs an initializer.
Moreover, despite the same code base, some processes (rails s, rails db:migrate, sidekiq s) may not need to know about karafka, and there is no need to load it.
The problem is presented in this example app PR.
To mitigate this, you can create an empty karafka bootfile. With a file structure like this:
+-- karafka_root_dir
| +-- karafka.rb # default bootfile (empty file)
| +-- karafka_app.rb # real bootfile with Karafka::App definition and other stuff
| +-- ...
It is possible to postpone the definition of the Karafka app and do it manually whenever & wherever the user wants (karafka_app.rb could be loaded for example, in some initializer).
# karafka_app.rb
class KarafkaApp < Karafka::App
setup do |config|
config.client_id = 'my_application'
...
end
end
# config/initializers/karafka_init.rb
require 'karafka_root_dir/karafka_app'
Still not a perfect solution because karafka gem is still loaded.
This description was prepared by AleksanderSzyszka.
Can I skip messages on errors?
Karafka Pro can skip messages non-recoverable upon errors as a part of the Enhanced Dead Letter Queue feature. You can read about this ability here.
What does static consumer fenced by other consumer with same group.instance.id mean?
If you see such messages in your logs:
Fatal error: Broker: Static consumer fenced by other consumer with same group.instance.id
It can mean two things:
- You are using the Karafka version before
2.0.20. If that is the case, please upgrade. - Your
group.instance.idis not unique within your consumer group. You must always ensure that the value you assign togroup.instance.idis unique within the whole consumer group, not unique per process or machine.
Why, in the Long-Running Jobs case, #revoked is executed even if #consume did not run because of revocation?
The #revoked will be executed even though the #consume did not run upon revocation because #revoked can be used to teardown resources initialized prop to #consume. For example, for things initialized in a custom initialize method.
Why am I seeing Rdkafka::RdkafkaError (Local: Timed out (timed_out) error when producing larger quantities of messages?
If you are seeing following error:
Rdkafka::RdkafkaError (Local: Timed out (timed_out)
It may mean one of four things:
- High probability: Broker can't keep up with the produce rate.
- High probability if you use
partition_key: Broker is temporarily overloaded and cannot return info about the topic structure. A retry mechanism has been implemented in WaterDrop2.4.4to mitigate this. - Low probability: Slow network connection.
- Low probability: SSL configuration issue. In this case, no messages would reach the broker.
WaterDrop dispatches messages to librdkafka and librdkafka constructs message sets out of it. By default, it does it every five milliseconds. If you are producing messages fast, it may become inefficient for Kafka because it has to deal with separate incoming message sets and needs to keep up. Please consider increasing the queue.buffering.max.ms, so the batches are constructed less often and are bigger.
Additionally, you may also:
- Dispatch smaller batches using
#produce_many_sync.Effectively it will throttle the process that way. - Establish a limit on how many messages you want to dispatch at once. This will prevent you from scenarios where you accidentally flush too much. If you dispatch based on an array of samples, you can do it that way:
data_to_dispatch.each_slice(2_00) do |data_slice|
Karafka.producer.produce_many_sync(data_slice)
end
Do I need to use #revoked? when not using Long-Running jobs?
In a stable system, no. The Karafka default offset management strategy should be more than enough. It ensures that after batch processing as well as upon rebalances, before partition reassignment, all the offsets are committed.
You can read about Karafka's revocation/rebalance behaviors here and here.
Can I consume from more than one Kafka cluster simultaneously?
Yes. Karafka allows you to redefine kafka settings on a per-topic basis. You can create separate consumer groups to consume from separate clusters:
class KarafkaApp < Karafka::App
setup do |config|
# ...
end
routes.draw do
consumer_group :group_name do
topic :example do
kafka('bootstrap.servers': 'cluster1:9092')
consumer ExampleConsumer
end
topic :example2 do
kafka('bootstrap.servers': 'cluster1:9092')
consumer ExampleConsumer2
end
end
consumer_group :group_name2 do
topic :example3 do
kafka('bootstrap.servers': 'cluster2:9092')
consumer Example2Consumer3
end
end
end
end
Please note that if your cluster configuration is complex, you may want to use set it up in the root scope and then alter it on a per-topic basis:
class KarafkaApp < Karafka::App
setup do |config|
config.kafka = {
'enable.ssl.certificate.verification': kafka_config.ssl_verify_hostname,
'security.protocol': kafka_config.security_protocol,
'statistics.interval.ms': 1_000,
'ssl.key.password': kafka_config.auth[:cert_key_password],
'ssl.key.pem': Base64.decode64(kafka_config.auth[:base64_cert_key_pem]),
'ssl.certificate.pem': Base64.decode64(kafka_config.auth[:base64_client_cert_pem]),
'ssl.ca.pem': Base64.decode64(kafka_config.auth[:base64_ca_cert_pem])
}
end
end
routes.draw do
consumer_group :related_reviews do
topic :reviews do
target.kafka[:'bootstrap.servers'] = CLUSTERS[:related_reviews][:brokers]&.join(',')
consumer ReviewsConsumer
end
end
consumer_group :related_products do
topic :products do
target.kafka[:'bootstrap.servers'] = CLUSTERS[:related_products][:brokers]&.join(',')
consumer RelatedProductsConsumer
end
end
end
end
Also, please remember that those settings apply to consumers only. Karafka#producer will always produce to the default cluster using the default settings. This may be confusing when working with things like Dead Letter Queue as the producer will produce the default cluster DLQ topic despite the origin cluster. You can read more about that behavior here.
Why Karafka uses karafka-rdkafka instead of rdkafka directly?
We release our version of the rdkafka gem to ensure it meets our quality and stability standards. That way, we ensure that unexpected rdkafka releases will not break the Karafka ecosystem.
Why am I seeing an Implement this in a subclass error?
[bc01b9e1535f] Consume job for ExampleConsumer on my_topic started
Worker processing failed due to an error: Implement this in a subclass
This error occurs when you have defined your consumer but without a #consume method:
BAD:
class ExampleConsumer < Karafka::BaseConsumer
# No consumption method
end
GOOD:
class ExampleConsumer < Karafka::BaseConsumer
def consume
messages.each do |message|
puts message.payload
end
end
end
What is Karafka client_id used for?
Karafka client_id is, by default, used for populating kafka client.id value.
kafka client.id is a string passed to the server when making requests. This is to track the source of requests beyond just IP/port by allowing a logical application name to be included in server-side request logging.
How can I increase Kafka and Karafka max message size?
To make Kafka accept messages bigger than 1MB, you must change both Kafka and Karafka configurations.
To increase the maximum accepted payload size in Kafka, you can adjust the message.max.bytes and replica.fetch.max.bytes configuration parameters in the server.properties file. These parameters controls the maximum size of a message the Kafka broker will accept.
To allow WaterDrop (Karafka producer) to send bigger messages, you need to:
- set the
max_payload_sizeconfig option to value in bytes matching your maximum expected payload. - set
kafkascopedmessage.max.bytesto the same value.
You can do this by reconfiguring WaterDrop during Karafka setup:
class KarafkaApp < Karafka::App
setup do |config|
config.producer = ::WaterDrop::Producer.new do |producer_config|
# Use all the settings already defined for consumer by default
producer_config.kafka = ::Karafka::Setup::AttributesMap.producer(config.kafka.dup)
producer_config.logger = config.logger
# Alter things you want to alter
producer_config.max_payload_size = 1_000_000_000
producer_config.kafka[:'message.max.bytes'] = 1_000_000_000
end
end
end
It is essential to keep in mind that increasing the maximum payload size may impact the performance of your Kafka cluster, so you should carefully consider the trade-offs before making any changes.
If you do not allow bigger payloads and try to send them, you will end up with one of the following errors:
WaterDrop::Errors::MessageInvalidError {:payload=>"is more than `max_payload_size` config value"}
or
Rdkafka::RdkafkaError (Broker: Message size too large (msg_size_too_large)):
Why do DLQ messages in my system keep disappearing?
DLQ messages may disappear due to many reasons. Some possible causes include the following:
- The DLQ topic has a retention policy that causes them to expire and be deleted.
- The DLQ topic is a compacted topic, which only retains the last message with a given key.
- The messages are being produced to a DLQ topic with a replication factor of 1, which means that if the broker storing the messages goes down, the messages will be lost.
For more details, please look at the Compacting limitations section of the DLQ documentation.
What is the optimal number of threads to use?
The optimal number of threads for a specific application depends on various factors, including the number of processors and cores available, the amount of memory available, and the particular tasks the application performs and their type. In general, increasing number of threads brings the most significant benefits for IO-bound operations.
It's recommended to use the number of available cores to determine the optimal number of threads for an application.
When working with Karafka, you also need to take into consideration things that may reduce the number of threads being in use, that is:
- Your topics count.
- Your partitions count.
- Number of processes within a given consumer group.
- To how many topics and partitions a particular process is subscribed to.
Karafka can parallelize work in a couple of scenarios, but unless you are a Karafka Pro user and you use Virtual Partitions, in a scenario where your process is assigned to a single topic partition, the work will always happen only in a single thread.
You can read more about Karafka and Karafka Pro concurrency model here.
It's also essential to monitor the performance of the application and the system as a whole while experimenting with different thread counts. This can help you identify bottlenecks and determine the optimal number of threads for the specific use case.
Remember that the optimal number of threads may change as the workload and system resources change over time.
Can I use several producers with different configurations with Karafka?
Yes. You can create as many producers as you want using WaterDrop API directly:
producer = WaterDrop::Producer.new do |config|
config.deliver = true
config.kafka = {
'bootstrap.servers': 'localhost:9092',
'request.required.acks': 1
}
end
and you can use them.
There are a few things to keep in mind, though:
- Producers should be long-lived.
- Producers should be closed before the process shutdown to ensure proper resource finalization.
- You need to instrument each producer using the WaterDrop instrumentation API.
- Karafka itself uses the
Karafka#producerinternal reasons such as error tracking, DLQ dispatches, and more. This means that the default producer instance should be configured to operate within the scope of Karafka's internal functionalities.
What is the Unsupported value "SSL" for configuration property "security.protocol": OpenSSL not available at build time?
If you are seeing the following error:
`validate!':
{:kafka=>"Unsupported value "SSL" for configuration property "security.protocol":
OpenSSL not available at build time"} (Karafka::Errors::InvalidConfigurationError)
It means you want to use SSL, but librdkafka was built without it. You have to:
- Uninstal it by running
gem remove karafka-rdkafka - Install
openssl(OS dependant but for macos, that would bebrew install openssl) - Run
bundle installagain, solibrdkafkais recompiled with SSL support.
Can Karafka ask Kafka to list available topics?
Yes. You can use admin API to do this:
# Get cluster info and list all the topics
info = Karafka::Admin.cluster_info
puts info.topics.map { |topic| topic[:topic_name] }.join(', ')
Why Karafka prints some of the logs with a time delay?
Karafka LoggerListener dispatches messages to the logger immediately. You may be encountering buffering in the stdout itself. This is done because IO operations are slow, and usually it makes more sense to avoid writing every single character immediately to the console.
To avoid this behavior and instead write immediately to stdout, you can set it to a sync mode:
$stdout.sync = true
You can read more about sync here.
Why is increasing concurrency not helping upon a sudden burst of messages?
Karafka uses multiple threads to process messages from multiple partitions or topics in parallel. If your consumer process has a single topic partition assigned, increasing concurrency will not help because there is no work that could be parallelized.
To handle such cases, you can:
- Increase the number of partitions beyond the number of active consumer processes to achieve multiple assignments in a single consumer process. In a case like this, the given process will be able to work in parallel.
- Use Virtual Partitions to parallelize the work of a single topic partition.
You can read more about the Karafka concurrency model here.
Why am I seeing a "needs to be consistent namespacing style" error?
Due to limitations in metric names, topics with a period (.) or underscore (_) could collide. To avoid issues, it is best to use either but not both.
Karafka validates that your topics' names are consistent to minimize the collision risk. If you work with pre-existing topics, you can disable this check by setting config.strict_topics_namespacing value to false:
class KarafkaApp < Karafka::App
setup do |config|
# Do not validate topics naming consistency
config.strict_topics_namespacing = false
end
end
Why, despite setting initial_offset to earliest, Karafka is not picking up messages from the beginning?
There are a few reasons why Karafka may not be picking up messages from the beginning, even if you set initial_offset to earliest:
- Consumer group already exists: If the consumer group you are using to consume messages already exists, Karafka will not start consuming from the beginning by default. Instead, it will start consuming from the last committed offset for that group. To start from the beginning, you need to reset the offsets for the consumer group using the Kafka CLI or using the Karafka consumer
#seekmethod. - Topic retention period: If the messages you are trying to consume are older than the retention period of the topic, they may have already been deleted from Kafka. In this case, setting
initial_offsettoearliestwill not allow you to consume those messages. - Message timestamps: If the messages you are trying to consume have timestamps that are older than the retention period of the topic, they may have already been deleted from Kafka. In this case, even setting
initial_offsettoearliestwill not allow you to consume those messages. - Kafka configuration: There may be a misconfiguration in your Kafka setup that is preventing Karafka from consuming messages from the beginning. For example, the
log.retention.msorlog.retention.bytessettings may be set too low, causing messages to be deleted before you can consume them.
To troubleshoot the issue, you can try:
- changing the Karafka
client_idtemporarily, - renaming the consumer group,
- resetting the offsets for the consumer group using
#seek, - checking the retention period for the topic,
- verifying the messages timestamps,
- reviewing your Kafka configuration to ensure it is correctly set up for your use case.
Should I TSTP, wait a while, then send TERM or set a longer shutdown_timeout and only send a TERM signal?
This depends on many factors:
- do you use
cooperative.stickyrebalance strategy? - do you use static group memberships?
- do you do rolling deploys or all at once?
- are your jobs long-running?
- are you ok with intermediate rebalances?
The general rule is that if you want to ensure all of your current work finishes before you stop Karafka or that there won't be any short-lived rebalances, it is recommended to use TSTP and wait. When Karafka receives TSTP signal, it moves into a quiet mode. It won't accept any new work, but all the currently running and locally enqueued jobs will be finished. It will also not close any connections to Kafka, which means that rebalance will not be triggered.
If you want to ensure that the shutdown always finishes in a given time, you should set the shutdown_timeout accordingly and use TERM, keeping in mind it may cause a forceful shutdown which kills the currently running jobs.
If you decide to do a full deployment, you can send TSTP to all the processes, wait for all the work to be done (you can monitor if using the Web UI), and then stop the processes using TERM.
Why am I getting error:0A000086:SSL routines::certificate verify failed after upgrading Karafka?
If you are getting following error after upgrading karafka and karafka-core:
SSL handshake failed: error:0A000086:SSL routines::certificate verify failed:
broker certificate could not be verified, verify that ssl.ca.location is correctly configured or
root CA certificates are installed (brew install openssl) (after 170ms in state SSL_HANDSHAKE)
Please disable the SSL verification in your configuration:
class KarafkaApp < Karafka::App
setup do |config|
config.kafka = {
# Other settings...
'enable.ssl.certificate.verification': false,
'ssl.endpoint.identification.algorithm': 'none'
}
end
end
Why am I seeing a karafka_admin consumer group with a constant lag present?
The karafka_admin consumer group was created when using certain admin API operations. After upgrading to karafka 2.0.37 or higher, this consumer group is no longer needed and can be safely removed.
Can I consume the same topic independently using two consumers within the same application?
Yes. You can define independent consumer groups operating within the same application. Let's say you want to consume messages from a topic called event using two consumers. You can do this as follows:
class KarafkaApp < Karafka::App
setup do |config|
# ...
end
routes.draw do
consumer_group :db_storage do
topic :events do
consumer DbFlusherConsumer
end
end
consumer_group :s3_storage do
topic :events do
consumer S3StoringConsumer
end
end
end
end
Such a setup will ensure that both of them can be processed independently in parallel. Error handling, dead letter queue, and all the other per-topic behaviors will remain independent despite consuming the same topic.
Why am I seeing Broker failed to validate record (invalid_record) error?
The error Broker failed to validate record (invalid_record) in Kafka means that the broker received a record that it could not accept. This error can occur if the record is malformed or does not conform to the schema expected by the broker.
There are several reasons why a Kafka broker might reject some messages:
- Invalid message format: If the message format does not match the expected format of the topic, the broker may reject the message.
- Missing message key. If you use log compaction as your
cleanup.policyKafka will require you to provide the key. Log compaction ensures that Kafka will always retain at least the last known value for each message key within the log of data for a single topic partition. If you enable compaction for a topic, messages without a key may be rejected. - Schema validation failure: If the message contains data that does not conform to the schema, the broker may reject the message. This can happen if the schema has changed or the data was not properly validated before being sent to Kafka.
- Authorization failure: If the client does not have the required permissions to write to the topic, the broker may reject the message.
- Broker capacity limitations: If the broker has limited resources and cannot handle the incoming message traffic, it may reject some messages.
To resolve this error, it is essential to identify the root cause of the issue. Checking the message format and schema, ensuring proper authorization and permission, checking broker capacity, and addressing network issues can help resolve the issue. Additionally, monitoring Karafka logs to identify and resolve problems as quickly as possible is crucial.
How can I make polling faster?
You can decrease the max_wait_time Karafka configuration or lower the max_messages setting.
class KarafkaApp < Karafka::App
setup do |config|
# Other settings...
# Wait for messages at most 100ms
config.max_wait_time = 100
# If you got 10 messages faster than in 100ms also don't wait any longer
config.max_messages = 10
end
end
Can I dynamically add consumer groups and topics to a running Karafka process?
No. It is not possible. Changes like this require karafka server restart.
Can a consumer instance be called multiple times from multiple threads?
No. Given consumer object instance will never be called/used from multiple threads simultaneously. Karafka ensures that a single consumer instance is always used from a single thread. Other threads may call the consumer object for coordination, but this is unrelated to your code.
Can multiple threads reuse a single consumer instance?
A single consumer instance can perform work in many threads but only in one simultaneously. Karafka does not guarantee that consecutive batches of messages will be processed in the same thread, but it does ensure that the same consumer instance will process successive batches. A single consumer instance will never process any work in parallel.
What does Broker: Unknown topic or partition error mean?
The Broker: Unknown topic or partition error typically indicates that the Kafka broker cannot find the specified topic or partition that the client is trying to access.
There are several possible reasons why this error might occur:
- The topic or partition may not exist on the broker. Double-check that the topic and partition you are trying to access exists on the Kafka cluster you are connecting to.
- The topic or partition may still need to be created. If you are trying to access a topic or partition that has not been created yet, you will need to create it before you can use it.
- The client may not have permission to access the topic or partition. Ensure that the client has the necessary permissions to read from or write to the topic or partition you are trying to access.
- The client may be using an incorrect topic or partition name. Ensure you use the correct topic or partition name in your client code.
You can use Karafka Web UI or Karafka Admin API to inspect your cluster topics and ensure that the requested topic and partition exist.
Why some of consumer subscriptions are not visible in the Web UI?
If some of your Karafka consumer subscriptions are not visible in the Karafka Web UI, there could be a few reasons for this:
- You are using Karafka Web older than the
0.4.1version. Older Karafka Web UI versions used to only shows subscriptions that have at least one message processed. - The consumer group that the subscription belongs to is not active. Karafka only displays active consumer groups in the Web UI. Make - sure that your consumer group is up and running. The subscription is not properly configured. Ensure that your subscription is appropriately defined, has the correct topic, and is active.
- There is a delay in the Karafka Web UI updating its data. Karafka Web UI may take a few seconds to update its data, especially if many subscriptions or messages are being processed.
If none of these reasons explain why your subscriptions are not visible in the Karafka Web UI, you may need to investigate further and check your Karafka logs for any errors or warnings.
Is there a way to run Karafka in a producer-only mode?
Yes, it is possible to run Karafka in producer-only mode. Karafka will not consume any messages from Kafka in this mode but only produce messages to Kafka.
To run Karafka in producer-only mode, do not define any topics for consumption or set all of them as inactive:
class KarafkaApp < Karafka::App
setup do |config|
# ...
end
routes.draw do
# Leave this empty or set `active false` for all the topics
end
end
With this configuration, Karafka will not create any consumer groups and will only initialize the Karafka.producer.
Keep in mind that with this configuration, you will not be able to start karafka server but you will be able to access Karafka.producer from other processes like Puma or Sidekiq.
Why am I getting the can't alloc thread (ThreadError) error from the producer?
If you see this error from your Ruby process that is not a running Karafka process, you did not close the producer before finishing the process.
It is recommended to always run Karafka.producer.close before finishing processes like rake tasks, Puma server, or Sidekiq, so Karafka producer has a chance to dispatch all pending messages and gracefully close.
You can read more about producer shutdown here.
Can I create all the topics needed by the Web UI manually?
While it is possible to create the necessary topics manually using the Kafka command-line tools, it is generally recommended to use the bundle exec karafka-web install command instead.
This is because the karafka-web install command ensures that the topics are created with the correct configuration settings, including the appropriate number of partitions, retention policies, and other critical parameters for efficient and reliable message processing. If you create the topics manually, there is a risk that you may miss some configuration settings or make mistakes that can cause performance or stability issues.
Overall, while it is technically possible to create the necessary topics for the Karafka Web UI manually, it is generally recommended to use the karafka-web install command instead.
If you need to create them manually, please include the settings listed here.
Can I consume messages from a Rake task?
Yes. Karafka Pro provides the Iterator API that allows you to run one-off consumptions inline from within Rake tasks and any other Ruby processes.
Do you provide an upgrade support when upgrading from EOL versions?
While we always try to help anyone from the Karafka community with their problems, extensive upgrade support requiring involvement is part of our Pro Support offering.
Why there are so many Karafka strategies in the codebase?
Karafka provides several different strategies for consuming messages from Kafka, each with its own trade-offs and use cases. The reason for this is to give developers the flexibility to choose the strategy that best fits their specific requirements, and another reason is code simplification. Particular strategies often differ with one or two lines of code, but those changes significantly impact how Karafka operates. With separate strategies, each case is handled independently and can be debugged and understood in isolation.
But why would Karafka need multiple strategies in the codebase? The answer lies in the diverse range of use cases that Karafka is designed to support.
By supporting multiple strategies in the codebase, Karafka can cater to a wide range of use cases and provide developers with the flexibility they need to build the applications they want.
Why am I having problems running Karafka and Karafka Web with remote Kafka?
Karafka and librdkafka are not designed to work over unstable and slow network connections, and these libraries contain internal timeouts on network operations that slow networks may impact. As a result, it is recommended to use a local Docker-based Kafka instance for local development. We are aware of this issue and are actively working to make these timeouts configurable in the future. Using a local Kafka instance for local development can help you avoid network-related problems and ensure a smoother development experience.
Why after moving from Racecar to Karafka, my Confluent Datadog integration stopped working?
When a new consumer group is introduced, Confluent reports things with a delay to Datadog. This is because the new consumer group needs to be registered with Confluent before it can start reporting metrics to Datadog.
To ensure a smoother monitoring experience, we recommend enabling Karafka Datadog integration. It will allow you to easily monitor your Karafka operations and ensure everything is running smoothly. An out-of-the-box dashboard can be imported to Datadog for overseeing Karafka operations. This dashboard provides detailed metrics and insights into your Karafka operations, making identifying and resolving issues easier.
Why am I getting env: can't execute 'bash' when installing Karafka in an Alpine Docker?
If you encounter the following error:
========================================================================
env: can't execute 'bash': No such file or directory
========================================================================
rake aborted!
Failed to complete configure task
/app/vendor/bundle/ruby/2.7.0/gems/mini_portile2-2.8.0/lib/mini_portile2/mini_portile.rb:460:in
`block in execute'
you need to make sure that your Alpine-based image includes bash. Alpine Linux Docker image by default does not include it. To add it, please make sure to add this line before you run the bundle install process:
RUN apk update && apk add bash
Can I intercept WaterDrop messages in tests?
Yes. You need to configure WaterDrop producer to use the karafka-testing spec dummy client:
require 'karafka/testing/errors'
require 'karafka/testing/spec_consumer_client'
RSpec.describe MyTestedLib do
subject(:my_lib) { described_class.new }
let(:karafka_producer_client) { Karafka::Testing::SpecProducerClient.new(self) }
before do
allow(MY_KARAFKA_PRODUCER).to receive(:client).and_return(karafka_producer_client)
end
it 'expect to dispatch one message' do
my_lib.do_something
expect(karafka_producer_client.messages.count).to eq(1)
end
end
You can find the SpecProducerClient API here.
Does Karafka Expiring Messages remove messages from Kafka?
When a message is produced to a Kafka topic, it is stored in Kafka until it expires based on the retention policy of the topic. The retention policy determines how long messages are kept in Kafka before they are deleted.
Karafka's Expiring Messages functionality removes messages from Karafka's internal processing queue after a specified amount of time has passed since the message was produced. This functionality is useful when processing messages with a limited lifetime, such as messages with time-sensitive data or messages that should not be processed after a certain amount of time has passed.
However, it's important to note that Karafka's Expiring Messages functionality does not remove messages from Kafka itself, and it only removes messages from Karafka's internal processing queue. Therefore, the retention policy of the Kafka topic will still apply, and the message will remain in Kafka until it expires based on the topic's retention policy.
To set the retention policy of a Kafka topic, you can use Kafka's built-in retention policies or configure custom retention policies using the declarative topics functionality. By configuring the retention policy, you can control how long messages are kept in Kafka before they are deleted, regardless of whether Karafka has processed them or not.
Can you actively ping the cluster from Karafka to check the cluster availability?
Yes, you can use Karafka's Admin API to retrieve cluster information and check the reachability of the Kafka cluster. The Karafka::Admin.cluster_info method can be used to retrieve metadata about the Kafka cluster, including details about brokers, topics, and partitions.
If the method call is successful, it indicates that the Karafka application was able to connect to the Kafka cluster and retrieve metadata about the brokers and topics. However, it's important to note that this does not necessarily mean everything with the cluster is okay.
"Kafka being up" is a rather complex matter. Many factors can affect the overall health and performance of a Kafka cluster, including network issues, broker failures, and misconfigured settings. Therefore, it's essential to use additional monitoring and alerting mechanisms to ensure the reliability and availability of your Kafka cluster.
You can read more about this topic here.
How do I specify Karafka's environment?
Karafka uses the KARAFKA_ENV variable for that; if missing, it will try to detect it. You can read more about this topic here.
How can I configure WaterDrop with SCRAM?
You can use the same setup as the one used by Karafka, described here.
Why am I getting a Local: Broker transport failure (transport) error with the Disconnected info?
If you are seeing following or similar error:
rdkafka: [thrd:node_url]: node_url: Disconnected (after 660461ms in state UP)
librdkafka internal error occurred: Local: Broker transport failure (transport)
The error message you mentioned may be related to the connection reaper in Kafka disconnecting because the TCP socket has been idle for a long time. The connection reaper is a mechanism in Kafka that monitors the idle TCP connections and disconnects them if they exceed a specific time limit. This is done to free up resources on the broker side and to prevent the accumulation of inactive connections.
If the client application is not sending or receiving data over the TCP connection for a long time, the connection reaper may kick in and disconnect the client from the broker.
However, this disconnection does not mean that any produced data will be lost. When the client application reconnects to the broker, it can resume sending or receiving messages from where it left off.
Suppose your data production patterns are not stable, and there are times when your client application is not producing any data to Kafka for over 10 minutes. In that case, you may want to consider setting the log.connection.close value to false in your configuration. This configuration parameter controls whether the client logs a message when a connection is closed by the broker. By default, the client will log a message indicating that the connection was closed, which can generate false alarms if the connection was closed due to inactivity by the connection reaper.
Setting log.connection.close to false will suppress these log messages and prevent the error from being raised. It's important to note that even if you set log.connection.close to false, critical non-recoverable errors that occur in Karafka and WaterDrop will still be reported via the instrumentation pipeline.
class KarafkaApp < Karafka::App
setup do |config|
config.client_id = 'my_application'
config.kafka = {
# other settings...
'log.connection.close': false
}
end
end
Please note that you can control the connections.max.idle.ms on both Kafka and Karafka consumer / WaterDrop producer basis.
You can read more about this issue here.
Why am I getting a All broker connections are down (all_brokers_down) error together with the Disconnected info?
When you see both the Disconnected error and the all_brokers_down error, it means that the TCP connection to the cluster was closed and that you no longer have any active connections.
Please read the explanation of the previous question to understand the reasons and get tips on mitigating this issue.
rdkafka: [thrd:node_url]: node_url: Disconnected (after 660461ms in state UP)
librdkafka internal error occurred: Local: Broker transport failure (transport)
Error occurred: Local: All broker connections are down (all_brokers_down) - librdkafka.error
What is the difference between partition_key and key in the WaterDrop gem?
In the WaterDrop gem, partition_key and key are two distinct options that can be used to set message keys, but they have different purposes and work slightly differently.
partition_keyis used to determine the partition to which a message is sent and computes the destination partition in the Ruby process using the configuredpartitioneralgorithm. The partitioner calculates a hash value based on the partition_key value and uses this hash value to select a partition for the message.keyis an optional property that can be set for a message. The Kafka broker uses the message key for log compaction, which ensures that only the latest message for a specific key is retained in the topic. Unless partition is explicitly provided viapartitionorpartition_key, thekeyvalue will also be used for partition assignment.
How can I set up WaterDrop with SCRAM?
You can configure it the same way as Karafka support for SCRAM described here.
Is there a way to mark messages as consumed in bulk?
In Kafka, there is no explicit need to mark messages as "consumed" in bulk because Kafka's offset mechanism takes care of this automatically.
The moment you consume a message from a specific topic partition at a particular offset, Kafka considers all previous messages up to that offset as consumed.
Kafka maintains a commit log that records the offset of each message within a topic partition. When a consumer reads messages from a partition, it keeps track of the offset of the last consumed message. This offset is then used to resume consumption from the same point if the consumer restarts or fails.
When you mark a message as consumed with a higher offset, it implies that all previous messages with lower offsets have been successfully processed and considered consumed. Kafka's offset mechanism ensures that the consumer's offset is moved accordingly, indicating that those messages have been processed.
While Kafka's offset mechanism automatically tracks the progress of message consumption and allows you to resume from the last consumed offset, there can be scenarios where explicitly marking each message as consumed becomes beneficial. This is particularly relevant when messages are processed sequentially, with a significant time gap between consuming each message.
In such cases, marking each message as consumed provides finer-grained control over the consuming progress. By explicitly acknowledging the consumption of each message, you ensure that even if a crash or failure occurs during processing, the consumer can resume from the last successfully processed message.
Here's an explanation of the benefits of marking each message as consumed:
-
Granular Progress Tracking: Marking each message as consumed allows you to have a more detailed view of the processing progress. You can precisely identify the last processed message and easily determine the remaining messages that need to be processed.
-
Enhanced Fault Tolerance: In the event of a crash or failure, explicitly marking each message as consumed ensures that the consumer can restart from the last processed message rather than starting from the beginning or relying solely on the offset mechanism. This reduces duplicated processing and improves fault tolerance.
-
Handling Long-running Processing: If the processing time for each message is significant, explicitly marking them as consumed provides better visibility into the progress. It allows you to identify any potential bottlenecks or delays in processing and take appropriate actions if needed.
When using Karafka Virtual Partitions, it is recommended to mark each message as consumed due to how Virtual Offset Management works.
How can I consume all the messages from a Kafka topic without a consumer process?
Karafka has an Iterator API for that. You can read about it here.
What does Broker: Invalid message (invalid_msg) error mean?
If you see the following error in your error tracking system:
ERROR -- : Listener fetch loop error: Broker: Invalid message (invalid_msg)
ERROR -- : gems/karafka-rdkafka-0.12.1/lib/rdkafka/consumer.rb:432:in `poll'
ERROR -- : gems/karafka-2.0.41/lib/karafka/connection/client.rb:368:in `poll'
It indicates that the broker contains a message that it cannot parse or understand. This error usually occurs when there is a mismatch or inconsistency in the format or structure of the message or when the message is corrupted.
It is advised to check the Kafka logs around the polling time, as it may be a Kafka issue. You may encounter the following or similar errors:
org.apache.kafka.common.errors.CorruptRecordException:
Found record size 0 smaller than minimum record overhead (14)
in file /var/lib/my_topic-0/00000000000019077350.log.
This exception indicates a record has failed its internal CRC check; this generally indicates network or disk corruption.
Is there an option in Karafka to re-consume all the messages from a topic even though all were already consumed?
Yes.
There are a few ways to do that:
- Use the Iterator API to run a one-time job alongside your regular Karafka consumption.
- Use the
#seekconsumer method in combination with Admin watermark API to move to the first offset and re-consume all the data. - Create a new consumer group that will start from the beginning.
How can I make sure, that Karafka.producer does not block/delay my processing?
To ensure that Karafka.producer does not block or delay your processing, you can utilize the produce_async and produce_many_async. These methods only block the execution flow if the underlying librdkafka queue is full.
By default, if the queue is full, Karafka will enter a backoff state and wait for a specified time before retrying. The wait_backoff_on_queue_full and wait_timeout_on_queue_full settings in your Karafka configuration file control this behavior. If you want to disable the waiting behavior altogether, you can set the wait_on_queue_full option to false.
Additionally, you can adjust the message.timeout.ms setting in librdkafka settings to potentially ignore the delivery handles of dispatched messages. By appropriately setting this value, you can reduce the time spent waiting for delivery confirmation, thus avoiding potential delays in your processing pipeline.
When wait_on_queue_full is disabled and the queue becomes full, the producer will raise an exception. It's important to catch and handle this exception appropriately. You can ignore the exception if you don't want it to disrupt the execution flow of your program.
Here's an example of how you can use produce_async and handle the exception:
begin
Karafka.producer.produce_async(topic: topic, payload: payload)
rescue Rdkafka::RdkafkaError do |e|
raise unless e.code == :queue_full
end
If you aim for maximum performance in your Karafka application, you can disable metrics collection by setting the statistics.interval.ms configuration to 0. Doing so effectively disables the collection and emission of statistics data. This can be beneficial in scenarios where every bit of performance matters and you want to minimize any overhead caused by metric aggregation. However, it's important to note that disabling metrics collection will also prevent the Karafka Web UI from collecting important information, such as producer errors, including those in background threads. Therefore, consider the trade-off between performance optimization and the loss of detailed error tracking when deciding whether to disable metrics collection.
Can at_exit be used to close the WaterDrop producer?
at_exit is a Ruby method that allows you to register a block of code to be executed when the program is about to exit. It can be used for performing cleanup tasks or finalizing resources. However, using at_exit to close the WaterDrop producer in Karafka is not recommended.
Instead of relying on at_exit, it is generally better to handle the cleanup and proper closing of the WaterDrop producer explicitly in your code. For example, you can use signal handlers from other Ruby libraries like Sidekiq or Puma.
You can read more about this here.
Why, when DLQ is used with max_retries set to 0, Karafka also applies a back-off?
Even when no retries are requested, applying a back-off strategy is crucial in maintaining system stability and preventing system overload.
When Karafka encounters an error processing a message, it might be due to a temporary or intermittent issue. Even if retries are not set, the system needs a moment to recover and stabilize after an error before moving on to the next message.
By applying a back-off strategy, Karafka ensures that a pause is introduced between the occurrence of the error and the dispatch of the message to the Dead Letter Queue (DLQ) or the processing of the next message. This brief pause allows the system's resources to recover. For instance, if the error were due to a sudden spike in CPU usage, the back-off time would give the CPU a chance to cool down. If the error was due to a momentary network issue, the pause allows time for the network to stabilize.
Without the back-off mechanism, even if retries are not requested, Karafka would move on to the next message immediately after an error. If errors are frequent, this could lead to the system getting into a state where it is constantly encountering errors and never getting a chance to recover. This, in turn, could lead to an overload of the system, causing degraded performance or even a complete system crash.
Can I use rdkafka and karafka-rdkafka together in the same project?
No. karafka-rdkafka is a fork of rdkafka that includes many stability and performance enhancements while having a compatible API. If you try to use both, they will conflict with each other.
Does using consumer #seek resets the committed offset?
No, using the #seek method in a Karafka consumer does not reset the committed offset.
In Karafka, the #seek method is used to manually set the position of the next record that should be fetched, i.e., it changes the current position of the consumer. However, it does not affect the committed offset stored in Kafka.
The committed offset is the position of the last record that Kafka will not read again in the event of recovery or failover.
So, you can think of the position set by #seek as a volatile, in-memory value, while the committed offset is a more durable, stored value.
If you would like to #seek back and be able to commit offsets from the seek location, please use the reset_offset flag when seeking:
def consume
# Some operations...
# ...
seek(100, reset_offset: true)
end
Is it recommended to use public consumer methods from outside the consumer?
In general, it is not recommended to use public consumer methods from outside the consumer in Karafka.
Karafka is designed to handle the concurrent processing of messages. Directly calling consumer methods from outside the consumer could result in race conditions or other concurrency issues if not done carefully.
The only exception is when you are using Karafka instrumentation API. However, it is still not recommended to invoke any methods or operations that would result in consumer state changes.
Why do I see SASL authentication error after AWS MSK finished the Heal cluster operation?
Healing means that Amazon MSK is running an internal operation, like replacing an unhealthy broker. For example, the broker might be unresponsive. During this stage, under certain circumstances, the MSK permissions may be not restored correctly. We recommend that you reassign them back if the problem persists.
Why Karafka and WaterDrop are behaving differently than rdkafka?
-
rdkafka-rubylack of instrumentation callbacks hooks by default: By default,rdkafkadoes not include instrumentation callback hooks. This means that it does not publish asynchronous errors unless explicitly configured to do so. On the other hand, Karafka and WaterDrop, provide a unified instrumentation framework that reports errors, even those happening asynchronously, by default. -
WaterDrop and Karafka use
karafka-rdkafka, which is patched and provides specific improvements: Both WaterDrop and Karafka use a variant ofrdkafka-ruby, known askarafka-rdkafka. This version is patched, meaning it includes improvements and modifications that the standardrdkafka-rubyclient does not. These patches may offer enhanced performance, additional features, and/or bug fixes that can impact how the two systems behaves. -
Different setup conditions: Comparing different Kafka clients or frameworks can be like comparing apples to oranges if they aren't set up under the same conditions. Factors such as client configuration, Kafka cluster configuration, network latency, message sizes, targeted topics, and batching settings can significantly influence the behavior and performance of Kafka clients. Therefore, when you notice a discrepancy between the behavior of
rdkafka-rubyand Karafka or WaterDrop, it might be because the conditions they are running under are not identical. To make a fair comparison, ensure that they are configured similarly and are running under the same conditions.
In summary, while rdkafka-ruby, Karafka, and WaterDrop all provide ways to interact with Kafka from a Ruby environment, differences in their design, their handling of errors, and the conditions under which they are run can result in different behavior. Always consider these factors when evaluating or troubleshooting these systems.
Why am I seeing Inconsistent group protocol in Karafka logs?
Seeing an Inconsistent group protocol message in your Karafka logs indicates a mismatch in the protocol type or version among the members of a Kafka consumer group.
In Kafka, a consumer group consists of one or more consumers that jointly consume data from a topic. These consumers communicate with the Kafka broker and coordinate with each other to consume different partitions of the data. This coordination process is managed using group protocols.
An Inconsistent group protocol error typically arises in the following scenarios:
-
Different consumers within the same group are using different protocol types or versions: Kafka supports several group protocols for consumer coordination, such as range or round-robin. If different consumers within the same group are configured with varying protocols or versions, this inconsistency will cause an error. Make sure all consumers in the group are using the same protocol.
-
A mix of consumers with different session timeouts: When consumers in a group have different session timeout settings, they may not always be in sync, leading to this error. Ensure all consumers have the same session timeout setting. Misconfiguration during consumer setup: If you have recently made changes to your consumer setup, you might have inadvertently introduced a configuration that causes this error. Review your configuration changes to ensure consistency.
Consistency in consumer configuration within a group is vital to prevent this error. Review your consumers' settings and configurations to ensure they use the same group protocol, and adjust if necessary.
What is the difference between WaterDrop's max_payload_size and librdkafka's message.max.bytes?
WaterDrop's max_payload_size and librdkafka's message.max.bytes are both settings related to message size in Kafka, but they play distinct roles and operate at different stages.
WaterDrop's max_payload_size is a configuration parameter employed for internal validation within the WaterDrop producer library. This setting is used to limit the size of the messages before they're dispatched. If a message exceeds the max_payload_size, an error is raised, preventing the dispatch attempt. This setting helps ensure that you don't send messages larger than intended.
On the other hand, librdkafka's message.max.bytes configuration is concerned with the Kafka protocol's message size. It represents the maximum permissible size of a message in line with the Kafka protocol, and the librdkafka library validates it. Essentially, it determines the maximum size of a ProduceRequest in Kafka.
It's advisable to align these two settings to maintain consistency between the maximum payload size defined by WaterDrop and the Kafka protocol. To ensure that larger-than-expected messages are not accepted, it's beneficial to set the max_payload_size in WaterDrop. And for message.max.bytes in librdkafka, you might want to set it to the same value or even higher, bearing in mind its role in the Kafka protocol.
There are a few nuances to be aware of, which are often seen as "edge cases." One notable aspect is that the producer checks the uncompressed size of a message against the message.max.bytes setting while the broker validates the compressed size.
Another noteworthy point is that if you set message.max.bytes to a low yet acceptable value, it could affect the batching process of librdkafka. Specifically, librdkafka might not be able to build larger message batches, leading to data being sent in much smaller batches, sometimes even as small as a single message. This could consequently limit the throughput.
A detailed discussion on this topic can be found on this GitHub thread: https://github.com/confluentinc/librdkafka/issues/3246. Please note that this discussion remains open, indicating this topic's complexity and continuous exploration.
Lastly, while the term message.max.bytes may not be intuitively understandable, its role in managing message size within the Kafka ecosystem is crucial.
What are consumer groups used for?
Consumer groups in Kafka are used to achieve parallel processing, high throughput, fault tolerance, and scalability in consuming messages from Kafka topics. They enable distributing of the workload among multiple consumers within a group, ensuring efficient processing and uninterrupted operation even in the presence of failures. In general, for 90% of cases, one consumer group is used per Karafka application. Using multiple consumer groups in a single app can be beneficial if you want to consume the same topic multiple times, structure your app for future division into microservices or introduce parallel consumption.
Why am I getting the all topic names within a single consumer group must be unique error?
If you are seeing the following error when starting Karafka:
{:topics=>"all topic names within a single consumer group must be unique"}
(Karafka::Errors::InvalidConfigurationError)
it indicates that you have duplicate topic names in your configuration of the same consumer group.
In Karafka, each topic within a consumer group should have a unique name. This requirement is in place because each consumer within a consumer group reads from a unique partition of a specific topic. If there are duplicate topic names, then the consumers will not be able to distinguish between these topics.
To solve this issue, you need to ensure that all topic names within a single consumer group in your Karafka configuration are unique.
Why am I getting WaterDrop::Errors::ProduceError, and how can I know the underlying cause?
The specifics of why you're encountering this error will depend on the context of your use of WaterDrop and Kafka. Here are some possible causes:
-
Kafka is not running or unreachable: Ensure that Kafka is running and accessible from your application. If your application is running in a different environment (e.g., Docker, a different server, etc.), ensure there are no networking issues preventing communication.
-
Invalid configuration: Your WaterDrop and/or Kafka configuration may be incorrect. This could involve things like incorrect broker addresses, authentication details, etc.
-
Kafka topic does not exist: If you're trying to produce to a topic that doesn't exist, and if topic auto-creation is not enabled in your Kafka settings, the message production will fail.
-
Kafka cluster is overloaded or has insufficient resources: If Kafka is not able to handle the volume of messages being produced, this error may occur.
-
Kafka cluster is in a remote location with significant latency: Apache Kafka is designed to handle high-volume real-time data streams with low latency. If your Kafka cluster is located in a geographically distant location from your application or the network connectivity between your application and the Kafka cluster could be better, you may experience high latency. This can cause a variety of issues, including
WaterDrop::Errors::ProduceError. -
Access Control Lists (ACLs) misconfiguration: ACLs control the permissions for Kafka resources; incorrect configurations might prevent messages from being produced or consumed. To diagnose, verify your Kafka ACLs settings to ensure your producer has the correct permissions for the operations it's trying to perform.
When you receive the WaterDrop::Errors::ProduceError error, you can check the underlying cause by invoking the #cause method on the received error:
error = nil
begin
Karafka.producer.produce_sync(topic: 'topic', payload: 'payload')
rescue WaterDrop::Errors::ProduceError => e
error = e
end
puts error.cause
#<Rdkafka::AbstractHandle::WaitTimeoutError: Waiting for delivery timed out after 5 seconds>
Please note that in the case of the WaitTimeoutError, the message may actually be delivered but in a more extended time because of the network or other issues. Always instrument your producers to ensure that you are notified about errors occurring in Karafka and WaterDrop internal background threads as well.
The exact cause can often be determined by examining the error message and stack trace accompanying the WaterDrop::Errors::ProduceError. Also, check the Kafka logs for more information. If the error message or logs aren't clear, you should debug your code or configuration to identify the problem.
If you're having trouble sending messages, a good debugging step is to set up a new producer with a shorter message.timeout.ms kafka setting. This means librdkafka won't keep retrying for long, and you'll see the main issue faster.
# Create a producer configuration based on the Karafka one
producer_kafka_cfg = ::Karafka::Setup::AttributesMap.producer(
Karafka::App.config.kafka.dup
)
# Set the message timeout to five seconds to get the underlying error fast
producer_kafka_cfg[:'message.timeout.ms'] = 5_000
# Build a producer
producer = ::WaterDrop::Producer.new do |p_config|
p_config.kafka = producer_kafka_cfg
p_config.logger = Karafka::App.config.logger
end
# Print all async errors details
producer.monitor.subscribe('error.occurred') do |event|
p event
p event[:error]
end
# Try to dispatch message to the topic with which you have problem
#
# Please note, that we use `#produce_async` here and wait.
# That's because we do not want to crash the execution but instead wait on
# the async error to appear.
producer.produce_async(
topic: 'problematic_topic',
payload: 'test'
)
# Wait for the async error (if any)
# librdkafka will give up after 5 seconds, so this should be more than enough
sleep(30)
Can extra information be added to the messages dispatched to the DLQ?
Yes. Karafka Enhanced DLQ provides the ability to add custom details to any message dispatched to the DLQ. You can read about this feature here.
Why does WaterDrop hang when I attempt to close it?
WaterDrop works so that when the producer is requested to be closed, it triggers a process to flush out all the remaining messages in its buffers. The process is synchronous, meaning that it will hold the termination of the application until all the messages in the buffer are either delivered successfully or evicted from the queue.
If Kafka is down, WaterDrop will still attempt to wait before closing for as long as there is even a single message in the queue. This waiting time is governed by the message.timeout.ms setting in the Kafka configuration. This setting determines how long the librdkafka library should keep the message in the queue and how long it should retry to deliver it. By default, this is set to 5 minutes.
Effectively, this means that if the Kafka cluster is down, WaterDrop will not terminate or give up on delivering the messages until after this default timeout period of 5 minutes. This ensures maximum efforts are made to deliver the messages even under difficult circumstances.
If a message is eventually evicted from the queue due to unsuccessful delivery, an error is emitted via the error.occurred channel in the WaterDrop's instrumentation bus. This allows developers to catch, handle, and log these events, giving them insight into any issues that might be causing message delivery failures.
In summary, the hanging issue you are experiencing when attempting to close WaterDrop is a designed behavior intended to ensure all buffered messages are delivered to Kafka before the client stops, even if the Kafka cluster is temporarily unavailable.
Why Karafka commits offsets on rebalances and librdkafka does not?
While Karafka uses librdkafa under the hood, they serve slightly purposes and follow different design principles.
Karafka is designed with certain assumptions, such as auto-committing offsets, to simplify its usage for Ruby developers. One of the key decisions is to commit offsets on rebalances and assume that the offset management is done using Kafka itself with optional additional offset storage when needed. The reason behind this is to ensure that messages are processed only once in the case of a group rebalance. By committing offsets on rebalances, Karafka tries to ensure at-least-once delivery. That is, every message will be processed at least once, and no message will be lost, which is a typical requirement in many data processing tasks.
On the other hand, librdkafka is a C library that implements the Apache Kafka protocol. It's designed to be more flexible and to offer more control to the user. It doesn't commit offsets on rebalances by default because it gives power to the application developer to decide when and how to commit offsets and where to store them. Depending on the specific requirements of your application, you may want to handle offsets differently.
So the difference between the two libraries is mainly due to their different design principles and target audiences: Karafka is more opinionated and tries to simplify usage for Ruby developers, while librdkafka is more flexible and provides more control to the user but at the same time requires much more knowledge and effort.
What is Karafka's assignment strategy for topics and partitions?
As of Karafka 2.0, the default assignment strategy is range, which means that it attempts to assign partitions contiguously. For instance, if you have ten partitions and two consumers, then the first consumer might be assigned partitions 0-4, and the second consumer would be given partitions 5-9.
The range strategy has some advantages over the round-robin strategy, where partitions are distributed evenly but not contiguously among consumers.
Since data is often related within the same partition, range can keep related data processing within the same consumer, which could lead to benefits like better caching or business logic efficiencies. This can be useful, for example, to join records from two topics with the same number of partitions and the same key-partitioning logic.
The assignment strategy is not a one-size-fits-all solution and can be changed based on the specific use case. If you want to change the assignment strategy in Karafka, you can set the partition.assignment.strategy configuration value to either range, roundrobin or cooperative-sticky. It's important to consider your particular use case, the number of consumers, and the nature of your data when choosing your assignment strategy.
Why can't I see the assignment strategy/protocol for some Karafka consumer groups?
The assignment strategy or protocol for a Karafka consumer group might not be visible if a topic is empty, no data has been consumed, and no offsets were stored. These conditions indicate that no data has been produced to the topic and no consumer group has read any data, leaving no record of consumed data.
In such cases, Kafka doesn't have any information to establish an assignment strategy. Hence, it remains invisible until data is produced, consumed, and offsets are committed.
What can be done to log why the produce_sync has failed?
WaterDrop allows you to listen to all errors that occur while producing messages and in its internal background threads. Things like reconnecting to Kafka upon network errors and others unrelated to publishing messages are all available under error.occurred notification key. You can subscribe to this event to ensure your setup is healthy and without any problems that would otherwise go unnoticed as long as messages are delivered:
Karafka.producer.monitor.subscribe('error.occurred') do |event|
error = event[:error]
p "WaterDrop error occurred: #{error}"
end
# Run this code without Kafka cluster
loop do
Karafka.producer.produce_async(topic: 'events', payload: 'data')
sleep(1)
end
# After you stop your Kafka cluster, you will see a lot of those:
#
# WaterDrop error occurred: Local: Broker transport failure (transport)
#
# WaterDrop error occurred: Local: Broker transport failure (transport)
It is also recommended to check if the standard LoggerListener is enabled for the producer in your karafka.rb:
Karafka.producer.monitor.subscribe(
WaterDrop::Instrumentation::LoggerListener.new(Karafka.logger)
)
error.occurred will also include any errors originating from librdkafka for synchronous operations, including those that are raised back to the end user.
Can I password-protect Karafka Web UI?
Yes, you can password-protect the Karafka Web UI, and it is highly recommended. Adding a layer of password protection adds a level of security to the interface, reducing the risk of unauthorized access to your data, configurations, and system settings.
Karafka provides ways to implement password protection, and you can find detailed steps and guidelines here.
Can I use a Karafka producer without setting up a consumer?
Yes, it's possible to use a Karafka producer without a consumer in two ways:
-
You can use WaterDrop, a standalone Karafka component for producing Kafka messages. WaterDrop was explicitly designed for use cases where only message production is required, with no need for consumption.
-
Alternatively, if you have Karafka already in your application, avoid running the
karafka servercommand, as it won't make sense without any topics to consume. You can run other processes and produce messages from them. In scenarios like that, there is no need to define any routes.Karafka#producershould operate without any problems.
Remember, if you're using Karafka without a consumer and encounter errors, ensure your consumer is set to inactive (active false), and refrain from running commands that necessitate a consumer, such as karafka server.
What will happen when a message is dispatched to a dead letter queue topic that does not exist?
When a message is dispatched to a dead letter queue (DLQ) topic that does not exist in Apache Kafka, the behavior largely depends on the auto.create.topics.enable Kafka configuration setting and the permissions of the Kafka broker. If auto.create.topics.enable is true, Kafka will automatically create the non-existent DLQ topic with one partition using the broker's default configurations, and the message will then be stored in the new topic.
On the other hand, if auto.create.topics.enable is set to false, Kafka will not auto-create the topic, and instead, an error will be raised when trying to produce to the non-existent DLQ topic. This error could be a topic authorization exception if the client doesn't have permission to create topics or unknown_topic_or_part if the topic doesn't exist and auto-creation is disabled.
In production environments, auto.create.topics.enable is often set to false to prevent unintended topic creation.
For effective management of DLQs in Kafka, we recommend using Karafka's Declarative Topics, where you declare your topics in your code. This gives you more control over the specifics of each topic, such as the number of partitions and replication factors, and helps you avoid unintended topic creation. It also aids in efficiently managing and monitoring DLQs in your Kafka ecosystem.
Below you can find an example routing that includes a DLQ declaration as well as a declarative definition of the target DLQ topic:
class KarafkaApp < Karafka::App
routes.draw do
topic 'events' do
config(
partitions: 6,
replication_factor: 3,
'retention.ms': 31 * 86_400_000 # 31 days in ms,
'cleanup.policy': 'delete'
)
consumer EventsConsumer
dead_letter_queue(
topic: 'dlq',
max_retries: 2
)
end
topic 'dlq' do
config(
partitions: 2,
replication_factor: 2,
'retention.ms': 31 * 86_400_000 # 31 days in ms,
)
# Set to false because of no automatic DLQ handling
active false
end
end
end
Why do Karafka reports lag when processes are not overloaded and consume data in real-time?
Kafka's consumer lag, which is the delay between a message being written into a Kafka topic and being consumed, is dictated not only by the performance of your consumers but also by how messages are marked as consumed in Kafka. This process of marking messages as consumed is done by committing offsets.
After processing each message or batch, consumers can commit the offset of messages that have been processed, to Kafka, to mark them as consumed. So, Kafka considers the highest offset that a consumer group has committed for a partition as the current position of the consumer group in that partition.
Now, if we look at Karafka, it follows a similar mechanism. In Karafka, by default, offsets are committed automatically in batches after a batch of messages is processed. That means if a batch is still being processed, the messages from that batch are not marked as consumed, even if some of them have already been processed, and hence those messages will still be considered as part of the consumer lag.
This lag will grow with incoming messages, which is why it's not uncommon to see a lag of the size of one or two batches, especially in topics with high data traffic.
To mitigate this situation, you can configure Karafka to prioritize latency over throughput. That means making Karafka commit offsets more frequently, even after each message, to decrease the lag and to fetch data more frequently in smaller batches. But keep in mind that committing offsets more frequently comes with the cost of reduced throughput, as each offset commit is a network call and can slow down the rate at which messages are consumed.
You can adjust this balance between latency and throughput according to your specific use case and the performance characteristics of your Kafka cluster. You could increase the frequency of committing offsets during peak load times and decrease it during off-peak times if it suits your workload pattern.
Does Kafka guarantee message processing orders within a single partition for single or multiple topics? And does this mean Kafka topics consumption run on a single thread?
Yes, within Kafka, the order of message processing is guaranteed for messages within a single partition, irrespective of whether you're dealing with one or multiple topics. However, this doesn't imply that all Kafka topics run on a single thread. In contrast, Karafka allows for multithreaded processing of topics, making it possible to process multiple topics or partitions concurrently. In some cases, you can even process data from one topic partition concurrently.
Why can I produce messages to my local Kafka docker instance but cannot consume?
There are several potential reasons why you can produce messages to your local Kafka Docker instance but cannot consume them. Here are some of the common issues and how to resolve them:
-
Network Issues: Docker's networking can cause problems if not configured correctly. Make sure your Kafka and Zookeeper instances can communicate with each other. Use the docker inspect command to examine the network settings of your containers.
-
Configuration Errors: Incorrect settings in Kafka configuration files, such as the
server.propertiesfile, could lead to this issue. Make sure that you've configured things like theadvertised.listenersproperty correctly. -
Incorrect Consumer Group: If you're consuming messages from a topic that a different consumer has already consumed in the same group, you won't see any messages. Kafka uses consumer groups to manage which messages have been consumed. You should use a new group or reset the offset of the existing group.
-
Security Protocols: If you've set up your Kafka instance with security protocols like SSL/TLS or SASL, you'll need to ensure that your consumer is correctly configured to use these protocols.
-
Offset Issue: The consumer might be reading from an offset where no messages exist. This often happens if the offset is set to the latest, but the messages were produced before the consumer started. Try consuming from the earliest offset to see if this resolves the issue.
-
Zookeeper Connection Issue: Sometimes, the issue could be a faulty connection between Kafka and Zookeeper. Ensure that your Zookeeper instance is running without issues.
Remember, these issues are common, so don't worry if you face them. Persistence and careful debugging are key in these situations.
If you're looking for a Kafka setup that doesn't require Zookeeper, consider using KRaft (KRaft is short for Kafka Raft mode), a mode in which Kafka operates in a self-managed way without Zookeeper. This new mode introduced in Kafka 2.8.0 allows you to reduce the operational complexity by eliminating the Zookeeper dependency.
What is the release schedule for Karafka and its components?
Karafka and Karafka Pro do not follow a fixed official release schedule. Instead:
-
Releases containing breaking changes are rolled out once they are fully documented, and migration guides are prepared.
-
New features are released as soon as they are ready and thoroughly documented.
-
Bug fixes that don't involve API changes are released immediately.
We prioritize bugs and critical performance improvements to ensure optimal user experience and software performance. It's worth noting that most bugs are identified, reproduced, and fixed within seven days from the initial report acknowledgment.
Can I pass custom parameters during consumer initialization?
No. In Karafka, consumers are typically created within the standard lifecycle of Kafka operations, after messages are polled but before they are consumed. This creation happens in the listener loop before work is delegated to the workers' queue.
-
You have the flexibility to modify the
#initializemethod. However, there are some nuances to note: -
You can redefine the
#initializedbut not define it with arguments, i.e.,def initialized(args)is not allowed. -
If you redefine
#initialize, you need to callsuper. -
While you can perform actions during initialization, be cautious not to overload this phase with heavy tasks or large resource loads like extensive caches. This is because the initialization happens in the listener loop thread, and any extensive process here could block message consumption.
-
If there's a minor delay (a few seconds) during initialization, it's acceptable.
Furthermore, with no arguments in the initialize method, this API structure is designed for your customization, and there are no plans to change this in the foreseeable future.
Where can I find producer idempotence settings?
They are located in the WaterDrop wiki idempotence section.
How can I control or limit the number of PostgreSQL database connections when using Karafka?
Karafka, by itself, does not manage PostgreSQL or any other database connections directly. More details about that are available here.
Why is my Karafka application consuming more memory than expected?
Several factors may lead to increased memory consumption:
-
Large Payloads: Handling large message payloads can inherently consume more memory. Remember that Karafka will keep the raw payload alongside newly deserialized information after the message is deserialized.
-
Batch Processing: This can accumulate memory usage if you're processing large batches containing bigger messages.
-
Memory Leaks: There might be memory leaks in your application or the libraries you use.
If your problems originate from batch and message sizes, we recommend looking into our Pro Cleaner API.
How can I optimize memory usage in Karafka?
-
Use Cleaner API: The Cleaner API, a part of Karafka Pro, provides a powerful mechanism to release memory used by message payloads once processed. This becomes particularly beneficial for 10KB or larger payloads, yielding considerable memory savings and ensuring a steadier memory usage pattern.
-
Adjust
librdkafkaMemory Settings: The underlying library,librdkafka, has configurations related to memory usage. Tuning these settings according to your application's needs can optimize the memory footprint. Amongst others you may be interested in looking into the following settings:fetch.message.max.bytes,queued.min.messages,queued.max.messages.kbytesandreceive.message.max.bytes -
Modify the
max_messagesValue: By adjusting themax_messagessetting to a lower value, you can control the number of messages deserialized in a batch. Smaller batches mean less memory consumption at a given time, although it might mean more frequent fetch operations. Ensure that you balance memory usage with processing efficiency while adjusting this value.
While tuning these settings can help optimize memory usage, it's essential to remember that it may also influence performance, latency, and other operational aspects of your Karafka applications. Balancing the memory and performance trade-offs based on specific application needs is crucial. Always monitor the impacts of changes and adjust accordingly.
Why am I getting No such file or directory - ps (Errno::ENOENT) from the Web UI?
If you are seeing the following error:
INFO pid=1 tid=gl9 Running Karafka 2.3.0 server
#<Thread:0x0000aaab008cc9d0 karafka-2.3.0/lib/karafka/helpers/async.rb:25 run>
# terminated with exception (report_on_exception is true):
Traceback (most recent call last):
17: lib/karafka/helpers/async.rb:28:in `block in async_call'
16: lib/karafka/connection/listener.rb:48:in `call'
15: lib/karafka/core/monitoring/monitor.rb:34:in `instrument'
14: lib/karafka/core/monitoring/notifications.rb:101:in `instrument'
13: lib/karafka/core/monitoring/notifications.rb:101:in `each'
12: lib/karafka/core/monitoring/notifications.rb:105:in `block in instrument'
11: lib/karafka/web/tracking/consumers/listeners/status.rb:18:in \
`on_connection_listener_before_fetch_loop'
10: lib/forwardable.rb:238:in `report'
9: lib/karafka/web/tracking/consumers/reporter.rb:35:in `report'
8: lib/karafka/web/tracking/consumers/reporter.rb:35:in `synchronize'
7: lib/karafka/web/tracking/consumers/reporter.rb:45:in `block in report'
6: lib/karafka/web/tracking/consumers/sampler.rb:68:in `to_report'
5: lib/karafka/web/tracking/consumers/sampler.rb:163:in `memory_total_usage'
4: lib/karafka/web/tracking/memoized_shell.rb:32:in `call'
3: open3.rb:342:in `capture2'
2: open3.rb:159:in `popen2'
1: open3.rb:213:in `popen_run'
/usr/lib/ruby/2.7.0/open3.rb:213:in `spawn': No such file or directory - ps (Errno::ENOENT)
it typically indicates that the Karafka Web UI is trying to execute the ps command but the system cannot locate it. This can occur for a few reasons:
-
The Command is Not Installed: The required command (
psin this instance) may not be installed on your system. This is less likely if you are on a standard Linux or macOS setup becausepsis usually a default command. However, minimal Docker images or other restricted environments might not have these common utilities by default. -
PATH Environment Variable: The environment in which your Web UI runs might need to set its PATH variable up correctly to include the directory where the
pscommand resides. -
Restricted Permissions: It could be a permission issue. The process/user running the Web UI may not have the necessary permissions to execute the
pscommand.
Please ensure you have all the Karafka Web UI required OS commands installed and executable. A complete list of the OS dependencies can be found here.
Can I retrieve all records produced in a single topic using Karafka?
Yes, you can consume all records from a specific topic in Karafka by setting up a new consumer for that topic or using the Iterator API.
If your primary aim is to get the count of messages, you might have to maintain a counter as you consume the messages.
If you are performing a one-time operation of that nature, Iterator API will be much better:
iterator = Karafka::Pro::Iterator.new('my_topic_name')
i = 0
iterator.each do
puts i+= 1
end
How can I get the total number of messages in a topic?
Getting the exact number of messages in a Kafka topic is more complicated due to the nature of Kafka's distributed log system and features such as log compaction. However, there are a few methods you can use:
- Using the
Karafa::Admin#read_watermark_offsetsto get offsets for each partition and summing them:
Karafka::Admin
.cluster_info
.topics
.find { |top| top[:topic_name] == 'my_topic_name' }
.then { |topic| topic.fetch(:partitions) }
.size
.times
.sum do |partition_id|
offsets = Karafka::Admin.read_watermark_offsets('my_topic_name', partition_id)
offsets.last - offsets.first
end
- Using the Iterator API and counting all the messages:
iterator = Karafka::Pro::Iterator.new('my_topic_name')
i = 0
iterator.each do
puts i+= 1
end
The first approach offers rapid results, especially for topics with substantial messages. However, its accuracy may be compromised by factors such as log compaction. Conversely, the second method promises greater precision, but it's important to note that it could necessitate extensive data transfer and potentially operate at a reduced speed.
Why am I getting Broker: Group authorization failed (group_authorization_failed) when using Admin API or the Web UI?
If you are seeing the following error
Broker: Group authorization failed (group_authorization_failed)
it most likely arises when there's an authorization issue related to the consumer group in your Kafka setup. This error indicates the lack of the necessary permissions for the consumer group to perform certain operations.
When using the Admin API or the Web UI in the context of Karafka, you are operating under the consumer groups named karafka_admin and karafka_web.
Please review and update your Kafka ACLs or broker configurations to ensure these groups have all the permissions they need.
Why am I getting an ArgumentError: undefined class/module YAML::Syck when trying to install karafka-license?
The error ArgumentError: undefined class/module YAML::Syck you're seeing when trying to install karafka-license is not directly related to the karafka-license gem. It's important to note that karafka-license does not serialize data using YAML::Syck.
Instead, this error is a manifestation of a known bug within the Bundler and the Ruby gems ecosystem. During the installation of karafka-license, other gems may also be installed or rebuilt, triggering this issue.
To address and potentially resolve this problem, you can update your system gems to the most recent version, which doesn't have this bug. You can do this by running:
gem update --system
Once you've done this, attempt to install the karafka-license gem again. If the problem persists, please get in touch with us.
Are Virtual Partitions effective in case of not having IO or not having a lot of data?
Karafka's Virtual Partitions are designed to parallelize data processing from a single partition, which can significantly enhance throughput when IO operations are involved. However, if there's minimal IO and not many messages to process, Virtual Partitions may not bring much advantage, as their primary benefit is realized in the presence of IO bottlenecks or large volumes of data. That said, even if your topics have a low average throughput, Virtual Partitions can still be a game-changer when catching up on lags. Virtual Partitions can speed up the catch-up process by processing the backlog of messages concurrently when there's a data buildup due to processing delays.
Is the "one process per one topic partition" recommendation in Kafka also applicable to Karafka?
Having one process per one topic partition in Kafka is a solid recommendation, especially for CPU-bound work. Here's why: When processing is CPU-intensive, having a single process per partition ensures that each partition gets dedicated computational resources. This prevents any undue contention or resource sharing, maximizing the efficiency of CPU utilization.
However, Karafka's design philosophy and strengths come into play in a slightly different context. Most real-world applications involve IO operations – database reads/writes, network calls, or file system interactions. These operations inherently introduce waiting times, where Karafka stands out. Being multi-threaded, Karafka allows for concurrent processing. So, even when one thread waits for an IO operation, another can actively process data. This means that for many IO-bound applications, consuming a single Karafka process from multiple partitions can be more efficient, maximizing resource utilization during IO waits.
Furthermore, Karafka introduces an additional layer of flexibility with its Virtual Partitions. Even if you're consuming data from a single topic partition, you can still leverage the power of parallelism using Virtual Partitions. They enable concurrently processing data from a singular topic partition, thus giving you the benefits of multi-threading even in scenarios with fewer actual topic partitions than processing threads.
In summary, while the "one process per partition" recommendation is sound for CPU-intensive tasks when IO operations are the predominant factor, Karafka's multi-threaded design combined with the capability of Virtual Partitions can offer a more efficient processing strategy.
Does running #mark_as_consumed increase the processing time?
When working with Karafka, the #mark_as_consumed method is designed to be asynchronous, meaning it doesn't immediately commit the offset but schedules it to be committed later. In contrast, the #mark_as_consumed! (with the exclamation mark) is synchronous and commits the offset immediately, thus having a more noticeable impact on processing time.
Given the asynchronous nature of #mark_as_consumed, its impact on the overall processing time should be marginal, less than 1%. It's optimized for performance and efficiency to ensure that offset management doesn't significantly slow down your primary processing logic.
We recommend using #mark_as_consumed for most cases because of its non-blocking nature. By default, Karafka flushes the offsets every five seconds and during each rebalances. This approach strikes a good balance between ensuring offset accuracy and maintaining high throughput in message processing.
Does it make sense to have multiple worker threads when operating on one partition in Karafka?
Yes, but only when you employ Virtual Partitions.
Without utilizing Virtual Partitions, Karafka's behavior is such that it will use, at most, as many worker threads concurrently as there are assigned partitions. This means that if you're operating on a single partition without virtualization, only one worker thread will be actively processing messages at a given time, even if multiple worker threads are available.
However, with Virtual Partitions, you can parallelize data processing even from a single partition. Virtual Partitions allow the data from one Kafka partition to be virtually "split", enabling multiple worker threads to process that data concurrently. This mechanism can be especially beneficial when dealing with IO operations or other tasks that introduce latencies, as other threads can continue processing while one is waiting.
Karafka provides a Web UI where you can monitor several metrics, including threads utilization. This gives you a clear view of how efficiently your threads are being used and can be a helpful tool in determining your setup's effectiveness.
In summary, while operating on a single partition typically uses just one worker thread, integrating Virtual Partitions in Karafka allows you to effectively utilize multiple worker threads, potentially boosting performance and throughput.
Why don't Virtual Partitions provide me with any performance benefits?
Virtual Partitions in Karafka are primarily designed to increase parallelism when processing messages, which can significantly improve throughput in the right circumstances. However, there are several scenarios where the benefits of Virtual Partitions might not be evident:
-
Not Enough Messages in Batches: If there aren't many messages within the batches you're processing, splitting these already-small batches among multiple virtual partitions won't yield noticeable performance gains. There needs to be more work to be shared among the virtual partitions, leading to underutilization.
-
No IO Involved: Virtual Partitions shine in scenarios where IO operations (e.g., database reads/writes, network calls) are predominant. These operations often introduce latencies, and with virtual partitions, while one thread waits on an IO operation, another can process data. If your processing doesn't involve IO, the parallelism introduced by virtual partitions might not offer substantial benefits.
-
Heavy CPU Computations: If the primary task of your consumer is CPU-intensive computations, then the overhead introduced by managing multiple threads might offset the benefits. CPU-bound tasks usually require dedicated computational resources, and adding more threads (even with virtual partitions) might introduce contention without increasing throughput.
-
Virtual Partitioner Assigns Data to a Single Virtual Partition: The purpose of virtual partitions is to distribute messages across multiple virtual sub-partitions for concurrent processing. If your virtual partitioner, for whatever reason, is consistently assigning messages to only one virtual partition, you effectively negate the benefits. This scenario is akin to not using virtual partitions, as all messages would be processed serially in a single "stream".
In conclusion, while Virtual Partitions can be a potent tool for improving throughput in certain scenarios, their utility is context-dependent. It's essential to understand the nature of the work being done, the volume of messages, and the behavior of the virtual partitioner to ascertain the effectiveness of virtual partitions in your setup.
What are Long Running Jobs in Kafka and Karafka, and when should I consider using them?
Despite its name, "Long Running Jobs" doesn't refer to the longevity of the underlying Ruby process (like a typical long-running Linux process). Instead, it denotes the duration of message processing. The term "Long Running Jobs" was chosen due to its popularity, even though a more accurate name might have been "Long Running Consumers".
The Long Running Jobs feature adheres to the strategy recommended by Confluent. It involves "pausing" a given partition during message processing and then "resuming" the processing of that partition once the task is completed. This ensures that as long as no rebalances occur (which would result in the partition being revoked), the poll() command can happen within the confines of the max.poll.interval.ms, preventing unwanted rebalances and errors.
However, it's essential to use this feature properly. If your regular workloads don't push the limits of max.poll.interval.ms, enabling Long Running Jobs might degrade performance. This is because pausing the partition prevents data polling, which can lead to inefficiencies in situations where message processing is typically fast.
In conclusion, while Long Running Jobs provide a powerful tool to maintain stability during extended message processing tasks, it's crucial to understand your data and processing patterns to utilize them effectively. Otherwise, you might inadvertently introduce performance bottlenecks.
What can I do to optimize the latency in Karafka?
Optimizing latency in Karafka involves tweaking various configurations and making specific architectural decisions. Here are some strategies to reduce latency:
-
Max Wait Time Adjustments: The
max_wait_timeparameter determines the maximum time the consumer will block, waiting for sufficient data to come in during a poll before it returns control. By adjusting this value, you can balance between latency and throughput. If end-to-end latency is a primary concern and your consumers want to react quickly to smaller batches of incoming messages, consider reducing the max_wait_time. A shorter wait time means the process will fetch messages more frequently, leading to quicker processing of smaller data batches. -
Batch Size Adjustments: Use the
max_messagesparameter to control the number of messages fetched in a single poll. Decreasing the batch size can reduce the time taken to process each batch, potentially reducing end-to-end latency. However, note that smaller batches can also decrease throughput, so balance is key. -
Increase Consumer Instances: Scale out by adding more consumer instances to your application. This allows you to process more messages concurrently. However, ensure you have an appropriate number of topic partitions to distribute among the consumers and monitor the utilization of Karafka processes.
-
Leverage Virtual Partitions: Virtual Partitions can be beneficial if your workload is IO-bound. You can better utilize available resources and potentially reduce processing latency by enabling further parallelization within a single partition.
-
Optimize Message Processing: Review the actual processing logic in your consumers. Consider optimizing database queries, reducing external service calls, or employing caching mechanisms to speed up processing.
Remember, the best practices for optimizing latency in Karafka will largely depend on the specifics of your use case, workload, and infrastructure. Regularly monitoring, testing, and adjusting based on real-world data will yield the best results.
What is the maximum recommended concurrency value for Karafka?
For a system with a single topic and a process assigned per partition, there's generally no need for multiple workers. 50 workers are a lot, and you might not fully utilize them because of the overhead from context switching. While Sidekiq and Karafka differ in their internals, not setting concurrency too high is a valid point for both. The same applies to the connection pool.
Are there concerns about having unused worker threads for a Karafka consumer process?
The overhead of unused worker threads is minimal because they are blocked on pop, which is efficient, so they are considered sleeping. However, maintaining an unused pool of workers can distort the utilization metric, as a scenario where all workers are always busy is regarded as 100% utilized.
How can you effectively scale Karafka during busy periods?
If you plan to auto-scale for busy periods, be aware that increasing scale might lead to reduced concurrency, especially if you are IO-intensive. With Karafka, how data is polled from Kafka can be a critical factor. For instance, thread utilization might be at most 50% even if you process two partitions in parallel because the batches you are getting consist primarily of data from a single partition. For handling of such cases, we recommend using Virtual Partitions.
What are the benefits of using Virtual Partitions (VPs) in Karafka?
Virtual Partitions allow for more concurrent consumption, which could also be achieved by increasing the partition count. However, with Karafka, VPs operate regardless of whether you poll a batch from one or many partitions. This effectively fills up workers with tasks. If you are not well-tuned for polling the right amount of data, lags might reduce concurrency. Utilizing VPs can improve performance because they can parallelize data processing for a single topic partition based on a virtual partitioner key.
What's the difference between increasing topic partition count and using VPs in terms of concurrency?
Increasing topic partition count and Karafka concurrency (so that total worker threads match the total partitions) can parallelize work in Karafka. This strategy works as long as the assignment has consistent polling characteristics. With VPs, uneven distribution impact is negligible. This is because Karafka VPs can parallelize data processing of a single topic partition based on a virtual partitioner key, compensating for any uneven distribution from polling.
How do Virtual Partitions compare to multiple subscription groups regarding performance?
Using Virtual Partitions is not the same as increasing the number of partitions. You'd need to align the number of processes and match them with partitions to achieve similar results with multiple subscription groups. However, this might increase the number of Kafka connections, potentially leading to misassignments and sub-optimal resource allocation.
What is the principle of strong ordering in Kafka and its implications?
Strong ordering in Kafka means that records are strictly ordered in the partition log. Karafka consumers are bound by this design, which acts as a limiter. As a result, the way data is polled and distributed within Karafka is influenced by this principle, which can impact concurrency and performance.
Why do I see Rdkafka::Config::ClientCreationError when changing the partition.assignment.strategy?
If you are seeing the following error:
All partition.assignment.strategy (cooperative-sticky,range)
assignors must have the same protocol type,
online migration between assignors with different protocol types
is not supported (Rdkafka::Config::ClientCreationError)
It indicates that you're attempting an online/rolling migration between two different partition.assignment.strategy assignors with different protocol types. Specifically, you might try switching between "cooperative-sticky" and "range" strategies without first shutting down all consumers.
In Kafka, all consumers within a consumer group must utilize the same partition assignment strategy. Changing this strategy requires a careful offline migration process to prevent inconsistencies and errors like the one you've encountered.
You can read more about this process here.
Is it recommended to add the waterdrop gem to the Gemfile, or just karafka and karafka-testing?
Adding the waterdrop gem to the Gemfile is unnecessary since karafka already depends on waterdrop. Karafka will ensure it selects the most compatible version of waterdrop on its own.
Can I use Karafka.producer to produce messages that will then be consumed by ActiveJob jobs?
You cannot use Karafka#producer to produce messages that will then be consumed by ActiveJob jobs. The reason is that when integrating ActiveJob with Karafka, you should use ActiveJob's scheduling API, specifically Job.perform_later, and not the Karafka producer methods.
Attempting to use the Karafka producer to send messages for ActiveJob consumption results in mismatches and errors. Karafka's ActiveJob integration has its way of handling messages internally, and how those messages look and what is being sent is abstracted away from the developer. The developer's responsibility is to stick with the ActiveJob APIs.
When you want to consume a message produced by an external source, it is not the domain of ActiveJob anymore. That would be regular Karafka consuming, which is different from job scheduling and execution with ActiveJob.
Why am I getting the Broker: Policy violation (policy_violation) error?
The Broker: Policy violation (policy_violation) error in Karafka is typically related to violating some broker-set policies or configurations.
In Karafka, this error might surface during two scenarios:
- When upgrading the Web UI using the command
karafka-web migrate. - When employing the Declarative Topics with the
karafka topics migratecommand, especially if trying to establish a topic that doesn't align with the broker's policies.
Should you encounter this error during a Web UI migration, we recommend manually creating the necessary topics and fine-tuning the settings to match your policies. You can review the settings Karafka relies on for these topics here.
On the other hand, if this error appears while using Declarative Topics, kindly review your current configuration. Ensure that it's in harmony with the broker's policies and limitations.
Why am I getting a Error querying watermark offsets for partition 0 of karafka_consumers_states error?
Error querying watermark offsets for partition 0 of karafka_consumers_states
Local: All broker connections are down (all_brokers_down)
It is indicative of a connectivity issue. Let's break down the meaning and implications of this error:
-
Main Message: The primary message is about querying watermark offsets. Watermark offsets are pointers indicating the highest and lowest offsets (positions) in a Kafka topic partition the consumer has read. The error suggests that the client is facing difficulties in querying these offsets for a particular partition (in this case, partition 0) of the karafka_consumers_states topic.
-
Local: All broker connections are down (all_brokers_down): Despite the starkness of the phrasing, this doesn't necessarily mean that all the brokers in the Kafka cluster are offline. Instead, it suggests that the Karafka client cannot establish a connection to any of the brokers responsible for the mentioned partition. The reasons could be manifold:
-
Connectivity Issues: Network interruptions between your Karafka client and the Kafka brokers might occur. This can be due to firewalls, routing issues, or other network-related blocks.
-
Broker Problems: There's a possibility that the specific broker or brokers responsible for the mentioned partition are down or facing internal issues.
-
Misconfiguration: Incorrect configurations, such as too short connection or request timeouts, could lead to premature termination of requests, yielding such errors.
-
-
Implications for Karafka Web UI:
-
If you're experiencing this issue with topics related to Karafka Web UI, it's essential to note that Karafka improved its error handling in version 2.2.2. If you're using an older version, upgrading to the latest Karafka and Karafka Web UI versions might alleviate the issue.
-
Another scenario where this error might pop up is during rolling upgrades of the Kafka cluster. If the Karafka Web UI topics have a replication factor 1, there's no redundancy for the partition data. During a rolling upgrade, as brokers are taken down sequentially for upgrades, there might be brief windows where the partition's data isn't available due to its residing broker being offline.
-
Below, you can find a few recommendations in case you encounter this error:
-
Upgrade Karafka: If you're running a version older than
2.2.2, consider upgrading both Karafka and Karafka Web UI. This might resolve the issue if it's related to previous error-handling mechanisms. -
Review Configurations: Examine your Karafka client configurations, especially timeouts and broker addresses, to ensure they're set appropriately.
-
Replication Factor: For critical topics, especially if you're using Karafka Web UI, consider setting a replication factor greater than 1. This ensures data redundancy and availability even if a broker goes down.
In summary, while the error message might seem daunting, understanding its nuances can guide targeted troubleshooting, and being on the latest software versions can often preemptively avoid such challenges.
Why Karafka is consuming the same message multiple times?
When you use Karafka and notice that the same message is being consumed multiple times, several reasons might be causing this. Here are the common reasons why you may experience the same message being processed numerous times:
-
At-Least-Once Delivery: Kafka guarantees at-least-once delivery, which means a message can be delivered more than once in specific scenarios. This is a trade-off to ensure that no messages are lost during transport. As a result, it's up to the consumer to handle duplicate messages appropriately.
-
Consumer Failures: If a consumer crashes after processing a message but before it has had a chance to commit its offset, the consumer might process the same message again upon retry.
-
Commit Interval: The interval at which the consumer commits its offset can also lead to messages being consumed multiple times. If the commit interval is too long, and there's a crash before an offset is committed, messages received since the last commit will be re-consumed.
-
Similar-Looking Messages: It's possible that the messages aren't actually duplicates, but they look alike. This can be particularly common in systems where certain events occur regularly or when there's a glitch in the producing service. It's essential to check the message key, timestamp, or other unique identifiers to ascertain if two messages are identical or have similar payloads.
-
Dead Letter Queue (DLQ) Misconfiguration with Manual Offset Management: If you're using a Dead Letter Queue in combination with manual offset management, it's possible to get into a situation where messages are consumed multiple times. If a message cannot be processed and is forwarded to the DLQ, but its offset isn't correctly committed, or the message isn't marked as consumed, the consumer may pick up the same message again upon its next iteration or restart. This behavior can especially become evident when a message consistently fails to be processed correctly, leading to it being consumed multiple times and continually ending up in the DLQ. Ensuring a proper synchronization between message processing, DLQ forwarding, and offset management is essential to avoid such scenarios.
Remember that distributed systems, Kafka included, are complex and can exhibit unexpected behaviors due to various factors. The key is to have comprehensive logging, monitoring, and alerting in place, which can provide insights into anomalies and help in their early detection and resolution.
Why do Karafka Web UI topics contain binary/Unicode data instead of text?
If you've checked Karafka Web UI topics in an alternative Kafka UI, you may notice that topics seem to contain binary/unicode data rather than plain text. It's not an oversight or an error. This design choice is rooted in our data management and transmission efficiency approach.
-
Compression for Efficient Data Transfer: Karafka Web UI compresses all data that it sends to Kafka. The primary objective behind this is to optimize data transmission by reducing the size of the messages. Smaller message sizes can lead to faster transmission rates and lower storage requirements. This is especially crucial when dealing with vast amounts of data, ensuring that Kafka remains efficient and responsive.
-
Independent Compression without External Dependencies: We understand the significance of maintaining a lightweight, hassle-free setup for our users. We chose Zlib for data compression - it comes bundled with every Ruby version. This means there's no need to rely on third-party libraries or go through configuration changes to your Kafka cluster to use Karafka Web UI.
By choosing Zlib, we've simplified it for the end user. You won't have to grapple with additional compression settings or worry about compatibility issues. Zlib's ubiquity in Ruby ensures that Karafka remains user-friendly without compromising data transmission efficiency.
While the binary/Unicode representation in the Karafka Web UI topics might seem unconventional at first glance, it's a strategic choice to streamline data transfers and keep the setup process straightforward. Karafka Web UI Explorer recognizes this format and will decompress it if you need to inspect this data.
Can I use same Karafka Web UI topics for multiple environments like production and staging?
No. More details about that can be found here.
Does Karafka plan to submit metrics via a supported Datadog integration, ensuring the metrics aren't considered custom metrics?
No, Karafka does not have plans to submit metrics through a dedicated Datadog integration that ensures these metrics are classified as non-custom. While Karafka has an integration with Datadog, the metrics from this integration will be visible as custom metrics.
The reason for this approach is grounded in practicality and long-term maintainability. As with any software, weighing the benefits against the maintenance cost and the commitment involved is essential. While it might seem feasible to align certain features or integrations with the current framework changes, it could introduce challenges if the release cycle or external dependencies were to change.
To put it in perspective:
-
Maintenance Cost & Commitment: Introducing such a feature would mean an ongoing commitment to ensuring it works seamlessly with every subsequent update or change to Karafka or Datadog. It's imperative to consider the long-term cost of this commitment.
-
External Dependencies: If Datadog's release cycle or features were to evolve unexpectedly, it could lead to complexities in ensuring smooth integration. This introduces an external dependency that's out of Karafka's direct control.
-
Ecosystem Benefits: While such integrations can offer added value, assessing if their benefits are substantial enough to justify the effort and potential challenges is vital. In this case, the perceived benefit to the ecosystem seems insignificant.
In conclusion, while Karafka recognizes the value of integrations and continually seeks to enhance its capabilities, it's essential to strike a balance that ensures the software remains efficient, maintainable, and free from unnecessary complexities.
How can I make Karafka not retry processing, and what are the implications?
If you make Karafka not retry, the system will not attempt retries on errors but will continue processing forward. You can achieve this in two methods:
- Manual Exception Handling: This involves catching all exceptions arising from your code and choosing to ignore them. This means the system doesn't wait or retry; it simply moves to the next task or message.
def consume
messages.each do |message|
begin
persist(message)
# Ignore any errors and just log them
rescue StandardError => e
ErrorTracker.notify(e)
end
mark_as_consumed(message)
end
end
- Using Enhanced DLQ Capabilities: With this method, messages will be moved to the Dead Letter Queue (DLQ) immediately, without retrying them, and an appropriate backoff policy will be invoked, preventing you from further overloading your system in case of external resources' temporary unavailability.
class KarafkaApp < Karafka::App
routes.draw do
topic :orders_states do
consumer OrdersStatesConsumer
# This setup will move broken messages to the DLQ, backoff and continue
dead_letter_queue(
topic: 'dead_messages',
max_retries: 0
)
end
end
end
class OrdersStatesConsumer < ApplicationConsumer
def consume
# No need to handle errors manually, if `#persist` fails,
# Karafka will pause, backoff and retry automatically and
# will move the failed messages to `dead_messages` topic
messages.each do |message|
persist(message)
mark_as_consumed(message)
end
end
end
However, it's essential to be aware of the potential risks associated with these approaches. In the first method, there's a possibility of overloading temporarily unavailable resources, such as databases or external APIs. Since there is no backoff between a failure and the processing of the subsequent messages, this can exacerbate the problem, further straining the unavailable resource. To mitigate this, using the #pause API is advisable, which allows you to pause the processing manually. This will give strained resources some breathing room, potentially preventing more significant system failures.
We faced downtime due to a failure in updating the SSL certs. How can we retrieve messages that were sent during this downtime?
If the SSL certificates failed on the producer side, the data might not have been produced to Kafka in the first place. If your data is still present and not compacted due to the retention policy, then you should be able to read it.
You can read from the last known consumed offset by seeking this offset + 1 or use Karafka Iterator API or Web UI Explorer to view those messages.
How can the retention policy of Kafka affect the data sent during the downtime?
If your data retention policy has compacted the data, then the data from the downtime period might no longer be available.
Is it possible to fetch messages per topic based on a specific time period in Karafka?
Yes, in newer versions of Karafka, you can use the Iterator API or the Enhanced Web UI to perform time-based offset lookups.
Where can I find details on troubleshooting and debugging for Karafka?
You can refer to this documentation page.
Does the open-source (OSS) version of Karafka offer time-based offset lookup features?
Only partially. Karafka OSS allows you to use the consumer #seek method to navigate to a specific time in the subscribed topic partition. Still, you cannot do it outside the consumer subscription flow.
I see a "JoinGroup error: Broker: Invalid session timeout" error. What does this mean, and how can I resolve it?
This error occurs when a consumer tries to join a consumer group in Apache Kafka but provides an invalid session timeout value. The session timeout is when the broker waits after losing contact with a consumer before considering it gone and starting a rebalance of the consumer group. If this value is too low or too high (outside the broker's allowed range), the broker will reject the consumer's request to join the group.
-
Check the configuration of your consumer to ensure you're setting an appropriate session timeout value.
-
Ensure that the value lies within the broker's allowable range, which you can find in the broker's configuration.
-
Adjust the consumer's session timeout value to be within this range and try reconnecting.
Remember to make sure that the timeout value you set is suitable for your use case, as it can affect the responsiveness of your consumer group to failures.
The "Producer Network Latency" metric in DD seems too high. Is there something wrong with it?
In this case, the high number you see is in microseconds, not milliseconds. To put it into perspective, 1 millisecond is 1,000 microseconds. So, if you see a metric like 15k, it's just 0.015 of a second. Always ensure you're reading the metrics with the correct scale in mind.
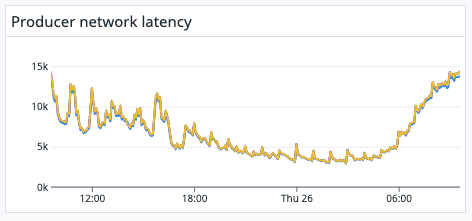
What is the purpose of the karafka_consumers_reports topic?
The karafka_consumers_reports topic is an integral component of the Karafka Web UI. Its primary purpose is to store information related to the processes and operations of the Karafka application. This, along with other Web UI topics, is designed to capture and provide data. By doing so, Karafka Web UI eliminates the need for an external third-party database, allowing it to leverage Kafka as its primary source of information.
Can I use Karafka.producer from within ActiveJob jobs running in the karafka server?
Yes, any ActiveJob job running in the karafka server can access and use the Karafka.producer.
Do you recommend using the singleton producer in Karafka for all apps/consumers/jobs in a system?
Yes, unless you use transactions. In that case, you can use a connection pool. Using a long-living pool is fine.
Is it acceptable to declare short-living producers in each app/jobs as needed?
It's not recommended to have a short-lived producer or per job class (e.g., 20 job classes and 20 producers). Instead, create producers that vary with usage or settings, not per class.
What are the consequences if you call a #produce_async and immediately close the producer afterward?
No consequences. WaterDrop will wait until it is delivered because it knows the internal queue state.
Is it problematic if a developer creates a new producer, calls #produce_async, and then closes the producer whenever they need to send a message?
Yes, this is problematic. WaterDrop producers are designed to be long-lived. Creating short-lived Kafka connections can be expensive.
Could the async process remain open somewhere, even after the producer has been closed?
No.
Could a single producer be saturated, and if so, what kind of max rate of message production would be the limit?
This depends on factors like your cluster, number of topics, number of partitions, and how and where you send the messages. However, you can get up to 100k messages per second from a single producer instance.
How does the batching process in WaterDrop works?
Waterdrop and librdkafka batch messages under the hood and dispatch in groups. There's an internal queue limit you can set. If exceeded, a backoff will occur.
Can you control the batching process in WaterDrop?
It auto-batches the requests. If the queue is full, a throttle will kick in. You can also configure WaterDrop to wait on queue full errors. The general approach is to dispatch in batches (or in transactions) and wait on batches or finalize a transaction.
Is it possible to exclude karafka-web related reporting counts from the web UI dashboard?
No.
Can I log errors in Karafka with topic, partition, and other consumer details?
Yes, it is possible to log errors with associated topic, partitions, and other information in Karafka, but it depends on the context and type of the event. Karafka's error.occurred event is used for logging any errors, including errors not only within your consumption code but also in other application areas due to its asynchronous nature.
Key Points to Remember:
-
Check Event Type: Always examine the
event[:type]to understand the nature of the error. This helps determine whether the error is related to message consumption and will have the relevant topic and partition information. -
Errors Outside Consumption Flow: There can be instances where the caller is a consumer, but the error occurs outside the consumption flow. In such cases, the necessary details might not be available.
The rationale for this Approach:
Karafka provides a single, simplified API for all error instrumentation. This design choice aims to streamline error handling across different parts of the application, even though some errors may only sometimes have the complete contextual information you are looking for.
Checking the event[:type] and recognizing the role of the event[:caller] will guide you in determining whether the necessary details are available for a specific error. Remember, due to the asynchronous nature of Karafka, not all errors will have associated topic and partition details.
Why did our Kafka consumer start from the beginning after a 2-week downtime, but resumed correctly after a brief stop and restart?
This issue is likely due to the offsets.retention.minutes setting in Kafka. Kafka deletes the saved offsets if a consumer is stopped for longer than this set retention period (like your 2-week downtime). Without these offsets, the consumer restarts from the beginning. However, the offsets are still available for shorter downtimes (like your 15-minute test), allowing the consumer to resume from where it left off.
You can read more about this behavior here.
Why am I experiencing a load error when using Karafka with Ruby 2.7, and how can I fix it?
If you're experiencing a load error with Karafka on Ruby 2.7, it's due to a bug in Bundler. To fix this:
- Install Bundler v2.4.22: Run
gem install bundler -v 2.4.22 --no-document. - Update RubyGems to v3.4.22: Run
gem update --system 3.4.22 --no-document.
Note: Ruby 2.7 is EOL and no longer supported. For better security and functionality, upgrading to Ruby 3.0 or higher is highly recommended.
Why am I getting +[NSCharacterSet initialize] may have been in progress in another thread when fork() error when forking on macOS?
When running a Rails application with Karafka and Puma on macOS, hitting the Karafka dashboard or endpoints can cause crashes with an error related to fork() and Objective-C initialization. This is especially prevalent in Puma's clustered mode.
The error message is usually along the lines of:
objc[<pid>]: +[NSCharacterSet initialize]
may have been in progress in another thread when fork() was called.
We cannot safely call it or ignore it in the fork() child process.
Crashing instead. Set a breakpoint on objc_initializeAfterForkError to debug.
The issue concerns initializing specific libraries or components in a macOS environment, particularly in a multi-process environment. It may involve Objective-C libraries being initialized unsafely after a fork, which macOS does not allow.
There are a few potential workarounds:
-
Setting the environment variable
OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YESwhen running Puma. This is not ideal as it might introduce other issues. -
Creating an instance of
Rdkafkathat would force-load all the needed components before the fork as follows:
require 'rdkafka'
before_fork do
# Make sure to configure it according to your cluster location
config = {
'bootstrap.servers': 'localhost:9092'
}
# Create a new instance and close it
# This will load or dynamic components on macOS
# Not needed under other OSes, so not worth running
if RUBY_PLATFORM.include?('darwin')
::Rdkafka::Config.new(config).admin.close
end
end
It is worth pointing out that this is not a Karafka-specific issue. While the issue manifests when using Karafka with Puma, it's more related to how macOS handles forking with Objective-C libraries and specific initializations post-fork.
How does Karafka handle messages with undefined topics, and can they be routed to a default consumer?
Karafka Pro's Routing Patterns feature allows for flexible routing using regular expressions, automatically adapting to dynamically created Kafka topics. This means Karafka can instantly recognize and consume messages from new topics without extra configuration, streamlining the management of topic routes. For optimal use and implementation details, consulting the their documentation is highly recommended.
What happens if an error occurs while consuming a message in Karafka? Will the message be marked as not consumed and automatically retried?
In Karafka's default flow, if an error occurs during message consumption, the processing will pause at the problematic message, and attempts to consume it will automatically retry with an exponential backoff strategy. This is typically effective for resolving transient issues (e.g., database disconnections). However, it may not be suitable for persistent message-specific problems, such as corrupted JSON. In such cases, Karafka's Dead Letter Queue feature can be utilized. This feature allows a message to be retried several times before it's moved to a Dead Letter Queue (DLQ), enabling the process to continue with subsequent messages. More information on this can be found in the Dead Letter Queue Documentation.
What does setting the initial_offset to earliest mean in Karafka? Does it mean the consumer starts consuming from the earliest message that has not been consumed yet?
The initial_offset setting in Karafka is relevant only during the initial start of a consumer in a consumer group. It dictates the starting point for message consumption when a consumer group first encounters a topic. Setting initial_offset to earliest causes the consumer to start processing from the earliest available message in the topic (usually the message with offset 0, but not necessarily). Conversely, setting it to latest instructs the consumer to begin processing the next message after the consumer has started. It's crucial to note that initial_offset does not influence the consumption behavior during ongoing operations. For topics the consumer group has previously consumed, Karafka will continue processing from the last acknowledged message, ensuring that no message is missed or processed twice.
Why is the "Dead" tab in Web UI empty in my Multi App setup?
If the "Dead" tab in your Karafka Web UI is empty, especially within a multi-app setup, there are two primary reasons to consider based on the DLQ routing awareness section:
-
DLQ Topic References Not Configured: The most likely reason is that the Dead Letter Queue (DLQ) topics have yet to be explicitly referenced in the
karafka.rbconfiguration of the application serving the Web UI. Without these references, the Web UI lacks the context to identify which topics are designated as DLQs. This means that even if messages are being routed to a DLQ, the Web UI will not display these topics under the "Dead" tab because it does not recognize them as such. Ensure that all DLQ topics are correctly defined in the routing configuration of the Karafka application hosting the Web UI to resolve this issue. You can read more about this issue here. -
Non-existent DLQ Topic: Another possibility is that the DLQ topic itself does not exist. In scenarios where messages fail processing and are supposed to be routed to a DLQ, the absence of the designated DLQ topic would result in no messages being stored or visible in the "Dead" tab. This could occur if the DLQ topic were never created in Kafka or if there needs to be a misconfiguration in the topic name within your application's settings, leading to a mismatch between where Karafka attempts to route failed messages and the actual topic structure in Kafka.
To troubleshoot and resolve this issue, you should:
-
Verify DLQ Topic Configuration: Double-check your
karafka.rbfile to ensure that DLQ topics are correctly referenced within the routing configuration. Ensure the topic names match the expected DLQ topics in your Kafka setup. -
Check Kafka for DLQ Topic Existence: Ensure that the DLQ topics are created and exist within your Kafka cluster. You can use Kafka command-line tools or a Kafka management UI to list topics and verify their existence.
-
Review Topic Naming Consistency: Ensure consistency in topic naming across your Kafka configuration and Karafka setup. Any discrepancy could lead to failed message routing.
What causes a "Broker: Policy violation (policy_violation)" error when using Karafka, and how can I resolve it?
The Broker: Policy violation (policy_violation) error in Karafka typically occurs due to exceeding Kafka's quota limitations or issues with Access Control Lists (ACLs). This error indicates that an operation attempted by Karafka has violated the policies set on your Kafka cluster. To resolve this issue, follow these steps:
-
ACL Verification: Ensure that your Kafka cluster's ACLs are configured correctly. ACLs control the permissions for topic creation, access, and modification. If ACLs are not properly set up, Karafka might be blocked from performing necessary operations.
-
Quota Checks: Kafka administrators can set quotas on various resources, such as data throughput rates and the number of client connections. If Karafka exceeds these quotas, it may trigger a
policy_violationerror. Review your Kafka cluster's quota settings to ensure they align with your usage patterns. -
Adjust Configurations: Make the necessary adjustments based on your findings from the ACL and quota checks. This might involve modifying ACL settings to grant appropriate permissions or altering quota limits to accommodate your application's needs.
Why do I see hundreds of repeat exceptions with pause_with_exponential_backoff enabled?
When pause_with_exponential_backoff is enabled, the timeout period for retries doubles after each attempt, but this does not prevent repeated exceptions from occurring. With pause_max_timeout set to the default 30 seconds, an unaddressed exception can recur up to 120 times per hour. This frequent repetition happens because the system continues to retry processing until the underlying issue is resolved.
Does Karafka store the Kafka server address anywhere, and are any extra steps required to make it work after changing the server IP/hostname?
Karafka does not persistently store the Kafka server address or cache any information about the cluster's IP addresses or hostnames. The issue you're experiencing is likely due to your cluster setup, as Karafka performs discovery based on the initial host address provided in the config.kafka setup. Upon startup, Karafka uses this initial address to discover the rest of the cluster. Ensure your configurations are correctly updated across your Docker setup, and restart the process to clear any temporary caches. Karafka has no intrinsic knowledge of AWS hosts or any hardcoded cluster information; it relies entirely on the configuration provided at startup.
What should I do if I encounter a loading issue with Karafka after upgrading Bundler to version 2.3.22?
This issue is typically caused by a gem conflict related to the Thor gem version. It has been observed that Thor version 1.3 can lead to errors when loading Karafka. The problem is addressed in newer versions of Karafka, which no longer depend on Thor. To resolve the issue:
-
Ensure you're using a version of Thor earlier than
1.3, as recommended by community members. -
Upgrade to a newer version of Karafka that does not use Thor. It's recommended to upgrade to at least version
2.2.8for stability and to take advantage of improvements.
Is there a good way to quiet down bundle exec karafka server extensive logging in development?
Yes. You can set log_polling to false for the LoggerListener as follows:
Karafka.monitor.subscribe(
Karafka::Instrumentation::LoggerListener.new(
# When set to false, polling will not be logged
# This makes logging in development less extensive
log_polling: false
)
)
How can I namespace messages for producing in Karafka?
You can namespace messages topics for producing automatically in Karafka by leveraging the middleware in WaterDrop to transform the destination topics.
Why am I getting the all topic names within a single consumer group must be unique error when changing the location of the boot file using KARAFKA_BOOT_FILE?
You're seeing this error most likely because you have moved the karafka.rb file to a location that is automatically loaded, meaning that it is loaded and used by the Karafka framework and also by the framework of your choice. In the case of Ruby on Rails, it may be so if you've placed your karafka.rb, for example, inside the config/initializers directory.
Why Is Kafka Using Only 7 Out of 12 Partitions Despite Specific Settings?
The issue you're encountering typically arises due to how Kafka calculates partition assignments when a key is provided. Kafka uses a hashing function (CRC32 by default) to determine the partition for each key. This function might not evenly distribute keys, especially if the key space is not large or diverse enough.
As discussed, since the partitioner was configured to use the first argument (carrier name) as the key, the diversity and number of unique carrier names directly influence the distribution across partitions. If some carrier names hash the same partition, you will see less than 12 partitions being used.
Why does the Dead Letter Queue (DLQ) use the default deserializer instead of the one specified for the original topic in Karafka?
When a message is piped to the DLQ, if you decide to consume data from the DLQ topic, it defaults to using the default deserializer unless explicitly specified otherwise for the DLQ topic. This behavior occurs because the deserializer setting is tied to specific topics rather than the consumer. If you require a different deserializer for the DLQ, you must define it directly on the DLQ topic within your routing setup. This setup ensures that each topic, including the DLQ, can have unique processing logic tailored to its specific needs.
class KarafkaApp < Karafka::App
routes.draw do
topic :orders_states do
consumer OrdersStatesConsumer
deserializer SpecificDeserializer.new
dead_letter_queue(
topic: :failed_orders_dlq,
max_retries: 2
)
end
topic :failed_orders_dlq do
consumer FailedOrdersRecoveryConsumer
deserializer SuperSpecificDeserializer.new
end
end
end
What should I consider when manually dispatching messages to the DLQ in Karafka?
When manually dispatching a message to the DLQ in Karafka, it's essential to understand that the dispatch action itself only moves the message to the DLQ and does not mark it as consumed. If your intention is to prevent further processing of the original message and to avoid halting the offset commitment, you need to explicitly mark the message as consumed. This can be crucial in maintaining the flow of message processing and ensuring that message consumption offsets are correctly committed.
How can I ensure that my Karafka consumers process data in parallel?
Karafka utilizes multiple threads to consume and process data, allowing operations across multiple partitions or topics to occur in parallel. However, the perception of sequential processing might occur due to several factors, such as configuration, scale, and system design. To enhance parallel processing:
-
Consumer Groups: If you require completely independent processing streams, utilize multiple consumer groups. Each consumer group manages its connection, polling, and data handling.
-
Subscription Groups: You can set up multiple subscription groups within a single consumer group. Each subscription group can subscribe to different topics, enabling parallel data fetching within the same consumer group.
-
Configuration: Ensure your settings like
max.partition.fetch.bytesand `max.poll.records are optimized based on your message size and throughput requirements. This helps in fetching data efficiently from multiple partitions.
By properly configuring consumer and subscription groups and optimizing Kafka connection settings, you can achieve effective parallel data processing in Karafka.
How should I handle the migration to different consumer groups for parallel processing?
Migrating to different consumer groups to facilitate parallel processing involves a few considerations:
-
Offset Management: When introducing new consumer groups, they typically consume from the latest or earliest offset by default. This behavior can be managed using the
Karafka::Admin#seek_consumer_groupfeature in newer Karafka releases, allowing you to specify the starting offset for each new consumer group. -
Consumer Group Configuration: Implementing multiple consumer groups or adjusting subscription groups within a consumer group can help distribute the workload more evenly. This setup minimizes the risk of any one consumer group becoming a bottleneck.
-
Testing in Staging: Before rolling out changes in production, thoroughly test the new consumer group configurations in a staging environment. This helps identify any potential issues with offset handling or data processing delays.
What are the best practices for setting up consumer groups in Karafka for optimal parallel processing?
Best practices for setting up consumer groups in Karafka to optimize parallel processing include:
Best practices for setting up consumer groups in Karafka to optimize parallel processing include:
-
Dedicated Consumer Groups: Allocate a consumer group for each logically separate function within your application. This isolation helps in managing the processing load and minimizes the impact of rebalances.
-
Subscription Group Utilization: Within a consumer group, use subscription groups to handle different topics or partitions. This setup provides flexibility in managing which part of your application handles specific data streams.
-
Resource Allocation: Ensure that each consumer group and subscription group is allocated adequate resources such as CPU and memory to handle the expected workload. This allocation prevents performance bottlenecks due to resource contention.
-
Monitoring and Scaling: Regularly monitor the performance of your consumer groups and adjust their configurations as necessary. Utilize Karafka’s monitoring tools to track processing times, throughput, and lag to make informed scaling decisions.
Implementing these best practices will help you fully leverage Karafka’s capabilities for parallel processing, enhancing the throughput and efficiency of your Kafka data pipelines.
How can I set up custom, per-message tracing in Karafka?
Implementing detailed, per-message tracing in Karafka involves modifying the monitoring and tracing setup to handle individual messages. This setup enhances visibility into each message's processing and integrates seamlessly with many tracing products like DataDog.
Here's how you can set up this detailed tracing step-by-step:
- Register Custom Event
Begin by registering a custom event in Karafka for each message processed. This is essential to create a unique event for the monitoring system to trigger on each message consumption.
# This will trigger before consumption to start trace
Karafka.monitor.notifications_bus.register_event('consumer.consume.message')
# This will trigger after consumption to finish trace
Karafka.monitor.notifications_bus.register_event('consumer.consumed.message')
Registering a custom event allows you to define specific behavior and tracking that aligns with your application's needs, distinct from the batch processing default.
- Instrument with Karafka Monitor
Once the event is registered, use Karafka’s monitor to instrument it. This step does not involve actual data processing but sets up the framework for tracing.
class OrdersStatesConsumer < ApplicationConsumer
def consume
messages.each do |message|
Karafka.monitor.instrument('consumer.consume.message', message: message)
consume_one(message)
Karafka.monitor.instrument('consumer.consumed.message', message: message)
# Mark as consumed after each successfully processed message
mark_as_consumed(message)
end
end
def consume_one(message)
# Your logic goes here
end
end
- Build a Custom Tracing Listener
Modify or build a new tracing listener that specifically handles the per-message tracing.
class MyTracingListener
def on_consumer_consume_message(event)
# Start tracing here...
end
def on_consumer_consumed_message(event)
# Finalize trace when message is processed
end
def on_error_occurred(event)
# Do not forget to finalize also on errors if trace available
end
end
Karafka.monitor.subscribe(MyTracingListener.new)
When Karafka reaches max.poll.interval.ms time and the consumer is removed from the group, does this mean my code stops executing?
No, your code does not stop executing when Karafka reaches the max.poll.interval.ms time, and the consumer is removed from the group. Karafka does not interrupt the execution of your code. Instead, it reports an error indicating that the maximum poll interval has been exceeded, like this:
Data polling error occurred: Application maximum poll interval (300000ms) exceeded by 348ms
Your code will continue to execute until it is complete. However, marking messages as consumed after this error will not be allowed.
Which component is responsible for committing the offset after consuming? Is it the listener or the worker?
In the Karafka framework, the worker contains a consumer that handles the offset committing. The consumer within the worker sends a commit request to the underlying C client instance. This process involves the worker's consumer storing the offset to be saved, which then goes through a C thread for the actual commit operation. It's important to note that Karafka commits offsets asynchronously by default.
Can the on_idle and handle_idle methods be changed for a specific consumer?
No. The on_idle and handle_idle methods are part of Karafka's internal API and are not editable. Internal components use these methods for periodic jobs within the Karafka framework. They are not intended for user modification or are not part of the official public API. If you need to execute a specific method when the consumer is idle or when the last message from the topic has been consumed, you should use Karafka's periodic jobs feature. This feature is designed to handle such use cases effectively.
Is Multiplexing an alternative to running multiple Karafka processes but using Threads?
No, multiplexing serves a different use case. It's primarily for handling IO-bound operations, dealing with connections, and polling rather than work distribution and execution. Multiplexing is specifically for connection multiplexing within the same topic. Tuning Karafka processing is complex due to its flexibility. It can be influenced by the nature of your processing, deployment type, and data patterns, and there is no one best solution.
Is it possible to get watermark offsets from inside a consumer class without using Admin?
You can get watermark offsets and other metrics directly from within a consumer class using Karafka's Inline Insights. This feature provides a range of metrics, including watermark offsets, without using the Admin API. For more details, refer to the Inline Insights documentation.
Why are message and batch numbers increasing even though I haven't sent any messages?
Karafka Web-UI uses Kafka to report the status of Karafka processes, sending status messages every 5 seconds by default. This is why you see the message and batch numbers increasing. The web UI uses these Kafka messages to show the status of the processes.
Karafka processes messages in batches, and the value you see indicates how many batches have been processed, even if a batch contains only one message.
To view the actual payload of messages sent from producer to consumer, you can use the Karafka Explorer.
What does config.ui.sessions.secret do for the Karafka Web UI? Do we need it if we are using our authentication layer?
The config.ui.sessions.secret configuration is used for CSRF (Cross-Site Request Forgery) protection in the Karafka Web UI. Even if you use your own authentication layer, you must set this configuration. It's not critical, but it needs to be set.
Since you have your own authentication, this configuration becomes secondary, though it still provides an additional layer of protection. Ensure that the secret is consistent across all deployment instances, with one value per environment.
Is there middleware for consuming messages similar to the middleware for producing messages?
Due to the complexity of the data flow, there are only a few middleware layers for consuming messages in Karafka, but several layers can function similarly. These are referred to as "strategies" in Karafka, and there are around 80 different combinations available.
Karafka provides official APIs to alter the consumption and processing flow at various key points. The most notable among these is the Filtering API, which, despite its name, offers both flow control and filtering capabilities. This API spans from post-polling to post-batch execution stages.
One of the key strengths of Karafka is its support for pluggable components. These components can be tailored to meet your specific requirements, offering a high degree of customization. Detailed information about these components and their configurations can be found in the Karafka documentation.
Can we change the name of Karafka's internal topic for the Web UI?
Yes, you can change the name of Karafka's internal topic for the Web UI.
For instance, if you need to prepend a unique combination before the topic's name, such as 12303-karafka_consumers_states, this is feasible.
Detailed instructions on how to configure this can be found in the Karafka documentation under this section.
Is there a way to control which pages we show in the Karafka Web UI Explorer to prevent exposing PII data?
Yes. Karafka provides an API for visibility filtering, which allows you to decide what to display, and whether options to download payloads and JSON versions should be usable. Additionally, you can sanitize certain fields from being presented.
For detailed information, refer to the Pro Enhanced Web UI Policies documentation.
What does the strict_topics_namespacing configuration setting control?
The strict_topics_namespacing configuration in Karafka enforces consistent naming for topics by ensuring they use either dots (.) or underscores (_) but not a mix of both in a topic name. This validation helps prevent inconsistencies in topic names, which is crucial because inconsistent namespacing can lead to issues like Kafka metrics reporting name collisions. Such collisions occur because Kafka uses these characters to structure metric names, and mixing them can cause metrics to overlap or be misinterpreted, leading to inaccurate monitoring and difficulties in managing Kafka topics. By enabling strict_topics_namespacing, you ensure that all topic names follow a uniform pattern, avoiding these potential problems. This validation can be turned off by setting config.strict_topics_namespacing to false if your environment does not require uniform naming.
Does librdkafka queue messages when using Waterdrop's #produce_sync method?
Yes, librdkafka does queue messages internally. Even when WaterDrop does not use additional queues to accumulate messages before passing them to librdkafka, librdkafka maintains an internal queue. This queue is used to build message batches that are dispatched to the appropriate brokers.
By default, librdkafka flushes this internal queue every 5 milliseconds. This means that when you call #produce_sync, the message is moved to librdkafka's internal queue, flushed within this 5ms window. The synchronous produce call waits for the result of this flush.
Waterdrop also manages buffer overflows for this internal queue in synchronous and asynchronous modes. Depending on the Waterdrop configuration, it will handle retries appropriately in case of overflows or raise an error.
How reliable is the Waterdrop async produce? Will messages be recovered if the Karafka process dies before producing the message?
The Waterdrop async produce is not reliable in terms of message recovery if the Karafka process dies before producing the message. If the process is killed while a message is being sent to Kafka, the message will be lost. This applies to both asynchronous and synchronous message production. This, however, is not specific to Kafka. SQL database transactions in the middle of being sent will also be interrupted, as will any other type of communication that did not finish.
For improved performance and reliability, you might want to consider using the Karafka transactional producer. This feature can enhance the efficiency and robustness of your message production workflow.
Will WaterDrop start dropping messages upon librdkafka buffer overflow?
By default, WaterDrop will not drop messages when the librdkafka buffer overflows. Instead, it has a built-in mechanism to handle such situations by backing off and retrying the message production.
When WaterDrop detects that the librdkafka queue is full, an exception will not be immediately raised. Instead, it waits for a specified amount of time before attempting to resend the message. This backoff period allows librdkafka to dispatch previously buffered messages, freeing up space in the queue. During this waiting period, an error is logged in the error.occurred notification pipeline. While this error is recoverable, frequent occurrences might indicate underlying issues that need to be addressed.
If the queue remains full even after the backoff period, WaterDrop will continue to retry sending the message until there is enough space. This retry mechanism ensures that messages are not lost.
This behavior can be aligned by changing appropriate configuration settings.
How can I handle dispatch_to_dlq method errors when using the same consumer for a topic and its DLQ?
If you use the same consumer for a particular topic and its Dead Letter Queue (DLQ), you might encounter an issue where the dispatch_to_dlq method is unavailable in the DLQ context. This can lead to errors if the method is called again during DLQ reprocessing.
In Karafka, different consumer instances may operate in different contexts. Specifically, the DLQ context does not have access to DLQ-specific methods because these methods are injected only for the original topic consumer context. This ensures that specific methods are not used outside their intended context, maintaining a clean and safe API.
To handle this, you can use a guard to check whether the #dispatch_to_dlq method is available before calling it. Here are a couple of approaches:
- Check for Method Availability:
You can use the #respond_to? method to check if dispatch_to_dlq is available before calling it.
if respond_to?(:dispatch_to_dlq)
dispatch_to_dlq
else
# Handle the error or reprocess logic here
end
- Differentiate Using Topic Reference:
Alternatively, you can check if the consumer is processing a DLQ topic by using the topic.dead_letter_queue? method. This method returns true if the current topic has DLQ enabled but will be false when processing the DLQ itself.
if topic.dead_letter_queue?
# This is the original topic, so `dispatch_to_dlq` is safe to use
dispatch_to_dlq
else
# This is the DLQ topic, handle accordingly
# Handle the error or reprocess logic here
end
When using the same consumer for both a topic and its DLQ in Karafka, ensure that you handle method availability appropriately to avoid errors. Using guards like checking the topic context with topic.dead_letter_queue? can help maintain robustness and prevent unexpected exceptions during reprocessing.
What should I do if I encounter the Broker: Not enough in-sync replicas error?
This error indicates that there are not enough in-sync replicas to handle the message persistence. Here's how to address the issue:
-
Check Cluster Size and Configuration: Ensure that your Kafka cluster has enough brokers to meet the required replication factor for the topics. If your replication factor is set to
3, you need at least3brokers. -
Increase Broker Storage Size: If your brokers are running out of storage space, they will not be able to stay in sync. Increasing the storage size, if insufficient, can help maintain enough in-sync replicas.
-
Check the Cluster's
min.insync.replicasSetting: Ensure that themin.insync.replicassetting in your Kafka cluster is not higher than the replication factor of your topics. Ifmin.insync.replicasis set to a value higher than the replication factor of a topic, this error will persist. In such cases, manually adjust the affected topics' replication factor to match the requiredmin.insync.replicasor recreating the topics with the correct replication factor.
By following these steps, you should be able to resolve the "Broker: Not enough in-sync replicas" error and ensure your Kafka cluster is correctly configured to handle the required replication.
Is there any way to measure message sizes post-compression in Waterdrop?
Waterdrop metrics do not provide direct measurements for post-compression message sizes.
To estimate message sizes post-client compression, you can use the txmsgs and txbytes metrics in Waterdrop instrumentation. These metrics provide information per topic partition and can give you a reasonable estimate of the message sizes after compression if the compression occurs on the client side.
What happens to a topic partition when a message fails, and the exponential backoff strategy is applied? Is the partition paused during the retry period?
Yes, when a message fails on a specific topic partition and the exponential backoff strategy is applied, that partition is effectively paused during the retry period. This ensures strong ordering, which is a key guarantee of Karafka. If you want to bypass this behavior, you can configure a DLQ with delayed processing, allowing you to manage retries without pausing the partition.
How can Virtual Partitions help with handling increased consumer lag in Karafka?
Virtual Partitions (VPs) can significantly improve the parallelism of message consumption in Karafka. Suppose you have a topic with 6 partitions and are running 6 processes (each with 1 partition assigned). In that case, the parallelism is limited to one thread per partition. Using VPs, you can further split the data from each partition into multiple virtual partitions, allowing more threads to process the data concurrently. For example, with 5 virtual partitions per physical partition, you can achieve 30 virtual partitions, increasing the throughput and reducing the lag more efficiently.
Is scaling more processes a viable alternative to using Virtual Partitions?
Scaling processes can help up to the number of partitions available. For instance, with 6 partitions, you can scale up to 6 processes. Beyond that, additional processes will not contribute to processing since Kafka consumer groups assign one partition per process. Each process will run a single thread per partition, which can become IO-constrained, especially with tasks like bulk inserts into Timescale. In contrast, using VPs allows better utilization of threads within the same partitions, providing a cost-effective performance boost without needing to scale processes proportionally.
What is the optimal strategy for scaling in Karafka to handle high consumer lag?
The optimal strategy depends on your specific processing patterns and data distribution. A balanced approach involves using a combination of more partitions and virtual partitions. For example, with 6 partitions, you could configure 2 processes with VPs that utilize half the concurrency each and a multiplexing factor of 2. This setup can balance cost and performance well, ensuring you have enough headroom to handle lag spikes efficiently.
How does Karafka behave under heavy lag, and what should be considered in configuration?
Under heavy lag, incorrect settings can reduce Karafka's ability to utilize multiple threads effectively. While Karafka may perform well with multiple threads under normal conditions, heavy lag can force it to operate with reduced concurrency. Configuring Karafka with appropriate settings is crucial to maintaining optimal performance during lag periods. Understanding how to balance threads, processes, and virtual partitions is key to effectively managing high-lag situations.
Is there an undo of Quiet for a consumer to get it consuming again?
A quietened consumer needs to be replaced. When a consumer is quieted, it holds the connections and technically still "moves" forward, but it does so without processing messages. Therefore, to resume consuming, the consumer should be stopped, and a new one should be started.
Can two Karafka server processes with the same group_id consume messages from the same partition in parallel?
No, two Karafka server processes with the same group_id cannot consume messages from the same partition in parallel because this would violate Kafka's strong ordering guarantees. However, you can use virtual partitions to parallelize the work within a single process. Additionally, you can use direct assignments to assign specific partitions to specific processes, but managing offsets would still require a separate consumer group.
What are some good default settings for sending large "trace" batches of messages for load testing?
You can use the produce_many_sync method to send large batches of messages, as it tends to avoid buffer overflows and performs well even with default settings. You might also want to increase the queue.buffering.max.ms setting. Consider dispatching multi-partition messages to delegate faster if you have a larger cluster.
Is it worth pursuing transactions for a low throughput but high-importance topic?
Yes, for low throughput but high-importance topics, it is advisable to use transactions. Transactions ensure that operations are tied together and can be managed atomically, reducing the risk of data inconsistency. Even though the finalization of a transaction is synchronous, it provides an additional layer of reliability for critical data flows.
Does the Waterdrop producer retry to deliver messages after errors such as librdkafka.error and librdkafka.dispatch_error, or are the messages lost?
It depends on the type of error. Waterdrop will retry the delivery for intermediate errors, such as network issues. However, for final errors like an unknown partition, the message will not be retried. If a message is purged, you should receive a final error notification indicating the purge.
In a Rails request, can I publish a message asynchronously, continue the request, and block at the end to wait for the publish to finish?
Yes, you can publish a message asynchronously using Waterdrop. You can get the handler for the async publish and wait on it before the response is returned. This approach ensures that the request continues while the publish happens in parallel. It blocks only at the end to ensure the publish is complete.
Why am I getting the error: "No provider for SASL mechanism GSSAPI: recompile librdkafka with libsasl2 or openssl support"?
This error:
No provider for SASL mechanism GSSAPI:
recompile librdkafka with libsasl2 or openssl support.
Current build options: PLAIN SASL_SCRAM OAUTHBEARER (Rdkafka::Config::ClientCreationError)
indicates that librdkafka was not built with support for GSSAPI (Kerberos). This often occurs when the necessary development packages (libsasl2-dev, libssl-dev and libkrb5-dev) were not available during the librdkafka build process. To fix this, make sure to install these packages before compiling librdkafka. On a Debian-based system, use:
sudo apt-get update && sudo apt-get install -y libsasl2-dev libssl-dev libkrb5-dev
How can I check if librdkafka was compiled with SSL and SASL support in Karafka?
You can check if librdkafka has SSL and SASL support by running the following code in an interactive Ruby session (irb):
require 'rdkafka'
config = {
:"bootstrap.servers" => "localhost:9092",
:"group.id" => "ruby-test",
debug: 'all'
}
consumer = Rdkafka::Config.new(config).consumer
consumer.subscribe("ruby-test-topic")
consumer.close
This will generate logs. Look for lines containing builtin.features that list ssl and sasl_scram:
rdkafka#consumer-1 initialized (builtin.features gzip,snappy,ssl,sasl,regex,lz4, \
sasl_gssapi,sasl_plain,sasl_scram,plugins,zstd,sasl_oauthbearer,http,oidc, GCC \
GXX PKGCONFIG INSTALL GNULD LDS C11THREADS LIBDL PLUGINS ZLIB SSL SASL_CYRUS \
ZSTD CURL HDRHISTOGRAM LZ4_EXT SYSLOG SNAPPY SOCKEM SASL_SCRAM SASL_OAUTHBEARER \
OAUTHBEARER_OIDC CRC32C_HW, debug 0xfffff)
Why does librdkafka lose SSL and SASL support in my multi-stage Docker build?
There are a couple of reasons librdkafka might lose SSL and SASL support in a multi-stage Docker build:
- Removing Essential Build Dependencies Too Early: In multi-stage builds, it's common to install libraries and development tools in an earlier stage and then copy the built software into a slimmer final stage to reduce the image size. However, if the necessary packages (like
libssl-devandlibsasl2-dev) are removed or not available during the initial build stage, librdkafka will compile without SSL and SASL support.
Solution: Ensure that libssl-dev, libsasl2-dev, and other required libraries are installed in the stage where you build librdkafka. Only clean up or remove these libraries after the build is complete.
- Build Layers Removal During Docker Image Creation:
During the process of building Docker images, each command in the Dockerfile creates a new layer. When a layer is removed, all the changes made in that layer (including installed libraries) are also discarded. If the layers containing the installation of libssl-dev, libsasl2-dev, or other dependencies are removed before librdkafka is fully built and linked, then the resulting image will lack SSL and SASL support.
Solution: To avoid this issue, ensure that any cleanup commands (like apt-get remove or rm) are executed after the software is compiled and only if you do not need those libraries anymore for runtime.
Why do I see WaterDrop error events but no raised exceptions in sync producer?
This behavior is by design and relates to WaterDrop's sophisticated error handling model. Here's why this happens:
- Retryable vs. Fatal Errors
- WaterDrop distinguishes between intermediate retryable errors and fatal errors
- Many errors (like network glitches) are considered retryable
- These errors are logged but don't necessarily cause the operation to fail
- Recovery Process
- As long as a message isn't purged from dispatch, WaterDrop will attempt to deliver it
- If WaterDrop can recover before the message purge time, the produce_sync operation will still succeed
- Background errors are emitted to inform you about these recovery attempts
- Why This Matters
- You want to know about intermediate issues (like socket disconnects) as they might indicate underlying cluster problems
- However, if WaterDrop successfully recovers and delivers the message, there's no need to raise an exception
- The operation ultimately succeeded from the user's perspective
For example, if there's a temporary network disconnection:
- The error event is emitted and logged
- WaterDrop reestablishes the connection
- The message is successfully delivered
- No exception is raised because the operation ultimately succeeded
For more detailed information about WaterDrop's error handling model, refer to this documentation.
When does EOF (End of File) handling occur in Karafka, and how does it work?
EOF handling in Karafka only occurs when it is explicitly enabled. However, it's important to understand that EOF execution may not always trigger when the end of a partition is reached during message processing.
When messages are present in the final batch that reaches the end of a partition, Karafka will execute a regular consumption run with the #eofed? flag set to true, rather than triggering the EOF handling logic.
This is because the primary purpose of EOF handling is to deal with scenarios where there are no more messages to process, rather than handling the last message batch. The EOF handling can be useful for executing cleanup or maintenance tasks when a partition has been fully consumed, but it should not be relied upon as a guaranteed trigger for end-of-partition processing logic. If you need guaranteed processing for the last message or batch in a partition, you should implement that logic within your regular message consumption flow using the #eofed? check.
How can I determine if a message is a retry or a new message?
You can use:
#attempt- shows retry attempt number#retrying?- boolean indicating if message is being retried
Note that:
- This works per offset location, not per individual message, unless you mark each message as consumed
- The error causing the retry may differ between retry attempts
You can find more details about this here.
Why does Karafka Web UI stop working after upgrading the Ruby slim/alpine Docker images?
Recent changes in the official Ruby slim and alpine Docker images removed several system dependencies, including the procps package that provides the ps command. The ps command is required by Karafka Web UI for process management and monitoring.
To resolve this issue, you need to explicitly add the procps package to your Dockerfile. For Debian-based images (slim), add:
RUN apt-get update && apt-get install -y procps
For Alpine-based images, add:
RUN apk add --no-cache procps
You can find the complete list of required system commands in our Getting Started documentation.
Why does installing karafka-web take exceptionally long?
When installing karafka and karafka-web, especially in Docker environments like ruby:3.4.2-slim, you might notice installation appears exceptionally slow. However, this delay is typically not caused by karafka itself.
Instead, the slowdown usually results from compiling native extensions for other gems - most commonly grpc. Bundler's parallel installation can mislead you into thinking that karafka-web is slow, as the log messages for other gems (like grpc) may appear after the message indicating karafka-web installation, giving a false impression of delay.
Karafka itself includes native extensions via the karafka-rdkafka gem, but its compilation typically completes quickly (usually within 1-2 minutes).
On the other hand, compiling grpc from source can take significantly longer (up to 20 minutes or more), particularly in resource-constrained CI environments.
You can verify the bottleneck by running:
bundle install --jobs=1
This command disables parallel installation, clearly showing compilation times per gem.
Why does Karafka routing accept consumer classes rather than instances?
Karafka routing requires that you provide a consumer class reference rather than a consumer instance:
# Correct approach
topic :topic_name do
consumer ConsumerClass
end
# Incorrect approach
topic :topic_name do
consumer ConsumerClass.new # This will not work
end
This design decision offers several important benefits:
-
Instance lifecycle management: Karafka needs to control when and how consumer instances are created to properly manage the message processing lifecycle.
-
Resource management: By controlling instantiation, Karafka ensures proper resource cleanup after message processing is complete.
-
Concurrency considerations: When running with multiple threads or processes, Karafka creates separate consumer instances for each concurrent execution unit to maintain thread safety.
-
Configuration integration: Class-based routing allows Karafka to apply configuration and middleware to the class before instantiation.
This pattern follows the principle of Inversion of Control (IoC), where the framework controls object creation rather than the application code. It's similar to how other Ruby frameworks (like Rails) reference controllers by class in routes, not by instances.
Why does Karafka define routing separate from consumer classes, unlike Sidekiq or Racecar?
Unlike frameworks such as Sidekiq or Racecar, where message-processing destinations are defined directly within classes, Karafka uses a separate routing layer that maps topics to consumer classes:
# Karafka approach - separate routing definition
App.routes.draw do
topic :orders do
consumer OrdersConsumer
end
topic :notifications do
consumer NotificationsConsumer
end
end
# vs. embedded approach (not used in Karafka)
class OrdersConsumer
subscribes_to :orders
# ...
end
This deliberate architectural decision provides several significant benefits:
-
Consumer reusability: The same consumer class can be used with multiple topics without modification. This enables powerful patterns where a single processing implementation can handle data from various sources.
-
Multi-level configuration: Karafka's routing system allows configuration at different levels of abstraction: - Consumer group level - Subscription group level - Topic level
-
Separation of concerns: Routing (what to consume) is separated from consumption logic (how to process). This creates cleaner, more maintainable code.
-
Dynamic routing capabilities: The routing layer can be extended with logic that determines routes based on runtime conditions.
-
Enhanced testing: Consumers can be tested independently from their routing configuration, improving unit test isolation.
-
Flexibility for complex setups: The separate routing layer provides much better organization and clarity for advanced Kafka deployments with many topics and consumers.
This approach follows established software architecture principles and provides significantly more flexibility when working with complex Kafka-based systems, especially as your application grows.
What's the difference between key and partition_key in WaterDrop?
When producing messages with WaterDrop, you have the option to specify both a key and a partition_key:
# Using both key and partition_key
producer.produce_async(
topic: 'orders',
payload: order.to_json,
key: order.id.to_s,
partition_key: order.customer_id.to_s
)
These two parameters serve different purposes:
Key
The key parameter sets the actual Kafka message key stored with the message. This key:
- Is used by Kafka for log compaction (if enabled on the topic)
- Can be accessed by consumers when processing the message
- Is included in the message payload that gets stored in Kafka
Partition Key
The partition_key parameter is only used to determine which partition the message should be sent to. It:
- Is used solely for the partitioning algorithm
- Is not stored with the message in Kafka
- Allows you to control message distribution across partitions without affecting the message key
When only key is provided, WaterDrop uses it for both purposes - as the stored message key and for partition determination. When both are specified, partition_key precedes partition selection, while key is still stored with the message.
This separation is particularly useful when:
- You need messages with different keys to end up in the same partition (for ordering)
- You want to use a different attribute for partition selection than what makes sense as a logical message key
- You need to change how messages are partitioned without affecting downstream consumers that rely on the message key
Remember that messages with the same partition_key (or key if no partition_key is specified) will always be routed to the same partition, ensuring ordered processing within that data subset.
Can I disable logging for Karafka Web UI consumer operations while keeping it for my application consumers?
Yes, you can selectively disable logging for Karafka Web UI consumer operations by subclassing the LoggerListener and filtering based on the consumer type.
By default, Karafka logs all consumer operations, including those from the Web UI, because this information can be valuable for debugging overloaded processes or understanding system behavior. However, if you want to reduce log noise, especially in development, you can create a custom logger listener:
class MyLogger < Karafka::Instrumentation::LoggerListener
def on_worker_process(event)
job = event[:job]
consumer = job.executor.topic.consumer
return if consumer == Karafka::Web::Processing::Consumer
super
end
def on_worker_processed(event)
job = event[:job]
consumer = job.executor.topic.consumer
return if consumer == Karafka::Web::Processing::Consumer
super
end
end
Then replace the default logger listener with your custom one in your karafka.rb:
# Remove the default logger listener and add your custom one
Karafka.monitor.subscribe(MyLogger.new)
This approach allows you to maintain detailed logging for your application consumers while filtering out the Web UI consumer logs that may flood your development logs. The same pattern can be extended to filter other types of operations as needed.
How can I distinguish between sync and async producer errors in the error.occurred notification?
Both produce_sync and produce_async trigger the same error.occurred notification, making it difficult to distinguish between them. Since sync errors are typically already handled with backtraces, you can use WaterDrop's labeling feature to differentiate async errors that need special logging. Label your async messages and check for those labels in the error handler to process only async errors. See the detailed guide on distinguishing between sync and async producer errors for implementation examples.
Last modified: 2025-06-30 16:48:05