
*This example illustrates the relationship between the supervisor and the nodes.
### Benefits of using Swarm Mode Swarm Mode in Karafka brings several advantages, especially for applications dealing with high volumes of data or requiring intensive computation. Here are some benefits that highlight the importance and efficiency of using Swarm Mode: - **Improved CPU Utilization**: By running multiple processes, Swarm Mode can fully utilize multi-core systems, ensuring CPU resources are maximally exploited for increased processing power. - **Scalability**: Easily scales your application to handle more load by increasing the number of worker processes, allowing for flexible adaptation to varying workloads. - **Concurrency**: Achieves true concurrency in Ruby applications, sidestepping the Global Interpreter Lock (GIL) limitations using multiple processes instead of threads. - **Efficiency in CPU-bound Tasks**: Ideal for CPU-intensive operations, as it allows for parallel execution of tasks that would otherwise be bottlenecked by single-threaded execution. - **Memory Efficiency**: Leverages Ruby's Copy-On-Write (CoW) feature, which means the memory footprint increases only marginally with each additional processing node, making it memory efficient. - **Robustness and Isolation**: Each worker process is isolated; a failure in one worker does not directly impact others, enhancing the overall robustness of the application. - **Load Distribution**: Allows for efficient workload distribution across multiple processes, ensuring that no single process becomes a bottleneck, leading to more consistent performance. - **Enhanced Fault Tolerance**: The supervisor process can monitor worker health, automatically restarting failed workers, thus ensuring the system remains resilient to individual process failures. - **Flexible Workload Management**: The ability to fine-tune the system based on specific workload requirements, optimizing performance through configuration adjustments without changing the application code. - **Simplified Complex Processing**: Facilitates the management of complex processing pipelines by distributing tasks across nodes, making it easier to reason about and maintain large-scale processing logic. - **Proactive Memory Management**: In Karafka Pro, the supervisor can monitor and control the memory usage of child processes. This feature allows it to shut down workers exceeding a specified memory threshold gracefully. While this is not a substitute for addressing memory leaks within the application, it is a crucial interim measure to manage and mitigate potential memory-related issues. You can read more about this capability [here](https://karafka.io/docs/Pro-Enhanced-Swarm-Multi-Process.md). ## Supported Operating Systems When leveraging Karafka's Swarm Mode for your application, it's crucial to understand the operating system compatibility, mainly due to specific API dependencies. Swarm Mode's efficient process management and supervision rely heavily on the Pidfd API, a feature that is inherently tied to the Linux operating system. The Pidfd API provides a more reliable mechanism for process management by allowing the creation of process file descriptors. This feature significantly enhances the ability of the supervisor process in Swarm Mode to monitor, control, and manage worker processes without the typical race conditions associated with traditional PID-based management. However, using the Pidfd API comes with a specific requirement: it is only available on Linux operating systems with a kernel version that supports Pidfd. To utilize Karafka's Swarm Mode, your Linux system must run a kernel version that supports the Pidfd API. This functionality was introduced in the Linux kernel 5.3 and has seen gradual improvements and enhancements in subsequent releases. Therefore, ensuring your system operates on Linux kernel 5.3 or later is essential for leveraging all the benefits of Swarm Mode. !!! Abstract "Linux Kernel 5.3+ Requirement for Karafka Swarm Mode due to Pidfd API Dependency" Karafka's Swarm Mode requires a Linux OS with kernel version 5.3 or later due to its reliance on the Pidfd API for advanced process management. This ensures efficient and reliable supervision of worker processes in Swarm Mode, exclusive to Linux environments compatible with Pidfd. ## Getting Started with Swarm Mode The startup command deviates slightly from the traditional server start command to activate Swarm Mode. Instead of starting your Karafka application with the usual `bundle exec karafka server`, you will invoke Swarm Mode using: ``` bundle exec karafka swarm ``` This command signals Karafka to initiate in Swarm Mode, creating a supervisor process and the forked nodes. ### CLI Configuration Options When starting your application in Swarm Mode using bundle exec karafka swarm, it's important to note that this command accepts the same CLI configuration options as the standard bundle exec karafka server command. This compatibility ensures that you can apply the same level of control and customization to your Swarm Mode deployment as you would to a single-process setup. The CLI options allow for the efficient limitation of topics, subscription groups, and consumer groups that should operate within the Swarm. You can start a Swarm Mode instance that focuses on processing specific parts of your Kafka infrastructure. For example, you might want to isolate certain consumer groups or topics to dedicated swarms for performance reasons or to manage resource allocation more effectively. ```bash # Run swarm and include only given consumer groups bundle exec karafka swarm --include-consumer-groups group_name1,group_name3 # Run swarm but ignore those two topics bundle exec karafka swarm --exclude-topics topic_name1,topic_name3 ``` ## Configuration and Tuning Configuring and tuning your Karafka application for optimal performance in Swarm Mode involves setting up the correct number of worker processes (nodes) and optionally altering other settings. This setup is crucial for efficiently handling messages, especially in high-throughput or CPU-intensive environments. During your Karafka application setup, you can specify the Swarm Mode configuration as part of the setup block. This includes defining the number of worker processes that should be forked: ```ruby class KarafkaApp < Karafka::App setup do |config| # Other settings... # Configure the number of worker processes for Swarm Mode config.swarm.nodes = 5 end end ``` In this example, `config.swarm.nodes = 5` instructs Karafka to operate in Swarm Mode with `5` worker processes, allowing for parallel message processing across multiple CPU cores. When deciding on the number of nodes (worker processes) to configure, consider the following guidelines: - **CPU/Cores**: Aim to align the number of worker processes with the number of CPU cores available. This ensures that each process can run on its core, maximizing parallelism and reducing context switching overhead. For example, if your server has 8 CPU cores, configuring `config.swarm.nodes = 8` might be optimal. - **Memory Availability**: Worker processes initially share the same memory space (thanks to Ruby's Copy-On-Write mechanism) but will gradually consume more memory as they diverge in their execution paths. Ensure your system has enough memory to support the cumulative memory footprint of all worker processes. Monitor memory usage under load to find a balance that prevents swapping while maximizing utilization of available CPUs. - **Workload Characteristics**: Consider the nature of your workload. CPU-bound tasks benefit from a process-per-core model, whereas I/O-bound tasks might not require as many processes as they often wait on external resources (e.g., network or disk). Below, you can find a few tuning hints worth considering if you strive to achieve optimal performance: - **Monitor and Adjust**: Performance tuning is an iterative process. Monitor key metrics such as CPU utilization, memory consumption, and message processing latency. Adjust the number of worker processes based on observed performance and system constraints. - **Balance with Kafka Partitions**: Ensure that the number of worker processes aligns with the number of partitions in your Kafka topics to avoid idle workers and ensure even load distribution. - **Consider System Overheads**: Leave headroom for the operating system and other applications. Overcommitting resources to Karafka can lead to contention and degraded performance across the system. By carefully configuring and tuning the number of worker processes with your system's CPU and memory resources and the specific demands of your workload, you can achieve a highly efficient and scalable Kafka processing environment with Karafka's Swarm Mode. ### Static Group Membership Management Static Group Membership is an advanced feature that enhances the efficiency and reliability of consumer group management. This feature allows Kafka consumers to retain a stable membership within their consumer groups across sessions. By specifying a unique `group.instance.id` for each consumer, Kafka brokers can recognize individual consumers across disconnections and rebalances, reducing the overhead associated with consumer group rebalances and improving the overall consumption throughput. Swarm Mode supports Static Group Membership, seamlessly integrating this capability into its distributed architecture. This integration means that the `group.instance.id` configuration is preserved across multiple subscription groups and intelligently mapped onto the nodes within the swarm. This mapping ensures that each node maintains a unique identity, preventing conflicts that could arise from multiple nodes inadvertently sharing the same `group.instance.id`. When deploying your application in Swarm Mode, Karafka takes care of the underlying complexity associated with static group memberships. Here's how Karafka ensures consistency and efficiency in this process: - **Automatic ID Management**: Karafka automatically assigns and manages `group.instance.id` for each node within the swarm, ensuring that each node's identity is unique and consistent across sessions. This automatic management simplifies setup and reduces potential configuration errors that could lead to rebalance issues. - **Enhanced Stability**: By utilizing static group memberships, Karafka minimizes the frequency of consumer group rebalances. This stability is particularly beneficial in environments where consumer groups handle high volumes of data, as it allows for uninterrupted data processing and maximizes throughput. - **Simplified Configuration**: Developers need to specify their desired configuration once, and Karafka's Swarm Mode propagates these settings across the swarm. This simplification reduces the operational burden and allows teams to focus on developing the logic and functionality of their applications. - **Seamless Nodes Restarts**: With Karafka Pro's [enhanced monitoring](https://karafka.io/docs/Pro-Enhanced-Swarm-Multi-Process.md), nodes can restart without causing consumer group rebalances, thanks to static group memberships. The `group.instance.id` remains constant across restarts, enabling swift recovery and reconnection to the consumer group. This ensures minimal processing disruption and maintains throughput, showcasing Karafka's fault-tolerant and efficient data-handling capability. While Karafka handles the complexities of `group.instance.id` assignments behind the scenes, developers should know how static group memberships are configured within their applications. Here's an example snippet for reference: ```ruby class KarafkaApp < Karafka::App setup do |config| config.client_id = 'my_application' config.kafka = { 'bootstrap.servers': '127.0.0.1:9092', # Other configuration options... # Set instance id to the hostname (assuming they are unique) 'group.instance.id': Socket.gethostname } end end ``` ## Process Management and Supervision In Swarm Mode, Karafka introduces a supervisor process responsible for forking child nodes and overseeing their operation. This section outlines the key aspects of process management and supervision within this architecture, covering supervision strategies, handling process failures, the limitations of forking, and efficiency through preloading. ### Supervision Strategies In Karafka's Swarm Mode, the supervision of child nodes is a critical component in ensuring the reliability and resilience of the message processing. By design, the supervisor process employs a proactive strategy to monitor the health of each child node. A vital aspect of this strategy involves each child node periodically reporting its health status to the supervisor, independent of its current processing activities. Child nodes are configured to send health signals to the supervisor every 10 seconds. This regular check-in is designed to occur seamlessly alongside ongoing message processing and data polling activities, ensuring that the supervision mechanism does not interrupt or degrade the performance of the message handling workflow. The health signal may include vital statistics and status indicators that allow the supervisor to assess whether a child node is functioning optimally or if intervention is required. The effectiveness of the health reporting mechanism is subject to a critical configuration parameter: `config.max_wait_time`. This setting determines the maximum time Karafka will wait for new data. If this value is set close to or more than `config.internal.swarm.node_report_timeout` (60 seconds by default), nodes may not have a chance to report their health frequently enough. ```ruby class KarafkaApp < Karafka::App setup do |config| # Other settings... # If you want to have really long wait times config.max_wait_time = 60_000 # Make sure node_report_timeout is aligned config.internal.swarm.node_report_timeout = 120_000 end end ``` !!! Abstract "Health Checks vs. `max_wait_time`" In Swarm Mode, ensure `max_wait_time` doesn't exceed the `node_report_timeout` interval (default 60 seconds). Setting it too high could prevent nodes from reporting their health promptly, affecting system monitoring and stability. Two scenarios may necessitate shutting down a node: 1. **Extended Health Reporting Delays**: If a child node fails to report its health status within the expected timeframe, the supervisor interprets this as the node being unresponsive or "hanging". This situation triggers a protective mechanism to prevent potential system degradation or deadlock. 1. **Unhealthy Status Reports (Karafka Pro)**: With the enhanced capabilities of Karafka Pro, nodes possess the self-awareness to report unhealthy states. This can range from excessive memory consumption and prolonged processing times to polling mechanisms becoming unresponsive. Recognizing these reports, the supervisor takes decisive action to address the compromised node. Upon identifying a node that requires a shutdown, either due to delayed health reports or self-reported unhealthy conditions, the supervisor initiates a two-step process: - **TERM Signal**: The supervisor first sends a TERM signal to the node, initiating a graceful shutdown sequence. This allows the node to complete its current tasks, release resources, and shut down properly, minimizing potential data loss or corruption. - **KILL Signal**: If the node fails to shut down within the specified `shutdown_timeout` period, the supervisor escalates its intervention by sending a KILL signal. This forcefully terminates the node, ensuring the system can recover from the situation but at the risk of abrupt process termination. Following a node's shutdown - graceful or forceful - Karafka imposes a mandatory delay of at least 5 seconds before attempting to restart the node. This deliberate pause serves a crucial purpose: - **Preventing System Overload**: By waiting before restarting a node, Karafka mitigates the risk of entering a rapid, endless loop of immediate process death and restart. Such scenarios can arise from external factors that instantaneously cause a newly spawned process to fail. The delay ensures that the system has a brief period to stabilize, assess the environment, and apply any necessary corrections before reintroducing the node into the swarm. - **System Health Preservation**: This pause also provides a buffer for the overall system to manage resource reallocation, clear potential bottlenecks, and ensure that restarting the node is conducive to maintaining system health and processing efficiency. Karafka's Swarm Mode ensures robust process management through these meticulous supervision strategies, promoting system stability and resilience.

*Diagram illustrating flow of supervision of a swarm node.
### Limitations of Forking Despite its benefits for CPU-bound tasks, forking has several limitations, especially in the context of I/O-bound operations and broader system architecture: - **Memory Overhead**: Initially, forking benefits from Ruby's Copy-On-Write (CoW) mechanism, which keeps the memory footprint low. However, as child processes modify their memory, the shared memory advantage may diminish, potentially leading to increased memory usage. - **I/O Bound Operations**: Forking is less effective for I/O-bound tasks because these tasks spend a significant portion of their time waiting on external resources (e.g., network or disk). In such cases, Karafka multi-threading and Virtual Partitions may be more efficient as they can handle multiple I/O operations in a single process. - **Database Connection Pooling**: Each forked process requires its database connections. This can rapidly increase the number of database connections, potentially exhausting the available pool and leading to scalability issues. - **File Descriptor Limits**: Forking multiple processes increases the number of open file descriptors, which can hit the system limit, affecting the application's ability to open new files or establish network connections. - **Startup Time**: Forking can increase the application's startup time, especially if the initial process needs to load a significant amount of application logic or data into memory before forking. - **Debugging and Monitoring Complexity**: Debugging issues or monitoring the performance of applications using the forking model can be more challenging due to multiple processes requiring more sophisticated tooling and approaches. - **Separate Kafka Connections**: Each forked process in a Karafka application is treated by Kafka as an individual client. This means every process maintains its connection to Kafka, increasing the total number of connections to the Kafka cluster. - **Independent Partition Assignments**: In Kafka, partitions of a topic are distributed among all consumers in a consumer group. With each forked process treated as a separate consumer, Kafka assigns partitions to each process independently. This behavior can lead to uneven workload distribution, especially if the number of processes significantly exceeds the number of partitions or if the partitioning does not align well with the data's processing requirements. - **Consumer Group Rebalancing**: Kafka uses consumer groups to manage which consumers are responsible for which partitions. When processes are forked, each one is considered a new consumer, triggering consumer group rebalances. Frequent rebalances can lead to significant overhead, especially in dynamic environments where processes are regularly started or stopped. Rebalancing pauses message consumption, as the group must agree on the new partition assignment, leading to potential delays in message processing. While forking enables Ruby applications like Karafka to parallelize work efficiently, these limitations highlight the importance of careful architectural consideration, especially when dealing with I/O-bound operations or scaling to handle high concurrency and resource utilization levels. !!! danger "Avoid Using Karafka APIs in the Supervisor Process" It is essential to refrain from using the Karafka producer or any other Karafka APIs, including administrative APIs, within the supervisor process, both before and after forking. `librdkafka`, the underlying library used by Karafka, is fundamentally not fork-safe. Utilizing these APIs from the supervisor process can lead to unexpected behaviors and potentially destabilize your application. Always ensure that interactions with Karafka's APIs occur within the forked worker nodes, where it is safe and designed to operate. ### Warmup and Preloading for Efficiency Preloading in the Swarm Mode, akin to Puma and Sidekiq Enterprise practices, offers substantial memory savings. By loading the application environment and dependencies before forking, Karafka can significantly reduce memory usage - 20-30% savings are common. However, this feature requires carefully managing resources inherited by child processes, such as file descriptors, network connections, and threads. When the supervisor process forks a worker, the child inherits open file descriptors and potentially other resources like network connections. Inherited resources can cause unexpected behavior or resource leaks if not properly managed. To address this, Karafka, similar to Puma, provides hooks that allow for resource cleanup and reinitialization before and after forking: !!! Tip "Automatic Reconfiguration of Karafka Internals Post-Fork" All Karafka internal components, including the Karafka producer, will be automatically reconfigured post-fork, eliminating the need for manual reinitialization of these elements. Focus solely on reconfiguring any external components or connections your application relies on, such as databases or APIs, as these are not automatically reset. This automatic reconfiguration ensures that Karafka internals are immediately ready for use in each forked process, streamlining multi-process management. ```ruby # At the end of karafka.rb # This will run in each forked node right after it was forked Karafka.monitor.subscribe('swarm.node.after_fork') do # Make sure to re-establish all connections to the DB after fork (if any) ActiveRecord::Base.clear_active_connections! end ``` Below, you can find a few examples of resources worth preparing and cleaning before forking: - **Database Connections**: Re-establish database connections to prevent sharing connections between processes, which could lead to locking issues or other concurrency problems. For ActiveRecord, this typically involves calling ActiveRecord::Base.establish_connection. - **Thread Cleanup**: If the preloaded application spawns threads, ensure they are stopped or re-initialized post-fork to avoid sharing thread execution contexts. - **Closing Unneeded File Descriptors**: Explicitly close or reopen file descriptors that shouldn't be shared across processes to avoid leaks and ensure the independent operation of each process. Given the potential complexities and dangers associated with preloading the entire application, Karafka makes this feature opt-in. This cautious approach enables developers to enable preloading when effectively managing the related resources. In addition to preloading for substantial memory savings, Karafka introduces a crucial phase known as "Process Warmup" right before the process starts. It occurs only in the supervisor. This phase is designed to optimize the application's readiness for forking and operation, leveraging Ruby 3.3's `Process.warmup` feature and similar techniques in previous Ruby versions. This method signals Ruby that the application has completed booting and is now ready for forking, triggering actions such as garbage collection and memory compaction to enhance the efficiency of Copy-On-Write (CoW) mechanics in child forks. Before the warmup phase, Karafka emits a `process.before_warmup` notification, providing an ideal opportunity to eager load the application code and perform other preparatory tasks. This hook is pivotal for loading any code that benefits from being loaded once and shared across forks, thereby reducing memory usage and startup time for each child process. ```ruby # At the end of karafka.rb Karafka.monitor.subscribe('app.before_warmup') do # Eager load the application code and other heavy resources here # This code will run only once in supervisor before the final warmup Rails.application.eager_load! end ``` The `Process.warmup` method and `process.before_warmup` hook collectively ensure that your Karafka application is optimized for multi-process environments. By utilizing these features, you can significantly reduce the memory footprint of your applications and streamline process management, especially in environments where memory efficiency and quick scaling are paramount. By carefully preparing for and executing the warmup phase, you ensure your Karafka applications operates optimally, benefiting from reduced memory usage and enhanced process initialization performance. Below, you can compare memory usage when running 3 independent processes versus Swarm with 3 nodes and a supervisor. In this case, Swarm uses around 50% less memory than independent processes.
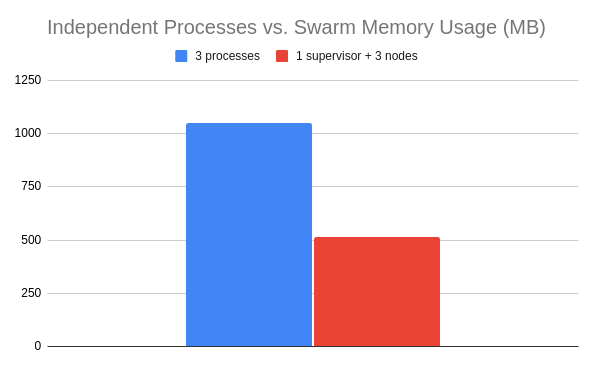
*Diagram illustrating memory usage with and without Swarm with the same number of consumers. Less is better.
If you want to measure gains within your particular application under given conditions, you can use the below script. This script calculates and displays memory usage details for processes matching a specified pattern (e.g., "karafka") on a Linux system, utilizing the `smem` tool. It retrieves the Proportional Set Size (PSS), Unique Set Size (USS), and Resident Set Size (RSS) for each process, which helps in understanding both individual and collective memory usage, including shared memory aspects. ```bash #!/bin/bash # Get USS, PSS, and RSS values for processes matching the pattern mapfile -t MEMORY_VALUES < <( \ smem -P karafka --no-header -c "pid uss pss rss" | sed '1d' \ ) # Initialize totals TOTAL_USS=0 TOTAL_PSS=0 TOTAL_RSS=0 # Print header for process memory usage echo "PID | RSS Memory (MB) | PSS Memory (MB)" # Process each line for LINE in "${MEMORY_VALUES[@]}"; do # Read values into variables read -r PID USS PSS RSS <<<"$LINE" TOTAL_USS=$((TOTAL_USS + USS)) TOTAL_PSS=$((TOTAL_PSS + PSS)) TOTAL_RSS=$((TOTAL_RSS + RSS)) # Convert RSS and PSS from kilobytes to megabytes for readability RSS_MB=$(echo "scale=2; $RSS / 1024" | bc) PSS_MB=$(echo "scale=2; $PSS / 1024" | bc) # Print RSS and PSS memory usage for the current process echo "$PID | $RSS_MB MB | $PSS_MB MB" done # Convert total USS and PSS from kilobytes to megabytes TOTAL_USS_MB=$(echo "scale=2; $TOTAL_USS / 1024" | bc) TOTAL_PSS_MB=$(echo "scale=2; $TOTAL_PSS / 1024" | bc) # Calculate and print the percentage of shared memory # Shared memory percentage is calculated from the difference between PSS and USS # compared to the total PSS, indicating how much of the memory is shared if [ "$TOTAL_PSS" -gt 0 ]; then SHARED_MEMORY_MB=$(echo "scale=2; $TOTAL_PSS_MB - $TOTAL_USS_MB" | bc) SHARED_MEM_PCT=$(echo "scale=2; ($SHARED_MEMORY_MB / $TOTAL_PSS_MB) * 100" | bc) echo "Shared Memory Percentage: $SHARED_MEM_PCT%" else echo "PSS is zero, cannot calculate shared memory percentage." fi echo "Total Memory Used: $TOTAL_PSS_MB MB" ``` When executed, you will get similar output: ```bash ./rss.sh PID | RSS Memory (MB) | PSS Memory (MB) 300119 | 329.12 MB | 107.19 MB 300177 | 355.17 MB | 142.53 MB 300159 | 355.25 MB | 142.62 MB 300166 | 356.16 MB | 143.49 MB Shared Memory Percentage: 51.00% Total Memory Used: 535.85 MB ``` ## Instrumentation, Monitoring, and Logging Karafka's Swarm Mode's instrumentation, monitoring, and logging approach remains consistent with the standard mode (`bundle exec karafka server`), ensuring a seamless transition and maintenance experience. The Web UI is fully compatible with Swarm Mode and requires no additional configuration, providing out-of-the-box functionality for monitoring your applications. ### Notification Events in Swarm Mode Karafka introduces several event hooks specific to Swarm Mode, enhancing the observability and manageability of both the supervisor and forked nodes. These events allow for custom behavior and integration at different stages of the process lifecycle:| Event | Location | Description |
|---|---|---|
app.before_warmup |
Supervisor | Runs code needed to be prepared before the warmup process. |
swarm.node.after_fork |
Forked Node | Triggered after each node is forked, allowing for node-specific initialization. |
swarm.manager.before_fork |
Supervisor | Occurs before each node is forked, enabling pre-fork preparation. |
swarm.manager.after_fork |
Supervisor | Fires after each node fork, facilitating post-fork actions at the supervisor level. |
swarm.manager.control |
Supervisor | Executed each time the supervisor checks the health of nodes, supporting ongoing supervision. |
swarm.manager.stopping |
Supervisor | Indicates the supervisor is shutting down for reasons other than a full application shutdown. |
swarm.manager.terminating |
Supervisor | Initiated when the supervisor decides to terminate an unresponsive node. |
| Status Code | Description |
|---|---|
| -1 | Node did not report its health for an extended period and was considered hanging. |
| 1 | Node reported insufficient polling from Kafka (Pro only). |
| 2 | Consumer is consuming a batch longer than expected (Pro only). |
| 3 | Node exceeded the allocated memory limit (Pro only). |

*Diagram illustrating the shutdown flow and interactions between supervisor and child nodes.
## Web UI Enhancements for Swarm Karafka's Web UI fully supports Swarm Mode, showcasing each forked node as an independent entity for detailed monitoring. In Swarm Mode, the Web UI distinguishes each node as a separate process. However, each swarm node is marked with a "paid" label, indicating the parent process's PID (the supervisor). This feature aids in identifying the relationship between nodes and their supervisor. Due to librdkafka's fork-safety limitations, the supervisor process does not appear directly in the Web UI because it cannot hold open connections to Kafka. However, The supervisor's presence is inferred through the PPID label of swarm nodes. Since all nodes share the same supervisor PID as their PPID, you can indirectly identify the supervisor process that way.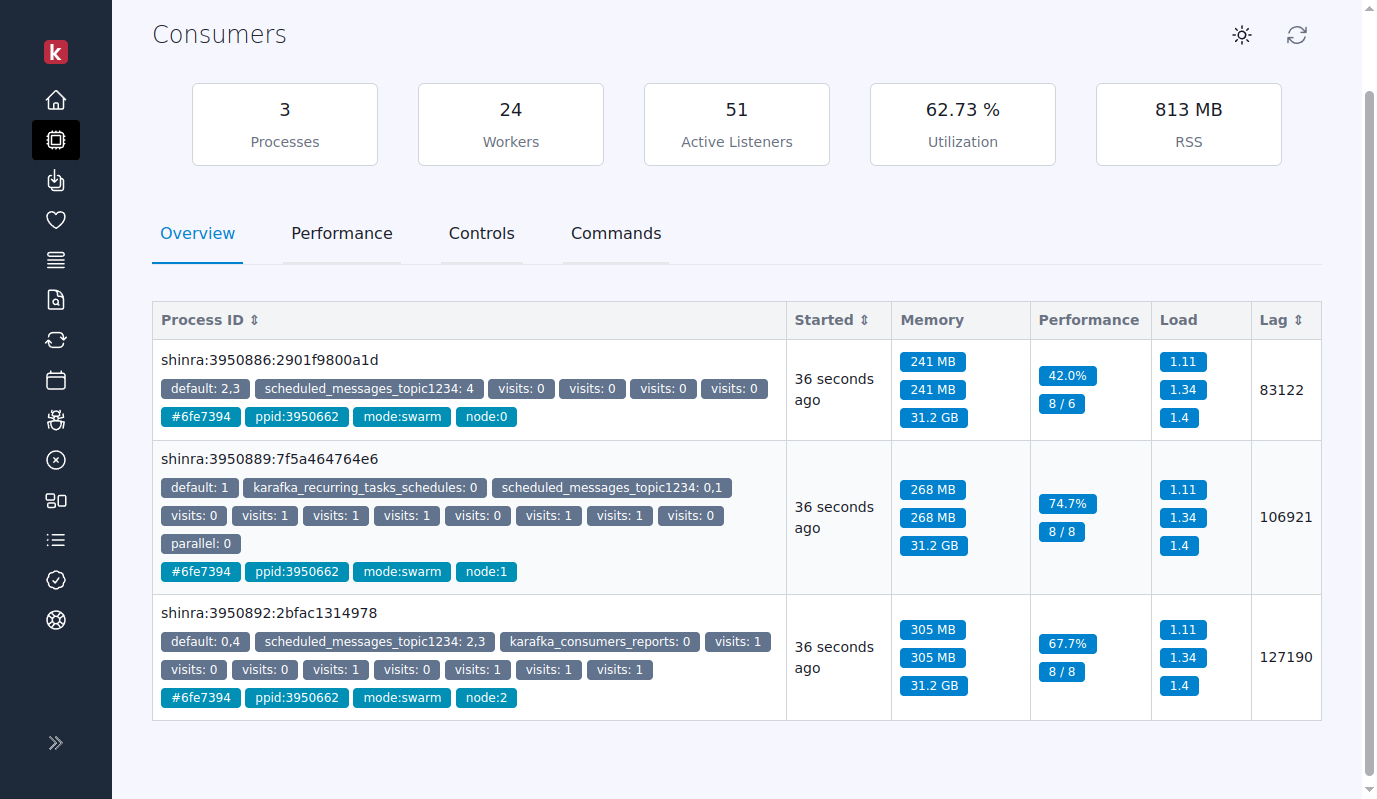 ## Swarm vs. Multi-Threading and Virtual Partitions
Karafka's scalability and workload management strategies include Swarm Mode, multi-threading, virtual partitions, and multiplexing. Each serves specific workload needs, facilitating optimal architectural decisions.
- **Swarm Mode** excels in CPU-intensive environments by utilizing multiple processes for true parallel execution, enhancing CPU utilization and throughput. However, its scalability is tied to the number of Kafka partitions, limiting parallelization.
- **Multi-threading** is suited for I/O-bound tasks, efficiently managing wait times by concurrently handling tasks within a single process. Its scalability is constrained by Ruby's Global Interpreter Lock (GIL) and the number of Kafka partitions.
- **Virtual Partitions** increase Karafka's scalability beyond Kafka's partition limits by simulating additional partitions, improving load distribution and processing for I/O-bound tasks.
- **Multiplexing** allows a single process to subscribe to multiple topics or partitions with multiple connections, optimizing throughput without additional processes or threads. It's useful for high-partition topics but requires careful consumer instance management to maintain processing efficiency.
Each strategy offers unique advantages for Karafka application optimization. Swarm Mode and multi-threading address CPU-intensive and I/O-bound workloads, respectively, while virtual partitions and multiplexing overcome Kafka partition scalability limits. Selecting the appropriate strategy depends on your workload's characteristics and scalability goals.
## Producer Full Reconfiguration
When operating in Swarm Mode, each forked node automatically inherits most of the producer configuration from the parent process. However, to ensure proper functionality and avoid potential conflicts, it's crucial to understand how to fully reconfigure producers post-fork.
By default, while Karafka takes care of most internal reconfigurations automatically, there are cases where you might want to fully reconfigure the producer with your settings or modify specific configuration parameters. This is particularly important when dealing with producer-specific identifiers or when you need to customize the producer behavior for different nodes.
Here's an example of how to fully reconfigure a producer after forking:
```ruby
# In your karafka.rb after all other setup
Karafka.monitor.subscribe('swarm.node.after_fork') do
# Create a fresh producer instance that inherits all the core configuration
Karafka::App.config.producer = ::WaterDrop::Producer.new do |p_config|
p_config.logger = Karafka::App.config.logger
# Copy and map all the Kafka configuration or replace with your own
p_config.kafka = ::Karafka::Setup::AttributesMap.producer(Karafka::App.config.kafka.dup)
# Add any node-specific configurations here
p_config.kafka[:'client.id'] = "#{Karafka::App.config.client_id}-#{Process.pid}"
end
end
```
This approach ensures that:
1. Each node gets a fresh producer instance
1. All core configurations are properly configured
1. Node-specific settings can be customized as needed
1. The producer is properly initialized within the forked process context
Note that complete reconfiguration is significant when:
1. You need to set node-specific client IDs
1. You're using transactional producers (which require unique transactional IDs)
1. You want to customize producer behavior based on node characteristics
1. You need to modify connection or authentication settings per node
## Transactional Producer Handling in Swarm Mode
When operating in Swarm Mode, each forked node inherits the Karafka producer configuration from the parent process. This inheritance mechanism helps maintain consistency across nodes while reducing configuration overhead. However, special consideration is needed when working with transactional producers, as certain configuration parameters require unique values per node to ensure proper operation.
The transactional.id configuration parameter requires special attention in Swarm Mode. While other configuration parameters can be safely inherited, using the same `transactional.id` across multiple producer instances will cause transaction fencing issues. When a producer instance begins a transaction, it receives an epoch number from the transaction coordinator. If another producer instance with the same `transactional.id` starts a transaction, it will receive a higher epoch number and fence off (invalidate) the previous producer instance.
To prevent fencing issues, you must ensure each node's producer has a unique `transactional.id`. Here's an example of how to properly configure transactional producers in Swarm Mode:
```ruby
# In your karafka.rb after all other setup
Karafka.monitor.subscribe('swarm.node.after_fork') do
# Assign fresh instance that takes all the configuration details except the transactional.id
Karafka::App.config.producer = ::WaterDrop::Producer.new do |p_config|
p_config.logger = Karafka::App.config.logger
p_config.kafka = ::Karafka::Setup::AttributesMap.producer(Karafka::App.config.kafka.dup)
# Use a unique transactional.id and do not re-use the parent one
p_config.kafka[:'transactional.id'] = SecureRandom.uuid
end
end
```
This approach will ensure that:
1. Each node gets a unique `transactional.id`
1. Transactions from different nodes won't interfere with each other
1. The producer can maintain proper transaction isolation and exactly once semantics
!!! Warning "Transactional ID Conflicts"
Failing to set unique `transactional.id` values for each node will result in producers fencing each other off, leading to failed transactions and potential data consistency issues. Always ensure each node's producer has a unique transactional ID.
## Example Use Cases
Here are some use cases from various industries where Karafka's Swarm Mode can be beneficial:
- **Background Job Processing**: Ruby on Rails applications frequently rely on background jobs for tasks that are too time-consuming to be processed during a web request. Examples include sending batch emails, generating reports, or processing uploaded files. Swarm Mode can distribute these jobs across multiple processes, significantly reducing processing time by leveraging all available CPU cores.
- **Image Processing and Generation**: Many Ruby applications need to process images, whether resizing, cropping, or applying filters. Image processing is CPU-intensive and can benefit from parallel execution in Swarm Mode, especially when handling high volumes of images, such as in user-generated content platforms or digital asset management systems.
- **Data Import and Export Operations**: Applications that require importing large datasets (e.g., CSV, XML, or JSON files) into the database or exporting data for reports can utilize Swarm Mode to parallelize parsing and processing. This accelerates the import/export operations, making it more efficient to handle bulk data operations without blocking web server requests.
- **Real-time Data Processing**: Real-time analytics or event processing systems in Ruby can process incoming data streams (from webhooks, sensors, etc.) in parallel using Swarm Mode. This is particularly useful for applications that aggregate data, calculate statistics, or detect patterns in real time across large datasets.
- **Complex Calculations and Simulations**: Applications that perform complex calculations or simulations, such as financial modeling, risk analysis, or scientific computations, can significantly improve performance with Swarm Mode. By distributing the computational load across multiple worker processes, Ruby applications can handle more complex algorithms and larger datasets without slowing down.
Implementing Swarm Mode for these use cases allows applications to fully utilize server resources, overcoming the limitations of Ruby's Global Interpreter Lock (GIL) and enhancing overall application performance and scalability.
## Summary
Karafka's Swarm Mode offers a multi-process architecture optimized for CPU-intensive Kafka message processing in Ruby, effectively bypassing the Global Interpreter Lock (GIL). It leverages Ruby's Copy-On-Write (CoW) for efficient memory use, employing a "Supervisor-Worker" pattern for parallel execution and system health monitoring.
Swarm Mode supports Static Group Membership to enhance consumer group stability and allows for quick node restarts without rebalancing, thanks to Karafka Pro's monitoring.
---
*Last modified: 2025-02-12 18:27:28*
## Swarm vs. Multi-Threading and Virtual Partitions
Karafka's scalability and workload management strategies include Swarm Mode, multi-threading, virtual partitions, and multiplexing. Each serves specific workload needs, facilitating optimal architectural decisions.
- **Swarm Mode** excels in CPU-intensive environments by utilizing multiple processes for true parallel execution, enhancing CPU utilization and throughput. However, its scalability is tied to the number of Kafka partitions, limiting parallelization.
- **Multi-threading** is suited for I/O-bound tasks, efficiently managing wait times by concurrently handling tasks within a single process. Its scalability is constrained by Ruby's Global Interpreter Lock (GIL) and the number of Kafka partitions.
- **Virtual Partitions** increase Karafka's scalability beyond Kafka's partition limits by simulating additional partitions, improving load distribution and processing for I/O-bound tasks.
- **Multiplexing** allows a single process to subscribe to multiple topics or partitions with multiple connections, optimizing throughput without additional processes or threads. It's useful for high-partition topics but requires careful consumer instance management to maintain processing efficiency.
Each strategy offers unique advantages for Karafka application optimization. Swarm Mode and multi-threading address CPU-intensive and I/O-bound workloads, respectively, while virtual partitions and multiplexing overcome Kafka partition scalability limits. Selecting the appropriate strategy depends on your workload's characteristics and scalability goals.
## Producer Full Reconfiguration
When operating in Swarm Mode, each forked node automatically inherits most of the producer configuration from the parent process. However, to ensure proper functionality and avoid potential conflicts, it's crucial to understand how to fully reconfigure producers post-fork.
By default, while Karafka takes care of most internal reconfigurations automatically, there are cases where you might want to fully reconfigure the producer with your settings or modify specific configuration parameters. This is particularly important when dealing with producer-specific identifiers or when you need to customize the producer behavior for different nodes.
Here's an example of how to fully reconfigure a producer after forking:
```ruby
# In your karafka.rb after all other setup
Karafka.monitor.subscribe('swarm.node.after_fork') do
# Create a fresh producer instance that inherits all the core configuration
Karafka::App.config.producer = ::WaterDrop::Producer.new do |p_config|
p_config.logger = Karafka::App.config.logger
# Copy and map all the Kafka configuration or replace with your own
p_config.kafka = ::Karafka::Setup::AttributesMap.producer(Karafka::App.config.kafka.dup)
# Add any node-specific configurations here
p_config.kafka[:'client.id'] = "#{Karafka::App.config.client_id}-#{Process.pid}"
end
end
```
This approach ensures that:
1. Each node gets a fresh producer instance
1. All core configurations are properly configured
1. Node-specific settings can be customized as needed
1. The producer is properly initialized within the forked process context
Note that complete reconfiguration is significant when:
1. You need to set node-specific client IDs
1. You're using transactional producers (which require unique transactional IDs)
1. You want to customize producer behavior based on node characteristics
1. You need to modify connection or authentication settings per node
## Transactional Producer Handling in Swarm Mode
When operating in Swarm Mode, each forked node inherits the Karafka producer configuration from the parent process. This inheritance mechanism helps maintain consistency across nodes while reducing configuration overhead. However, special consideration is needed when working with transactional producers, as certain configuration parameters require unique values per node to ensure proper operation.
The transactional.id configuration parameter requires special attention in Swarm Mode. While other configuration parameters can be safely inherited, using the same `transactional.id` across multiple producer instances will cause transaction fencing issues. When a producer instance begins a transaction, it receives an epoch number from the transaction coordinator. If another producer instance with the same `transactional.id` starts a transaction, it will receive a higher epoch number and fence off (invalidate) the previous producer instance.
To prevent fencing issues, you must ensure each node's producer has a unique `transactional.id`. Here's an example of how to properly configure transactional producers in Swarm Mode:
```ruby
# In your karafka.rb after all other setup
Karafka.monitor.subscribe('swarm.node.after_fork') do
# Assign fresh instance that takes all the configuration details except the transactional.id
Karafka::App.config.producer = ::WaterDrop::Producer.new do |p_config|
p_config.logger = Karafka::App.config.logger
p_config.kafka = ::Karafka::Setup::AttributesMap.producer(Karafka::App.config.kafka.dup)
# Use a unique transactional.id and do not re-use the parent one
p_config.kafka[:'transactional.id'] = SecureRandom.uuid
end
end
```
This approach will ensure that:
1. Each node gets a unique `transactional.id`
1. Transactions from different nodes won't interfere with each other
1. The producer can maintain proper transaction isolation and exactly once semantics
!!! Warning "Transactional ID Conflicts"
Failing to set unique `transactional.id` values for each node will result in producers fencing each other off, leading to failed transactions and potential data consistency issues. Always ensure each node's producer has a unique transactional ID.
## Example Use Cases
Here are some use cases from various industries where Karafka's Swarm Mode can be beneficial:
- **Background Job Processing**: Ruby on Rails applications frequently rely on background jobs for tasks that are too time-consuming to be processed during a web request. Examples include sending batch emails, generating reports, or processing uploaded files. Swarm Mode can distribute these jobs across multiple processes, significantly reducing processing time by leveraging all available CPU cores.
- **Image Processing and Generation**: Many Ruby applications need to process images, whether resizing, cropping, or applying filters. Image processing is CPU-intensive and can benefit from parallel execution in Swarm Mode, especially when handling high volumes of images, such as in user-generated content platforms or digital asset management systems.
- **Data Import and Export Operations**: Applications that require importing large datasets (e.g., CSV, XML, or JSON files) into the database or exporting data for reports can utilize Swarm Mode to parallelize parsing and processing. This accelerates the import/export operations, making it more efficient to handle bulk data operations without blocking web server requests.
- **Real-time Data Processing**: Real-time analytics or event processing systems in Ruby can process incoming data streams (from webhooks, sensors, etc.) in parallel using Swarm Mode. This is particularly useful for applications that aggregate data, calculate statistics, or detect patterns in real time across large datasets.
- **Complex Calculations and Simulations**: Applications that perform complex calculations or simulations, such as financial modeling, risk analysis, or scientific computations, can significantly improve performance with Swarm Mode. By distributing the computational load across multiple worker processes, Ruby applications can handle more complex algorithms and larger datasets without slowing down.
Implementing Swarm Mode for these use cases allows applications to fully utilize server resources, overcoming the limitations of Ruby's Global Interpreter Lock (GIL) and enhancing overall application performance and scalability.
## Summary
Karafka's Swarm Mode offers a multi-process architecture optimized for CPU-intensive Kafka message processing in Ruby, effectively bypassing the Global Interpreter Lock (GIL). It leverages Ruby's Copy-On-Write (CoW) for efficient memory use, employing a "Supervisor-Worker" pattern for parallel execution and system health monitoring.
Swarm Mode supports Static Group Membership to enhance consumer group stability and allows for quick node restarts without rebalancing, thanks to Karafka Pro's monitoring.
---
*Last modified: 2025-02-12 18:27:28*