Karafka's Scheduled Messages feature allows users to designate specific times for messages to be sent to particular Kafka topics. This capability ensures that messages are delivered at predetermined times, optimizing workflows and allowing for precise processing and message handling timing in case a message should not arrive immediately.
Conceptually, it works in a similar way to the [ETF1 Kafka Message Scheduler](https://github.com/etf1/kafka-message-scheduler/).
## How Does It Work?
Karafka's Scheduled Messages feature provides a straightforward approach to scheduling Kafka messages for future delivery, allowing users to set precise timings for when messages should reach the desired topics. Using a specialized API, Karafka allows users to easily specify the delivery time for messages without having to handle the complex scheduling details directly. This is achieved by wrapping the messages in an envelope that includes all necessary scheduling information and dispatching them to a special "in-the-middle" topic, which is then managed automatically by Karafka.
Each day at midnight, Karafka's scheduler, a dedicated consumer, reloads and scans a specific Kafka topic designated for storing scheduled messages. This routine includes loading new messages meant for the day, ensuring they are ready for dispatch at specified times. To maintain a continuous operation, the scheduler dispatches messages at regular intervals, typically every 15 seconds, which is configurable. This ensures that all scheduled messages are delivered when needed.
One key aspect of Karafka's handling of scheduled messages is its treatment of message payloads. It ensures the payload and user headers remain untouched by proxy-passing them with added trace headers.

*Illustration presenting how Scheduled Messages work.
When Karafka dispatches a scheduled message, it also produces a special tombstone message that goes back to the scheduled messages topic. This tombstone message serves as a marker to indicate that a particular message has already been dispatched. In case of a system failure or a consumer group rebalance, this tombstone prevents the same message from being sent multiple times, ensuring that messages are processed exactly once.
The tombstone message effectively sets the message payload to null using the same key as the scheduled message. This is recognized by Kafka, which then uses this marker to eventually remove the message from the schedules topic. Kafka's log compaction feature looks for these null payloads and purges them during the cleanup, preventing duplicate processing and optimizing the storage by removing obsolete data. Additionally, this compaction process has the benefit of streamlining Karafka's daily schedule loading. After midnight, when the scheduler re-reads the topic to load the day's schedule, compacted messages marked with tombstone messages and subsequently removed are not even sent from Kafka. This reduces the amount of data the scheduler needs to process, allowing for faster and more efficient loading of the daily schedule, thus enhancing the overall performance and responsiveness of the scheduling system.
### How Does It Work? / Enabling Scheduled Messages
Karafka provides a convenient API to facilitate the scheduling of messages directly within your routing configuration. By invoking the `#scheduled_messages` method, you can easily set up a consumer group and topics dedicated to handling your scheduled messages. This setup involves minimal configuration from the user's end and uses Karafka's built-in declarative topics API for needed topics management.
```ruby
class KarafkaApp < Karafka::App
setup do |config|
# ...
end
routes.draw do
scheduled_messages('scheduled_messages_topic_name')
end
end
```
Karafka will automatically set up the necessary configurations for this topic and the states topic, including:
- Enabling specific serializers and deserializers tailored for handling scheduled message formats.
- Configuring Kafka consumer settings that are optimized for message scheduling, such as enabling manual offset management and log compaction policies.
- Establishing periodic execution checks to ensure messages are dispatched according to their scheduled times.
This approach simplifies setting up scheduled messages, making them accessible without requiring deep dives into Kafka's configuration details.
#### How Does It Work? / Enabling Scheduled Messages / Creating Required Kafka Topics
When `scheduled_messages` is invoked, this command will automatically create appropriate entries for Karafka [Declarative Topics](https://karafka.io/docs/Infrastructure-Declarative-Topics.md). This means that all you need to do is to run the:
```shell
bundle exec karafka topics migrate
```
Two appropriate topics with the needed configuration will be created.
If you do not use Declarative Topics, make sure to create those topics manually with below settings:
| Topic name |
Settings |
| YOUR_SCHEDULED_TOPIC_NAME |
-
partitions:
5
-
replication factor: aligned with your company policy
-
'cleanup.policy': 'compact'
-
'min.cleanable.dirty.ratio': 0.1
-
'segment.ms': 3600000 # 1 hour
-
'delete.retention.ms': 3600000 # 1 hour
-
'segment.bytes': 52428800 # 50 MB
|
| YOUR_SCHEDULED_TOPIC_NAME_states |
-
partitions:
5
-
replication factor: aligned with your company policy
-
'cleanup.policy': 'compact'
-
'min.cleanable.dirty.ratio': 0.1
-
'segment.ms': 3600000 # 1 hour
-
'delete.retention.ms': 3600000 # 1 hour
-
'segment.bytes': 52428800 # 50 MB
|
!!! warning "Topic Partition Consistency Required"
When manually creating or reconfiguring topics for scheduled messages, ensure that both topics have the **same** number of partitions. This consistency is crucial for maintaining the integrity and reliability of the message scheduling and state tracking processes.
#### How Does It Work? / Enabling Scheduled Messages / Replication Factor Configuration for the Production Environment
Setting the replication factor for Kafka topics used by the scheduled messages feature to more than 1 in production environments is crucial. The replication factor determines how many copies of the data are stored across different Kafka brokers. Having a replication factor greater than 1 ensures that the data is highly available and fault-tolerant, even in the case of broker failures.
For example, if you set a replication factor of 3, Kafka will store the data on three different brokers. If one broker goes down, the data is still accessible from the other two brokers, ensuring that your recurring tasks continue to operate without interruption.
Here is an example of how to reconfigure the scheduled messages topics so they have replication factor of 3:
```ruby
class KarafkaApp < Karafka::App
setup do |config|
# ...
end
routes.draw do
scheduled_messages(:scheduled_messages) do |schedules_topic, states_topic|
schedules_topic.config.replication_factor = 2
states_topic.config.replication_factor = 2
end
end
end
```
#### How Does It Work? / Enabling Scheduled Messages / Advanced Configuration
Karafka’s Scheduled Messages feature is designed to be highly configurable to meet diverse application requirements and optimize operational performance. The configuration phase allows you to tailor various aspects of handling scheduled messages, including dispatch frequency, message batching, and producer specifications.
During the initial setup of the Karafka application, you have the opportunity to adjust settings that affect the behavior of scheduled messages, such as:
- **Dispatch Interval**: The frequency with which Karafka checks for and dispatches messages.
- **Batch Size**: The number of messages dispatched in a single batch. This is crucial for systems with high message volumes or limited resources, where managing load is essential for maintaining performance.
- **Producer Customization**: You can specify which producer Karafka should use for scheduled messages. This allows the integration of custom logic, such as specific partitioning strategies or the usage of a transactional producer.
- **Topic Naming**: The naming of topics used for message states can be customized to fit naming conventions or organizational policies, providing clarity and consistency in resource management.
```ruby
Karafka.setup do |config|
# Dispatch checks every 5 seconds
config.scheduled_messages.interval = 5_000
# Dispatch up to 200 messages per batch
config.scheduled_messages.flush_batch_size = 200
end
```
Refer to the code sources for more details.
### How Does It Work? / Multi-Application Deployments
When deploying Karafka's Scheduled Messages feature across multiple applications within the same Kafka cluster, it is **essential** to ensure proper isolation and prevent conflicts between applications. This section covers configuration for managing scheduled messages in multi-application environments.
#### How Does It Work? / Multi-Application Deployments / Consumer Group Isolation
The most critical aspect of running scheduled messages across multiple applications is ensuring that each application uses a unique consumer group ID and dedicated schedule topics. This prevents applications from interfering with each other's message processing and ensures that scheduled messages are handled correctly by their intended applications.
```ruby
# Application 1 - "orders_app"
class OrdersApp < Karafka::App
setup do |config|
config.client_id = "orders_app-#{Process.pid}-#{Socket.gethostname}"
# Unique group ID for this application
config.consumer_group_id = 'orders_app_schedules_group'
# Other config here...
end
routes.draw do
scheduled_messages('scheduled_messages_orders')
end
end
# Application 2 - "billing_app"
class BillingApp < Karafka::App
setup do |config|
config.client_id = "billing_app-#{Process.pid}-#{Socket.gethostname}"
# Different group ID for this application
config.consumer_group_id = 'billing_app_schedules_group'
# Other config here...
end
routes.draw do
scheduled_messages('scheduled_messages_billing')
end
end
```
#### How Does It Work? / Multi-Application Deployments / Dedicated Topic Strategy
Each application **needs** to use its own dedicated topics for scheduled messages:
| Application |
Scheduled Messages Topic |
States Topic |
| Orders App |
scheduled_messages_orders |
scheduled_messages_orders_states |
| Billing App |
scheduled_messages_billing |
scheduled_messages_billing_states |
| Inventory App |
scheduled_messages_inventory |
scheduled_messages_inventory_states |
### How Does It Work? / Scheduling Messages
To schedule a message, you must wrap your regular message content and additional scheduling information. This is done using the `Karafka::Pro::ScheduledMessages.schedule` method. This method requires you to prepare the message just as you would for a standard Kafka message, but instead of sending it directly to a producer, you wrap it to include scheduling details.
Below, you can find exact details on how to do this:
1. **Prepare Your Message**: Construct your message payload and any associated headers as usual for a Kafka message.
```ruby
message = {
topic: 'events',
payload: { type: 'inserted', count: 123 }.to_json
}
```
1. **Define the Delivery Time**: Determine when the message should be dispatched. This time is specified as a Unix epoch timestamp and passed as the epoch parameter.
```ruby
# Make sure to use a Unix timestamp format
future_unix_epoch_time = 15.minutes.from_now.to_i
```
1. **Wrap the Message**: Use the schedule method to wrap your message with the scheduling details:
```ruby
enveloped = Karafka::Pro::ScheduledMessages.schedule(
message: message,
epoch: future_unix_epoch_time,
envelope: {
# The Kafka topic designated for scheduled messages
# Please read other sections on the envelope details available
topic: 'scheduled_messages_topic'
}
)
```
1. **Dispatch the Wrapped Message**: Once the message is wrapped with all required scheduling details, the resulting hash represents a fully prepared scheduled message. This message can then be dispatched like any other message in Karafka:
```ruby
Karafka.producer.produce_async(enveloped)
```
This call places the wrapped message into the designated scheduling topic, which remains until the specified epoch time is reached. At that time, Karafka's internal scheduling mechanism automatically processes and dispatches the message to its intended destination.
#### How Does It Work? / Scheduling Messages / Message Key Uniqueness and Ordering Management
When using this feature, understand dispatched messages keys and their uniqueness operations. Each message sent to the scheduler must have a distinct key within its partition to ensure accurate scheduling and prevent any potential overlaps or errors during the dispatch process.
By default, Karafka generates a unique key for each scheduled message envelope. This key is a combination of the topic to which the message will eventually be dispatched and a UUID. The formula used is something akin to: "{target_topic}-{UUID}". This key is then assigned to the `:key` field in the envelope, ensuring that each message is uniquely identified within the scheduling system.
This generated key serves multiple purposes:
- **Uniqueness**: Guarantees that each message can be uniquely identified and retrieved.
- **Management**: Facilitates updating or canceling the scheduled dispatch of the message.
Suppose the original message contains `partition_key` or a direct `partition` reference. In that case, Karafka will also attempt to use any of those values as the envelope `partition_key` to ensure that consecutive messages with the same details are always dispatched to the same partition and later sent to a target topic in order.
If you prefer to use your key instead of relying on the auto-generated key, you can provide your chosen key directly in the envelope. When you specify your key this way, Karafka will use it without generating a new one. This approach allows you to maintain consistency or alignment with other systems or data structures you might be using:
```ruby
enveloped = Karafka::Pro::ScheduledMessages.schedule(
message: message,
epoch: future_unix_epoch_time,
envelope: {
topic: 'scheduled_messages_topic',
# You can set key
key: 'anything you want',
# As well as the partition key
partition_key: 'anything'
}
)
```
!!! warning "Ensure Unique Custom Keys"
The custom key you use must remain unique within the scheduler topic's partition context. Reusing the same key for multiple messages in the same partition is not advisable, as each subsequent message will overwrite the previous one in the scheduling system, regardless of their scheduled times.
If you must ensure that particular messages are dispatched in a specific order, you can use the `partition_key` field in the envelope. While the key may still be automatically generated to maintain uniqueness, setting the `partition_key` to a value that matches the underlying message key ensures that:
- All related messages (sharing the same raw message key) are dispatched to the same partition.
- The order of messages is preserved as per the sequence of their scheduling.
This strategy uses Kafka's partitioning mechanism, providing a predictable processing order. Messages with the same `partition_key` are guaranteed to be sent to the same partition and thus processed in the order they were sent:
#### How Does It Work? / Scheduling Messages / Cancelling Scheduled Messages
Karafka provides a straightforward mechanism to cancel scheduled messages before they are dispatched. This capability is essential for scenarios where conditions change after a message has been scheduled and the message is no longer required or needs to be replaced.
To cancel a scheduled message, you will use the `#cancel` method provided by Karafka's Scheduled Messages feature. This method lets you specify the unique key of the message you want to cancel. This key should be the same as the one used in the message envelope when the message was originally scheduled.
To cancel a scheduled message:
1. **Identify the Message Key**: Locate the unique key of the message you intend to cancel. This is the key that was specified or generated when the message was initially scheduled.
1. **Specify the Topic**: Provide the topic where the scheduled message resides. This is essential because Karafka can handle multiple scheduling topics, and specifying the correct topic ensures the message is accurately identified and targeted for cancellation.
1. **Invoke the `cancel` Method**: Use the `cancel` method to create a cancellation request for the scheduled message. This method requires the unique key and the topic to formulate the cancellation command properly.
```ruby
cancellation_message = Karafka::Pro::ScheduledMessages.cancel(
key: 'your_message_key',
envelope: { topic: 'your_scheduled_messages_topic' }
)
```
1. **Dispatch the Cancellation Message**: After generating the cancellation message, it must be dispatched using Karafka's producer to ensure the cancellation is processed. This step finalizes the cancellation by publishing the tombstone message to the scheduling topic.
```ruby
Karafka.producer.produce_sync(cancellation_message)
```
The unique key is critical in the cancellation process for several reasons:
- **Targeting the Correct Message**: It ensures that the exact message intended for cancellation is correctly identified.
- **Avoiding Conflicts**: By maintaining unique keys for each message, you prevent potential issues where multiple messages might be inadvertently affected by a single cancellation command.
!!! tip "Custom Keys and Automatic Key Generation"
When scheduling a message, if you choose to use a custom key or rely on the automatically generated key by Karafka, use the same key consistently for both scheduling and canceling the message. This consistency helps prevent errors and ensures that the correct message is targeted for cancellation.
!!! tip "Handling Cancellations with `partition_key`"
If the message was scheduled with a `partition_key` to maintain a specific order or partition consistency, it is advisable to use the same `partition_key` during cancellation. This practice helps manage related messages within the same partition effectively and maintains the order and integrity of operations within that partition.
#### How Does It Work? / Scheduling Messages / Updating Scheduled Messages
Karafka's Scheduled Messages feature allows updating messages that have already been scheduled but not yet dispatched. This functionality is crucial when a scheduled message's content, timing, or conditions need to be modified before its dispatch.
Updating a scheduled message in Karafka involves a straightforward process similar to scheduling a new message, with a key distinction: you must use the same unique envelope key used for the original scheduling. This ensures that the new message parameters overwrite the old ones in the scheduling system.
To update the scheduled message:
1. **Identify the Original Envelope Key**: Use the same envelope key that was assigned during the initial scheduling of the message. This key is crucial for targeting the correct message for updates.
1. **Prepare the Updated Message**: Create the new message payload as you would for any Kafka message. Include any changes to the message content or any additional headers needed.
1. **Set the New Dispatch Time**: If the timing needs to be changed, determine the new dispatch time. This time should be specified as a Unix epoch timestamp.
1. **Use the `schedule` Method**: Employ the `schedule` method to wrap your updated message with the scheduling details, using the same key and specifying the new or unchanged dispatch time:
```ruby
updated_message = Karafka::Pro::ScheduledMessages.schedule(
message: new_message_to_replace_old,
epoch: new_future_unix_epoch_time,
envelope: {
topic: 'scheduled_messages_topic',
# Same key as the original message
key: original_envelope_key
}
)
```
1. **Dispatch the Updated Message**: Send the updated message using Karafka’s producer. This step replaces the original scheduled message with the new content and timing in the scheduling system:
```ruby
Karafka.producer.produce_async(updated_message)
```
### How Does It Work? / Monitoring and Metrics
Karafka's Scheduled Messages feature integrates with standard monitoring tools provided by Karafka and its Web UI, allowing for visibility into the system's performance and behavior. However, understand how this feature consumer may deviate from the standard consumer behaviors.
Karafka treats scheduled messages like any other messages within its ecosystem:
- **Message Consumption Tracking**: Karafka marks messages as consumed in the scheduling topics as they arrive. This standard practice allows monitoring systems to track the progress and detect if there are delays or backlogs in message processing.
- **Visibility in Karafka Web UI**: The Karafka Web UI provides a straightforward way to view message consumption status, including any system lag. This is particularly useful for quickly diagnosing issues or confirming that scheduled messages are being processed as expected.
Due to the nature of how scheduled messages are managed:
- **Daily Reloads**: Around midnight, when Karafka reloads the daily schedules, there are expected spikes in activity within the scheduled messages topics. This behavior is normal and should be accounted for in performance metrics and monitoring setups.
- **Message Throughput**: Monitoring systems should be configured to differentiate between regular message throughput and the spikes caused by these reloads. Understanding this distinction will help in accurately assessing system performance without raising false alarms during expected spikes.
Karafka enhances monitoring capabilities by publishing regular messages to a states topic, which contains crucial data about scheduled operations:
- **Daily Schedules**: Messages sent to the states topic include data on the number of messages scheduled for dispatch on a given day. This provides a clear metric to gauge the volume of upcoming message dispatches and prepare for potential load increases.
- **Consumer State Reporting**: Each message in the state topic also reports the current state of the consumer handling a given partition.
The states can be:
- `loading`: Indicates that the consumer is currently refreshing the data during the daily reload or after a rebalance.
- `loaded`: Signifies that all scheduled data is in memory and that dispatches proceed uninterrupted.
These state updates are vital for understanding the message scheduling system's real-time status, providing insights into both routine operations and any issues that may arise.
#### How Does It Work? / Monitoring and Metrics / Consumer Data and Error Reporting
Aside from the periodic state updates sent to the states topic, the error reporting and data handling for consumers of scheduled messages do not differ from other Karafka consumers:
- **Error Handling**: Any errors encountered by the scheduled message consumers are handled and reported like other consumers within the Karafka system.
- **Metrics Collection**: Metrics for error rates, processing times, and other key performance indicators are collected and can be viewed in the Karafka Web UI or through integrated monitoring tools.
This consistent monitoring and error reporting approach ensures that administrators and developers can use familiar tools and processes to manage and troubleshoot scheduled message consumers, simplifying system maintenance and oversight.
### How Does It Work? / Web UI Management
Karafka's Web UI displays daily dispatch estimates and the current loading state of partitions involved in scheduled messaging. This visibility is crucial after midnight reloads, allowing administrators to detect operational delays or issues quickly.
Additionally, the Web UI offers a detailed exploration of scheduled messages, showing specific information about each message queued for future dispatch. Users can view scheduled times, payload content, and other relevant metadata, aiding in monitoring and verifying the scheduling system's effectiveness.
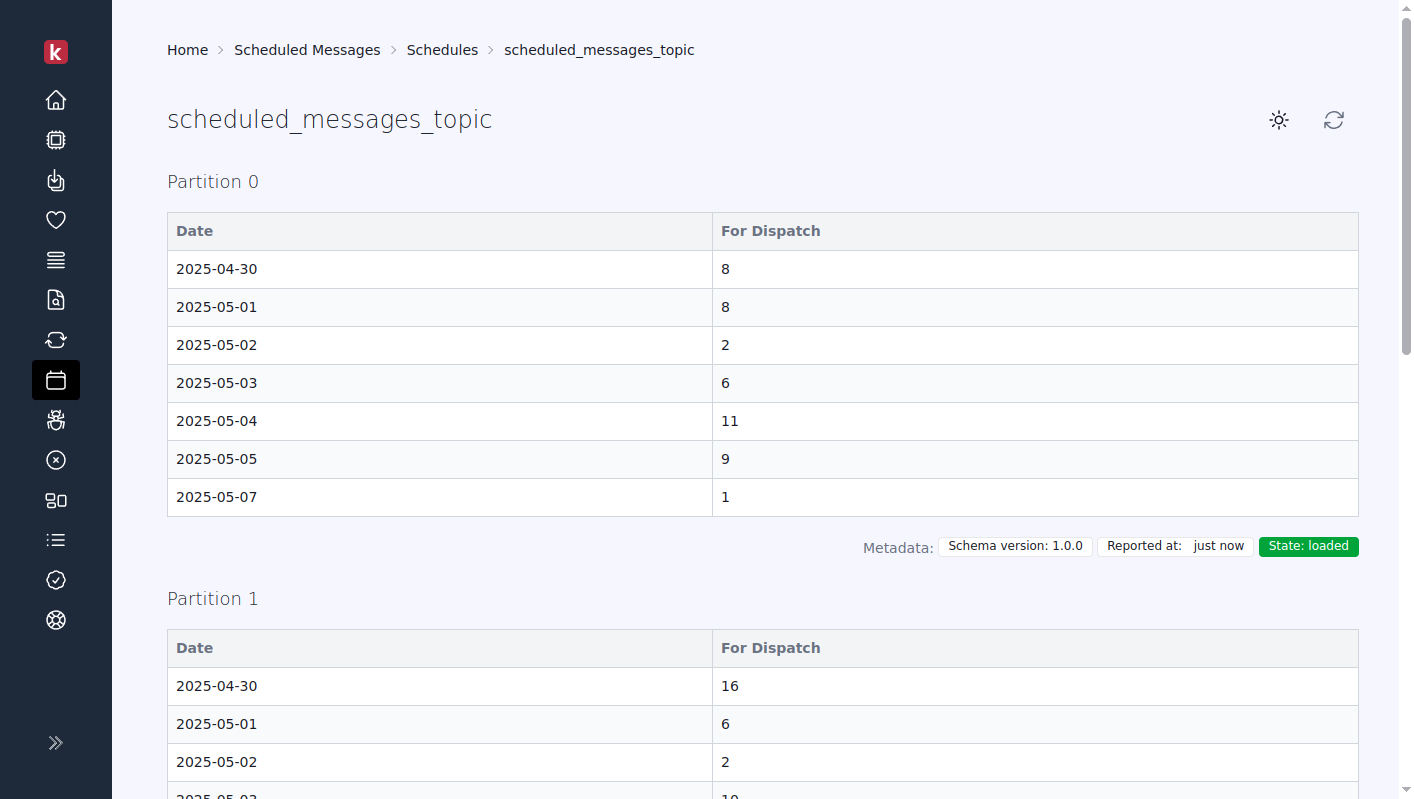
!!! warning "Future Day Cancellation Reporting Limitations"
The Web UI scheduled messages reporting will not reflect cancellations of scheduled messages for days beyond the current day. This limitation is a performance optimization that allows the system to store statistics for upcoming days without having to maintain complete data for each future day.
While cancellation statistics for the current day are 100% accurate, cancellations for future days will only be reflected in the reporting once that day becomes the current day. This approach significantly reduces memory usage and processing overhead, as the system only needs to maintain detailed schedule data for the current day rather than for all future scheduled messages.
When you cancel a scheduled message for a future day, the cancellation is properly recorded in Kafka, but the Web UI statistics will not be updated until that day arrives and the full schedule for that day is loaded into memory.
### How Does It Work? / Error Handling and Retries
This feature is designed to ensure error handling and efficient retry mechanisms, minimizing the potential impact of errors on scheduled message dispatches. Here is an overview of how error handling and retries are managed:
**Key Points on Error Handling:**
- **No Deserialization of Payload**: Karafka does not deserialize the payload of scheduled messages; it passes the raw data through. This approach eliminates serialization errors, common sources of faults in message processing systems.
- **Raw Values for Keys and Headers**: Similarly to the payload, Karafka uses raw values for keys and headers. This ensures that the data integrity is maintained without introducing serialization or format errors during the handling process.
- **No Default DLQ (Dead Letter Queue) Strategies**: By default, Karafka does not implement any Dead Letter Queue strategies for intermediate message topics used in scheduling. Any blocking errors may require manual intervention.
**Retry Policies:**
- **Default User Configuration**: Karafka relies on the default retry policies specified in the user's configuration settings. This means that delivery errors and other operational errors will trigger retries according to the predefined rules in the configuration.
- **Handling Dispatch Errors**: While dispatch errors and other issues may cause messages to be dispatched more than once, the system is designed to ensure that no messages are skipped.
**Schema Compatibility and System Upgrades:**
- **Schema Incompatibilities**: When changes to the Karafka schema affect the scheduled messages feature, the system is built to detect these incompatibilities and halt dispatching. This behavior is crucial to prevent issues arising from processing messages with an outdated schema version.
- **Halting Dispatch During Upgrades**: When schema changes are detected, the dispatching process will stop, and it will not resume until the affected components of the system are upgraded to the compatible version. This approach mirrors how critical updates are managed in systems like Karafka's Web UI, ensuring stability and consistency during upgrades.
- **Rolling Deployments**: The halt-on-incompatibility feature supports rolling deployments by allowing parts of a system to be updated incrementally. During this process, message dispatching is safely paused until all components are confirmed to be compatible, minimizing downtime and disruption.
This feature's error handling and retry strategies ensure that the system remains resilient and reliable, even in the face of operational challenges. Its approach to managing dispatch errors, retries, and schema changes ensures that messages are handled appropriately under all circumstances, supporting continuous and dependable operations.
### How Does It Work? / Warranties
Karafka's Scheduled Messages feature offers a set of warranties designed to ensure functionality and reliability within production environments. Here is a summary of the key guarantees and limitations:
- **Message Delivery Guarantee**: Karafka ensures that all scheduled messages will be delivered at least once, minimizing the risk of message loss. However, messages might be delivered multiple times under certain circumstances like network or Kafka cluster disruptions.
- **Timeliness of Message Dispatch**: While Karafka aims to dispatch messages close to their scheduled times, there is a flexibility window influenced by the dispatch frequency (default is every 15 seconds). This means that exact second-by-second scheduling might see slight deviations.
- **System Stability**: Karafka is built to maintain Stability under varying loads and manage daily schedule reloads without significant disruptions. Stability can be affected by external factors such as network performance and server capacity.
- **Application-Level Failures**: Karafka does not cover failures due to issues in consumer application logic or other external application errors.
- **Configuration Dependence**: The warranties assume optimal and correct configuration settings. Misconfigurations or inappropriate settings that impact performance and reliability are not covered.
- **External Dependencies**: Issues caused by external factors, including Kafka cluster performance, network latency, and hardware failures, are outside the scope of these warranties.
#### How Does It Work? / Warranties / Transactional Support
Karafka's Scheduled Messages feature provides transactional support to ensure exactly-once delivery of messages when used with a transactional WaterDrop producer. This support hinges on the proper configuration and execution of message batching and transaction handling within the Karafka ecosystem.
When using a transactional WaterDrop producer, the Scheduled Messages feature can achieve exactly once delivery by including the dispatched message to the target topic and the corresponding tombstone message in a single transaction batch. This approach ensures that both sending the message and marking it as dispatched (via the tombstone) are atomically committed to Kafka, thus preventing any duplication or message loss during processing.
### How Does It Work? / Limitations
While Scheduled Messages offer message scheduling and dispatch capabilities, users should be aware of inherent limitations when integrating this feature into their systems. Understanding these limitations can help you plan and optimize scheduled messages usage within your applications.
1. **Single Delivery Point**: Scheduled messages are designed to be delivered to a specific topic at a predetermined time. Once a message is scheduled, redirecting it to a different topic at runtime is not supported. Message dispatch can be canceled, though.
1. **Lack of Built-In Dead Letter Queue**: Karafka does not provide a built-in Dead Letter Queue (DLQ) mechanism for messages that fail to be processed after all retry attempts. Users must implement their own DLQ handling to manage undeliverable messages systematically.
1. **Dependency on System Clock**: The scheduling mechanism depends on the accuracy and synchronization of system clocks across the Kafka cluster. Time discrepancies between servers can lead to delays in message delivery.
1. **Storage Overhead**: Scheduled messages are stored until their dispatch time arrives. This can lead to increased storage usage on Kafka brokers, especially if large volumes of messages are scheduled far in advance or message payloads are large.
1. **No Real-Time Cancellation Feedback**: When a scheduled message is canceled, there is no immediate feedback or confirmation that the message has been successfully removed from the schedule.
1. **Message Duplication Risks**: Due to the nature of Kafka and the possibility of retries in the event of critical delivery errors, message duplication is a risk unless a transactional producer is used. While Karafka ensures that messages are not lost, duplicate messages may be delivered under certain failure scenarios.
1. **No Priority Queueing**: Karafka does not support priority queueing for scheduled messages. Messages are dispatched in the order they are due, without any mechanism to prioritize specific messages over others, regardless of urgency.
1. **Memory Overhead**: Karafka manages daily schedules by loading them into memory, which means the Karafka process handling these schedules may consume more memory than a regular Karafka consumer. This increase in memory usage can be significant depending on the volume and complexity of the scheduled tasks, requiring careful resource management.
1. **Dispatch Frequency**: The dispatch frequency for scheduled messages is set by default to every 15 seconds, which can introduce inaccuracy to the exact moment of message delivery. While this interval is configurable, the nature of batch processing may not meet the needs of applications requiring precise second-by-second scheduling.
1. **Daily Schedule Management**: Karafka manages schedules daily, which means that after midnight, it refetches all the data to build a new daily schedule. Messages scheduled right after midnight each day until the loading phase is done may be scheduled a bit later due to this data loading. This could introduce delays in message dispatch that are critical for time-sensitive tasks.
1. **High Egress Network Traffic**: Because Karafka rescans all partitions of the scheduling topic after midnight to build daily schedules, this can cause increased egress network traffic. This might result in higher costs when using a Kafka provider that charges for network traffic.
1. **Independent Deployment and Management of Scheduler Consumers**: Due to how Karafka reloads schedules daily and during restarts or rebalances, it is advisable to deploy and manage Karafka consumer processes that handle scheduled messages independently from regular consumer processes. Frequent redeployments or rebalancing of these scheduler consumers can lead to excessive schedule loading from Kafka, increasing network traffic and introducing delays in message scheduling and potential increases in operational costs.
1. **Limited Accuracy of Future State Reporting**: While the state reporting for the current day's scheduled messages is accurate, the accuracy of state reporting for future days is more limited and primarily based on estimates. This estimation can lead to discrepancies, particularly regarding message cancellations:
- **Estimate Nature**: The state information for future days includes all messages scheduled up to the last system check. However, it may not accurately reflect cancellations or other modifications to these messages until the schedules are fully reloaded the following day.
- **Reliance on Daily Reloads**: This limitation is due to the system's design, which relies on daily reloads to update and confirm the accuracy of the scheduled messages. Until this reload occurs, any cancellations made after the last update will not be reflected in the state reports.
### How Does It Work? / Production Deployment
Given this feature's unique operational characteristics, particularly its data-loading patterns, it is advisable to deploy it in a manner that ensures long-running stability and isolates it from other processes.
- **Long-Running Stability**: Scheduled messages are designed to operate in a continuous, long-running manner. This setup is crucial because the feature involves daily reloading of schedules based on predefined times (midnight). Ensuring these processes are not interrupted by deployments or other operational changes is key to maintaining their reliability.
- **Isolation from Other Processes**: Due to the significant resource consumption during data loading phases-both in terms of memory and network bandwidth-it is beneficial to isolate the scheduled messages handling from other processes. This separation helps prevent any potential performance degradation in different parts of your system due to the intensive data-loading activities in scheduled message processing.
#### How Does It Work? / Production Deployment / Best Practices
- **Dedicated Instances**: Consider deploying the scheduled messages feature on dedicated instances or containers. This approach allows for tailored resource allocation, such as CPU, memory, and network bandwidth, which can be adjusted based on the specific demands of the scheduling tasks without affecting other services.
- **Monitoring and Scaling**: Implement monitoring to track the performance and resource utilization of the scheduled messages feature. This monitoring should focus on memory usage, CPU load, and network traffic metrics. Based on these metrics, apply auto-scaling policies where feasible to handle variations in load, especially those that are predictable based on the scheduling patterns.
- **Avoid Frequent Redeploys**: Minimize the frequency of redeployments for the components handling scheduled messages. Frequent restarts can disrupt the scheduling process, especially if they occur during daily data reloads.
- **Update and Maintenance Windows**: If possible, schedule maintenance and updates during off-peak hours. Choose times when the impact on scheduled message processing would be minimal, ideally when there are fewer critical tasks scheduled.
- **Disaster Recovery and High Availability**: Ensure that your deployment strategy includes provisions for disaster recovery and high availability. This could involve replicating the scheduling components across multiple data centers or using cloud services that provide built-in redundancy and failover capabilities.
### How Does It Work? / External Producers Support
Karafka's Scheduled Messages feature is designed with flexibility, allowing integration with external producers beyond Karafka and WaterDrop. This enables scheduled messages to be dispatched from various technologies, including Go, JavaScript, or any other language and framework that supports Kafka producers.
When using external producers to schedule messages, follow a specific header format to ensure Karafka's scheduled message consumer can recognize and correctly process these messages. The required headers are as follows:
- `schedule_schema_version`: Indicates the version of the scheduling schema used, which helps manage compatibility. For current implementations, this should be set to 1.0.0.
- `schedule_target_epoch`: Specifies the Unix epoch time when the message should be dispatched. This timestamp determines when the message will be processed and sent to its target topic.
- `schedule_source_type`: This should always be set to `schedule` to indicate that the message is a scheduled type.
- `schedule_target_topic`: Defines the Kafka topic to which the message should be dispatched when its scheduled time arrives.
- `schedule_target_key`: A unique identifier for the message within its target topic. This key is crucial for ensuring that messages are uniquely identified and managed within the scheduling system.
Additional optional headers can include:
- `schedule_target_partition`: If specified, directs the message to a particular partition within the target topic. This can be crucial for maintaining order or handling specific partitioning strategies.
- `schedule_target_partition_key`: Used to determine the partition to which the message will be routed within the target topic based on Kafka's partitioning algorithm.
When implementing an external producer to schedule messages for Karafka, ensure that the message conforms to the required header format and includes all necessary scheduling information.
### How Does It Work? / Alternatives
When considering alternatives to Scheduled Messages feature, two other options provide distinct approaches to delaying or controlling the timing of message processing: [Delayed Topics](https://karafka.io/docs/Pro-Consumer-Groups-Delayed-Topics.md) and [Piping](https://karafka.io/docs/Pro-Consumer-Groups-Piping.md). Each method has its own advantages and use cases, depending on the specific requirements of your application, so they may also be a viable option worth considering.
#### How Does It Work? / Alternatives / Delayed Topics
Delayed Topics in Karafka provide a mechanism to delay message consumption from specific topics for a set period of time. This is useful when you need to delay message processing globally for a topic without scheduling each message individually.
- **How It Works**: By setting a delay on a topic, Karafka pauses consumption for a specified time before processing the messages. Other topics and partitions are unaffected, allowing for efficient resource utilization.
- **Use Cases**: Delayed Processing is ideal for scenarios like retry mechanisms, buffer periods for additional processing or validation, or temporary postponement during peak traffic.
**Pros**:
- Simple to set up using the `delay_by` option on topics.
- Causes no global lag since only the designated topic is delayed.
- Particularly useful when messages need consistent delays across the entire topic.
**Cons**:
- Delay applies to all messages in the topic uniformly.
- Lack of fine-grained control for scheduling individual messages at specific times.
#### How Does It Work? / Alternatives / Delayed Piping
[Piping](https://karafka.io/docs/Pro-Consumer-Groups-Piping.md) with [Delayed Topics](https://karafka.io/docs/Pro-Consumer-Groups-Delayed-Topics.md) offers an advanced alternative to Scheduled Messages by using both Delayed Processing and Piping to create "time buckets." With this approach, you can create multiple delayed topics (e.g., `messages_5m`, `messages_30m`, `messages_1h`) that act as buffers for different delay durations. Once the delay period expires, messages are piped from these delayed topics to their final destination for processing.
Use Cases:
- **Batch Processing**: When processing time-sensitive data that needs to be delayed by different amounts of time (e.g., 5 minutes, 30 minutes, 1 hour) before final processing, using time buckets is an efficient approach.
- **Time-Windowed Actions**: Triggering actions based on elapsed time (e.g., after 30 minutes or 1 hour) can be easily orchestrated with delayed topics and piping.
- **Throttling or Rate Limiting**: You can effectively manage load or rate-limit processes by distributing messages into time buckets over different periods.
**Pros**:
- Flexibility to create multiple time delays for different types of messages.
- Allows you to group delayed messages into "buckets" based on their time requirements.
- Integration of delayed processing with piping ensures that messages are forwarded to their final destination once their delay expires.
- Simplifies complex workflows that require messages to be processed after various time intervals.
**Cons**:
- More configuration is required, as you need to manage multiple topics for different time delays.
- Timing is still dependent on topic-level delays, so more sophisticated scheduling might be required to fine-tune control over individual messages (beyond the bucket-level delay).
#### How Does It Work? / Alternatives / Choosing Between Alternatives
- **Scheduled Messages**: Best for cases where you need precise control over the exact dispatch time for individual messages.
- **Delayed Processing**: The right choice when you need to delay the processing of all messages in a topic by a uniform time period, providing a sense of reassurance and organization.
- **Piping with Delayed Topics**: Ideal when you need time-bucketed delays for messages (e.g., 5 minutes, 30 minutes, 1 hour) and want messages to be forwarded to a final destination after their respective delays.
### How Does It Work? / Example Use-Cases
- **Regulatory Compliance Reports**: Schedule a message to deliver a critical compliance report right before the audit deadline, ensuring all data is fresh and the submission is timely without last-minute rushes.
- **Data Processing Kickoff**: Send a scheduled message to start a complex ETL process at the start of a financial quarter, ensuring data is processed at the right moment for analysis and reporting.
- **SLA Compliance Check**: Set up a message to trigger an SLA compliance verification exactly when a new service level agreement goes into effect, automating the monitoring process without manual setup each time.
- **Resource Scaling for Event Peaks**: Automate infrastructure scaling by scheduling messages to increase cloud resources just hours before anticipated high-traffic events like online sales or product launches.
- **Personalized User Engagement**: Schedule a message to send a personalized offer to a user on their anniversary of joining your service, enhancing personal connection and loyalty.
- **Feature Activation**: At the start of a promotional period, use a scheduled message to activate a new application feature for all users, ensuring synchronized access for all users.
- **Cache Expiration and Refresh**: Schedule a message to trigger the refresh of a specific cache segment right before its set expiration time. This ensures data remains current without manual monitoring and maintains system performance and reliability.
### How Does It Work? / See Also
- [Pro Delayed Topics](https://karafka.io/docs/Pro-Consumer-Groups-Delayed-Topics.md) - Delaying message consumption
- [Pro Recurring Tasks](https://karafka.io/docs/Pro-Recurring-Tasks.md) - Scheduling recurring operations
- [Pro Enhanced Active Job](https://karafka.io/docs/Pro-Consumer-Groups-Enhanced-Active-Job.md) - Enhanced job scheduling capabilities
---
*Last modified: 2026-07-24 13:20:46*