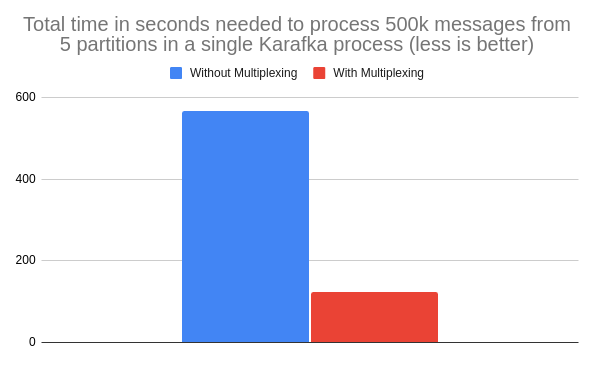
*This example illustrates the performance difference for IO intense work, where the IO cost of processing a single message is 1ms and a total lag of 500 000 messages in five partitions.
## Enabling Multiplexing To enable multiplexing in Karafka, a simple yet crucial step must be taken when defining your subscription groups. By providing the `multiplex` option within your subscription group definition, you instruct Karafka to initiate multiplexing for that particular group: ```ruby class KarafkaApp < Karafka::App setup do |config| # ... end routes.draw do # Always establish two independent connections to this topic from every # single process. They will be able to poll and process data independently subscription_group 'events' do multiplexing(max: 2) topic :events do consumer EventsConsumer end end end end ``` Multiplexing also works for subscription groups with multiple topics: ```ruby class KarafkaApp < Karafka::App setup do |config| # ... end routes.draw do # Always establish two independent connections to those topics from every # single process. They will be able to poll and process data independently subscription_group 'main' do multiplexing(max: 2) topic :events do consumer EventsConsumer end topic :notifications do consumer NotificationsConsumer end end end end ``` !!! note "Proper Placement of `#multiplexing` configuration" The `#multiplexing` method must be used exclusively within a `#subscription_group` block. It is not suitable for routing without an explicit subscription group definition. ```ruby routes.draw do # This will NOT work - will raise undefined method multiplexing(max: 2) # Always define your subscription group and apply multiplexing directly on it subscription_group :main do multiplexing(max: 2) topic :events do consumer EventsConsumer end end end ``` Once you have configured multiplexing in your routing settings, no additional steps are required for it to function. Your application will start processing messages from multiple partitions simultaneously, leveraging the benefits of multiplexing immediately and seamlessly. ### Enabling Multiplexing / Configuration API The actual multiplexing API provides these options: ```ruby subscription_group 'events' do multiplexing( min: 1, # Minimum connections (for dynamic mode) max: 3, # Maximum connections boot: 2 # Connections to start with (dynamic mode) ) topic :events do consumer EventsConsumer end end ``` The following configuration options are available:| Option | Type | Default | Description |
|---|---|---|---|
min |
Integer, nil | nil (sets to max) |
The minimum multiplexing count. Setting this to nil or not setting it at all will set it to the max value, effectively turning off dynamic multiplexing and ensuring a stable number of multiplexed connections. |
max |
Integer | 1 | The maximum multiplexing count. This defines the upper limit for the number of connections that can be multiplexed. |
boot |
Integer, nil | nil (defaults to half of max or min if min is set) |
Specifies how many listeners should be started during the boot process by default in the dynamic mode. If not set, it picks half of max as long as possible. Otherwise, it goes with min. |

*This diagram illustrates the upscaling and downscaling flow for dynamic multiplexing.
!!! note "Persistent Connection in Dynamic Mode" Even when operating in dynamic mode, Karafka maintains a minimum of `min` active connections to Kafka at all times for each multiplexed subscription group. This ensures continuous communication and readiness to handle assignments, even when no partitions are currently assigned to it. Karafka's design guarantees that at least one line is open to Kafka, preventing complete shutdown of connections and ensuring stable, ongoing operation. !!! note "Controlled Connection Adjustments" Karafka uses a controlled approach to connection adjustments to maintain system stability when using Dynamic Multiplexing. Karafka will perform at most one change per minute for each consumer group. This deliberate pacing ensures that the system does not destabilize from rapid, frequent changes. As a result, while adapting to new conditions, the entire cluster may take some time to reach a stable and consistent state. This methodical approach is crucial for preserving the integrity and performance of the system as it dynamically adjusts to changing demands. ### Enabling Multiplexing / Dynamic Multiplexing / Enabling Dynamic Multiplexing There are two things you need to do to fully facilitate dynamic multiplexing: 1. Make sure you use an advanced rebalance strategy either globally or within the selected subscription group: **Recommended (Kafka 4.0+ with KRaft):** ```ruby class KarafkaApp < Karafka::App setup do |config| config.kafka = { # Other kafka settings... 'group.protocol': 'consumer' # KIP-848 } end routes.draw do # ... end end ``` **Alternative (Older Kafka versions):** ```ruby class KarafkaApp < Karafka::App setup do |config| config.kafka = { # Other kafka settings... 'partition.assignment.strategy': 'cooperative-sticky' } end routes.draw do # ... end end ``` !!! warning "Always Use Advanced Rebalance Strategy with Dynamic Mode" An advanced rebalance strategy ([KIP-848](https://karafka.io/docs/Kafka-New-Rebalance-Protocol.md) or `cooperative-sticky`) is strongly recommended for optimal performance in dynamic mode. Without it, every change in connection count (upscaling or downscaling) will trigger a consumer group-wide rebalance, potentially causing processing delays. These strategies minimize disruptions by allowing more gradual and efficient rebalancing, ensuring smoother operation and more consistent throughput. !!! warning "Caution Against Using Dynamic Connection Multiplexing with Long-Running Jobs" Avoid dynamic connection multiplexing for long-running jobs to prevent frequent rebalances, which can disrupt processing and extend execution times. Use stable, dedicated connections for better reliability and efficiency. 2. Configure the `multiplexing` feature with a `min` flag set to a minimum number of connections you want to keep: ```ruby class KarafkaApp < Karafka::App setup do |config| # ... end routes.draw do # Establish at most three connections and shut down two if not needed. Start with 2. subscription_group 'events' do multiplexing(min: 1, max: 3, boot: 2) topic :events do consumer EventsConsumer end end end end ``` ### Enabling Multiplexing / Dynamic Multiplexing / Benefits of the Dynamic Approach - **Efficiency and Performance**: By optimizing resource use and ensuring each connection has a balanced share of partitions, Karafka maintains high efficiency and performance even as data volumes and structures change. - **Cost-Effectiveness**: Reduces operational costs by using resources only when necessary and as dictated by the structure and distribution of Kafka partitions. - **Scalability**: Supports the dynamic and fluctuating nature of distributed data systems without manual intervention, ensuring that the system can seamlessly adapt to varying partition loads. - **Improved Parallelism**: Enhances the system's ability to process data concurrently across multiple partitions and topics, resulting in faster processing times and higher throughput. ### Enabling Multiplexing / Dynamic Multiplexing / When to Use Multiplexing vs. Alternatives **Use Multiplexing When:** - High-volume, multi-partition scenarios where alternatives don't provide sufficient performance - Connection count is not a primary constraint - You need isolation between partition processing streams **Consider Alternatives When:** - Minimizing connection count is a priority - Working with single-partition topics (use [Virtual Partitions](https://karafka.io/docs/Pro-Virtual-Partitions.md) instead) - librdkafka tuning can achieve similar fairness improvements ### Enabling Multiplexing / Dynamic Multiplexing / Limitations Below, you can find specific considerations and recommendations related to using dynamic mode multiplexing in Karafka. #### Enabling Multiplexing / Dynamic Multiplexing / Limitations / Static Group Membership and Dynamic Mode Multiplexing We do not recommend using static group membership with Multiplexing operating in Dynamic mode. Multiplexing in Dynamic mode involves frequent changes in group composition, which conflicts with the nature of static group membership that relies on stable consumer identities. This can lead to increased complexity and more prolonged assignment lags. However, Multiplexing can be used without issues if Dynamic mode is not enabled. In this configuration, consumers maintain a more predictable group composition, which aligns well with the principles of static group membership and ensures a more stable and efficient operation. ### Enabling Multiplexing / Dynamic Multiplexing / Conclusion The Dynamic Multiplexing feature in Karafka represents a refined approach to managing connections with Kafka clusters. By focusing on partition assignments, Karafka ensures that resources are utilized efficiently, balancing performance needs with cost and resource conservation. This feature is handy for large-scale, distributed applications where partition loads vary significantly. ## Enabling Multiplexing / Memory and Resource Considerations ### Enabling Multiplexing / Memory and Resource Considerations / Connection Resource Usage **With Multiplexing**: Each additional connection consumes more memory as it maintains its own set of buffers, offsets, and other metadata. For large message scenarios, use the [Cleaner API](https://karafka.io/docs/Pro-Cleaner-API.md). **Without Multiplexing**: Lower memory usage, but potentially less parallel processing capability. Compensate with: - Higher [concurrency settings](https://karafka.io/docs/Concurrency-and-Multithreading.md) - [Virtual Partitions](https://karafka.io/docs/Pro-Virtual-Partitions.md) for single-partition parallelism - Better librdkafka tuning for fairness ### Enabling Multiplexing / Memory and Resource Considerations / Memory Usage Impact When employing Multiplexing, each additional connection established by a process consumes more memory as it maintains its own set of buffers, offsets, and other metadata related to its subscribed topics. In scenarios where many connections are established to handle high volumes of data, the memory footprint can increase significantly. This increased memory usage is particularly notable when messages are large or when a high volume of messages is being processed. The system needs to keep track of each message until it's successfully processed and acknowledged. We highly recommend using Multiplexing together with the [Cleaner API](https://karafka.io/docs/Pro-Cleaner-API.md) when possible. ## Enabling Multiplexing / Example Use Cases - **High-Volume Data Streams**: For applications dealing with massive influxes of data, multiple connections can fetch data concurrently, reducing latency and preventing bottlenecks. - **Resource Optimization**: Distribute the load across multiple connections to utilize system resources more effectively, ensuring no single connection becomes a strain point. - **Improved Fault Tolerance**: With multiple connections, if one fails, others continue processing, providing higher availability and reliability. - **Enhanced Throughput**: For systems requiring high throughput, multiple connections can collectively handle more messages per second than a single connection. ## Enabling Multiplexing / Summary Karafka Multiplexing is a powerful tool designed to enhance the performance of your Kafka-based applications, especially under heavy load. Allowing multiple connections to the same topic from a single process provides a robust solution for handling high-volume data streams, optimizing resources, and ensuring high availability. Whether you're dealing with fluctuating workloads, aiming for high throughput, or seeking to improve fault tolerance, Multiplexing can provide significant benefits. --- ## Enabling Multiplexing / See Also - [Concurrency and Multithreading](https://karafka.io/docs/Concurrency-and-Multithreading.md) - Concurrency configuration - [Pro Non-Blocking Jobs](https://karafka.io/docs/Pro-Non-Blocking-Jobs.md) - Non-blocking job processing - [Routing](https://karafka.io/docs/Routing.md) - Routing and subscription group configuration --- *Last modified: 2026-02-24 09:34:26*