Cleaner API is a feature designed to enhance the performance and efficiency of batch-processing tasks by promptly freeing up memory once a message payload is no longer needed. By addressing potential memory spikes, the Cleaner API ensures a more stable and efficient processing environment, especially beneficial when handling payloads of size 10KB and larger.
## How does it work
This functionality extends both the message batch and individual message objects. Messages can indicate when their payload is no longer necessary. Once a message conveys this information, the Cleaner API completely removes both the payload and the raw payload from memory.
Remarkably, this memory clearance occurs before the entire batch is processed, effectively allowing only a single deserialized payload to be kept in memory. This mechanism is particularly advantageous when sequentially processing messages, especially within large batches containing hundreds of messages or more. This ensures optimal memory management and faster processing, as no longer needed data is eradicated immediately after processing, rather than waiting for the entire batch to conclude.
The below example illustrates how the Cleaner API releases both `payload` and `raw_payload` after each of the processed messages.

!!! note "Cleaner API and Kafka Message Immutability"
The data stored in Kafka remains unaltered and intact, regardless of any actions taken using the Cleaner API. The Cleaner API is exclusively designed to manage and optimize the memory utilization of the running process. When the API removes a message's payload, it only clears that data from the application's active memory. This operation does not, in any manner, affect the original message data residing in Kafka.
### How does it work / Using Cleaner API
When utilizing the Cleaner API, it is paramount to understand the implications on the message's data.
Once `#clean!` is invoked on a message, the message's `payload` and `raw_payload` are permanently removed from memory. As a result, these data become irretrievable and inaccessible. Please ensure that, under any circumstances, you do not try to use this data after it has been cleaned.
#### How does it work / Using Cleaner API / Cleaning One Message at a Time
After processing a message, you can explicitly call the `#clean!` method on that message. This allows you to have granular control over which messages are cleaned from memory.
By default, both the payload and metadata (headers and key) are removed. If you want to retain the metadata while discarding only the payload and raw payload, you can pass `metadata: false`.
```ruby
def consume
messages.each do |message|
DataStore.persist!(message.payload)
# Always make sure to mark as consumed before cleaning
# in case you are using the Dead Letter Queue
mark_as_consumed(message)
# Clean only the payload, keep headers and key
# Defaults to cleaning also metadata
message.clean!(metadata: false)
end
end
```
!!! note "Metadata Cleaning Behavior"
By default, the Cleaner API removes both the message’s payload and its metadata (`headers`, `key`).
If you only want to clean the payload and keep the metadata available, use `message.clean!(metadata: false)`.
#### How does it work / Using Cleaner API / Automatic Cleaning with `#each`
The Cleaner API allows you to automate the cleanup process for a more streamlined approach. By providing the `clean: true` parameter to the `#each` method, each message's payload is automatically cleaned from memory as soon as it's processed.
```ruby
def consume
# Clean each message after we're done processing it
messages.each(clean: true) do |message|
DataStore.persist!(message.payload)
# Always make sure to mark as consumed before cleaning
# in case you are using the Dead Letter Queue
mark_as_consumed(message)
end
end
```
#### How does it work / Using Cleaner API / Checking Message State
To assess whether a message has undergone the cleaning process, you can use the `#cleaned?` method directly on the message object. This method provides a straightforward way to check the cleaning status of the message, returning a boolean value (`true` if cleaned, `false` otherwise). This functionality is particularly useful for conditional operations or logging scenarios.
```ruby
if message.cleaned?
puts 'The message has been cleaned.'
else
puts 'The message has not been cleaned yet.'
end
```
Regardless of where you are in your code, as long as the message object is accessible, you can leverage the `#cleaned?` method to determine the cleaning state of the message and proceed accordingly.
### How does it work / Benefits
- **Memory Efficiency**: Cleaner API optimizes memory usage by promptly releasing unused messages payloads, ensuring that your application uses memory judiciously.
- **Performance Boost**: By avoiding significant memory spikes and congestion, applications can run smoother and process batches faster.
- **Cost Savings**: Efficient memory use can directly influence hosting costs, especially in cloud environments where you pay for the resources you use.
- **Enhanced Reliability**: By proactively managing memory, the chances of application crashes due to out-of-memory exceptions become much lower.
### How does it work / Statistics
The efficacy and benefits of the Cleaner API are closely linked to the sizes of the raw payload and the deserialized payload of messages.
The magnitude of memory management gains directly correlates with the average size of these payloads and the number of messages obtained in a single batch.
In scenarios where the raw payload of a message is under 1KB, the advantages derived from using the Cleaner API tend to be minimal and may even appear negligible. This is because the memory space occupied by smaller messages is relatively minor. However, as the size of messages increases, the benefits of using the Cleaner API become increasingly pronounced. Large messages, when retained in memory after processing, can lead to significant memory congestion, and clearing them out promptly can free up sizable memory chunks, enhancing overall system performance.
This size dependency is precisely why the statistics below offer insights into multiple scenarios, capturing the varying benefits across different payload sizes.
The examples provided here illustrate the memory management across three styles of processing:
1. **Standard**: In this approach, the processing loop deserializes one message at a time, making it a sequential and straightforward method.
2. **Immediate**: This method first invokes the `#payloads` function, deserializing all messages before any further processing occurs. This pre-deserialization can influence the overall memory consumption as all messages get loaded into memory up front.
3. **Cleaned**: This processing style uses the `#each` loop but with an added parameter `cleaned: true`. This ensures that after each message is processed, its payload is promptly cleaned from memory, thus potentially reducing memory spikes and promoting efficient memory use.
For these examples, the primary metric used to measure memory consumption is RSS or Resident Set Size. RSS represents the portion of a process's memory that is held in RAM. This measurement clearly indicates the actual memory footprint of the process during its execution. In the context of these examples, the RSS value is displayed in megabytes (MBs).
The structure of the code primarily focuses on deserializing data and then waiting and was similar to the one below:
```ruby
def consume
# messages.payloads
messages.each(clean: true) do |message|
message.payload
sleep(0.1)
end
end
```
Each fetched batch contained at most 500 messages.
#### How does it work / Statistics / Message size of 1MB
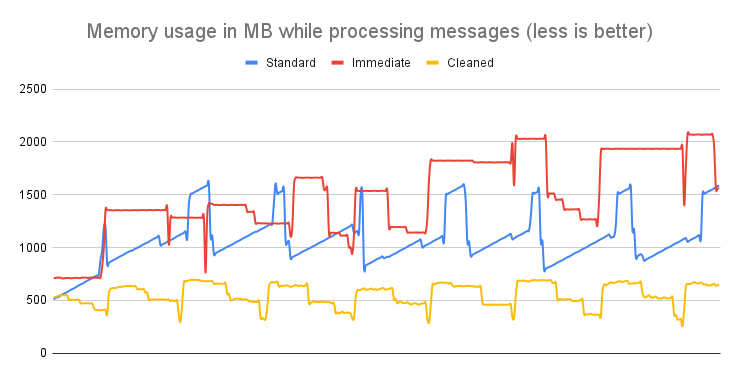
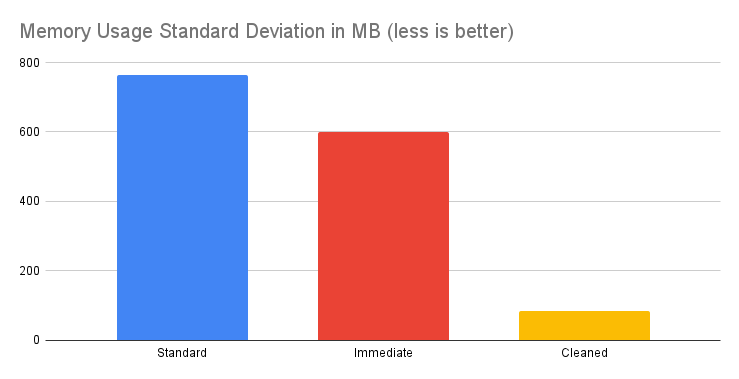
**Conclusion**: For messages approximately 1MB in size, the Cleaner API proves invaluable. It drastically cuts memory usage and stabilizes memory consumption patterns, reducing fluctuations and ensuring smoother, more efficient operations.
#### How does it work / Statistics / Message size of 100KB
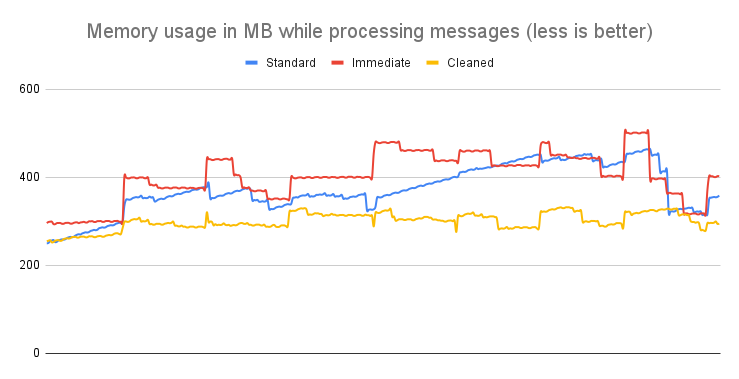
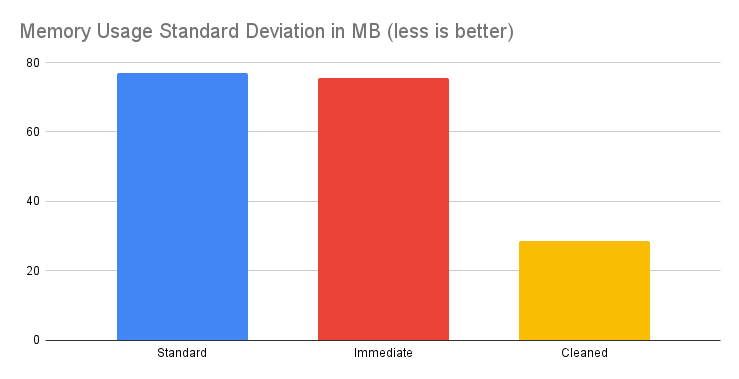
**Conclusion**: For messages around 100KB in size, the Cleaner API still demonstrates a notable impact. While the memory savings might not be as dramatic as with 1MB messages, the reduction in memory usage and stabilization of consumption patterns remain significant, underscoring the API's effectiveness also at this size.
#### How does it work / Statistics / Message size of 10KB
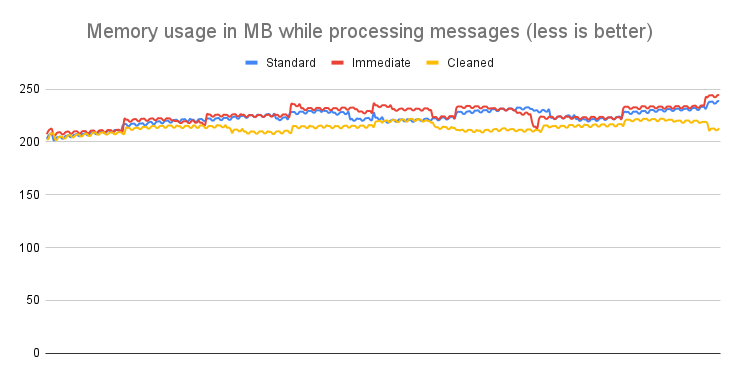
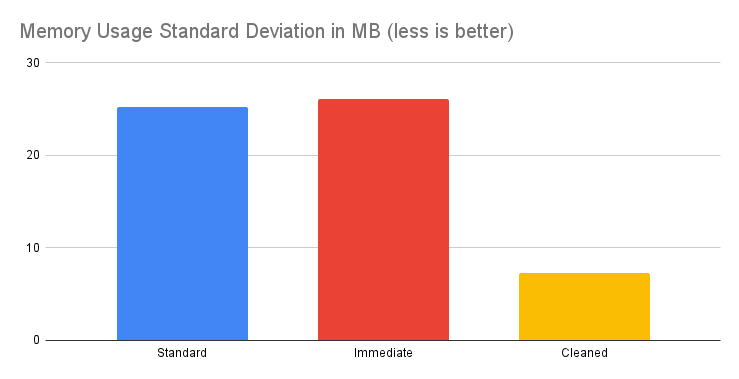
**Conclusion**: When processing messages of approximately 10KB, the Cleaner API's influence is more nuanced. The memory savings hover around 4-5%, which might seem modest compared to larger payloads. However, the standout benefit lies in the considerable reduction in standard deviation. This reduction means memory usage is more predictable, leading to improved and more consistent operational performance.
#### How does it work / Statistics / Message size of 1KB
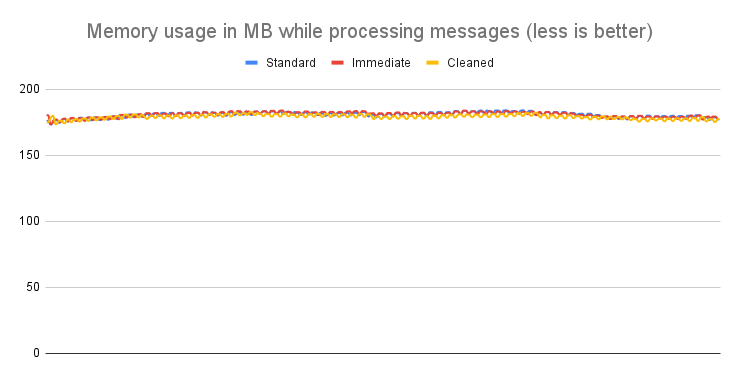
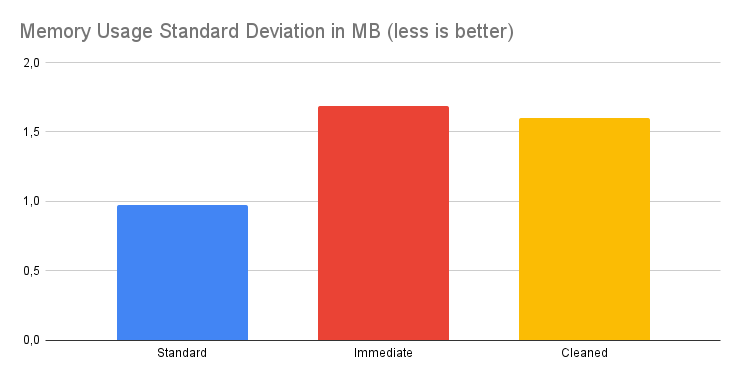
**Conclusion**: For messages approximating 1KB in size, the impact of employing the Cleaner API is virtually nonexistent. Its application doesn't notably affect the memory usage metrics for such small messages. However, it's worth noting that even if most messages are of this size, there could be occasional or periodic inflows of larger payloads. In such scenarios, the Cleaner API can help manage these sporadic spikes in memory usage. Therefore, even with predominantly 1KB messages, integrating the Cleaner API can be a prudent strategy if there's an anticipation of intermittently receiving messages with increased payloads.
### How does it work / Limitations
The Cleaner API offers several advantages, especially when it comes to efficiently managing memory for larger payloads. However, as with any tool or feature, there are certain limitations that users should be aware of:
- **Overhead**: Despite its design focus on being lightweight and efficient, the Cleaner API introduces a small overhead. This is associated with the operation of releasing the data from memory.
- **Not Suitable for Tiny Payloads**: The efficacy of the Cleaner API is more pronounced for larger message payloads, typically those sized 10KB and above. When dealing with tiny payloads, the memory management benefits are negligible, and the overhead might overshadow any gains.
- **Cleaned Messages and DLQ**: Messages that have been cleaned using the Cleaner API can't be dispatched to the Dead Letter Queue (DLQ). This underscores the importance of ensuring that any `#mark_as_consumed` operations happen strictly after complete processing.
- **Marking as Consumed When Cleaning and DLQ**: When using the Cleaner API in conjunction with a topic with a Dead Letter Queue configured, it's required to ensure each message is `#marked_as_consumed` before invoking the `#clean!` method. Please do so to avoid inconsistencies and potential errors, as cleaned messages cannot be dispatched to the DLQ.
- **Payload Availability for Metrics and Reporting**: Once a message has been cleaned, its payload and raw payload are no longer accessible. If you depend on these payloads for metrics, logging, or reporting purposes, you must gather and store this information before invoking the cleaning operation.
- **Lifecycle Hooks Limitations**: When working with lifecycle hooks like `#shutdown` or `#revoked`, it's crucial to approach carefully if Cleaner API has been used on the messages. The payloads for these cleaned messages will be unavailable from these hooks, which could affect operations relying on them.
Understanding these limitations is essential for users to effectively and efficiently leverage the Cleaner API without encountering unforeseen issues or complications in their processes.
### How does it work / Example Use Cases
- **Log Aggregation and Analysis Systems**: Many enterprises gather vast amounts of log data from various sources like applications, servers, and network devices. Processing this data in real time often involves deserializing large chunks of data to analyze patterns, anomalies, or security breaches. After processing, the payload data often remains in memory until the whole batch is analyzed, causing inefficiencies.
- **E-Commerce Transaction Processing**: E-commerce platforms process millions of daily transactions, including user data, product information, and payment details. Each transaction can be a sizeable chunk of data.
- **IoT Data Ingestion**: IoT devices can send vast amounts of data, especially in smart cities or industrial IoT scenarios. This data often contains sensor readings, device status updates, and more. The Cleaner API can help quickly clean up processed data, ensuring efficient memory usage as millions of messages pour in.
- **Financial Data Analysis**: Financial institutions process large datasets daily, including stock market feeds, transactions, and trading data. These data packets can vary in size and come in rapid succession. To ensure that analysis tools and algorithms function at peak efficiency, the Cleaner API can be employed to release memory as soon as a data packet has been processed, maintaining system responsiveness.
In all these use cases, the key value of the Cleaner API is in enhancing memory management, ensuring that systems maintain optimal performance even when dealing with substantial or varied data loads with various message sizes.
### How does it work / See Also
- [Pro Iterator API](https://karafka.io/docs/Pro-Iterator-API.md) - Iterator API for message processing
- [Admin API](https://karafka.io/docs/Infrastructure-Admin-API.md) - Administrative operations
- [Pro Offset Metadata Storage](https://karafka.io/docs/Pro-Consumer-Groups-Offset-Metadata-Storage.md) - Storing metadata with offsets
---
*Last modified: 2026-06-11 12:27:01*