# Pausing, Seeking and Rate-Limiting
[Karafka Pro](https://karafka.io/docs/Pro-Getting-Started.md) provides an excellent filtering and [rate-limiting](https://karafka.io/docs/Pro-Rate-Limiting.md) APIs, making it a highly recommended option over manually managing message processing flow. By using Karafka Pro, developers can easily configure filtering and rate limiting on a per-topic basis, which allows them to fine-tune the message processing flow according to the requirements of their application.
Using Karafka Pro for filtering and rate limiting also eliminates the need for developers to manually manage message processing, which can be time-consuming and error-prone. With Karafka Pro, you can rely on a robust and efficient system that automatically takes care of these tasks.
Overall, using Karafka Pro for filtering and rate limiting not only simplifies the development process but also ensures that message processing is handled in a reliable and scalable manner.
---
Karafka allows you to pause processing for a defined time. This can be used, for example, to apply a manual back-off policy or throttling. To pause a given partition from within the consumer, you need to use the `#pause` method that accepts the pause offset (what should be the first message to get again after resuming) and the time for which the pause should be valid.
## Pausing, Seeking and Rate-Limiting / Using the `#pause` API
```ruby
def consume
messages.each do |message|
# Sends requests to an API that can be throttled
result = DispatchViaHttp.call(message)
next unless result.throttled?
# Pause and resume from the first message that was throttled
# Pause based on our fake API throttle backoff information
pause(message.offset, result.backoff)
# We need to return, otherwise the messages loop would continue sending messages
return
end
end
```
!!! note
It is important to remember that the `#pause` invocation does **not** stop the processing flow. You need to do it yourself.
**BAD**:
Without stopping the processing, the `messages#each` loop will continue:
```ruby
def consume
messages.each do |message|
# Wait for 10 seconds and try again if we've received messages
# that are younger than 1 minute
pause(message.offset, 10.seconds * 1_000) if message.timestamp >= 1.minute.ago
save_to_db(message)
end
end
```
**GOOD**:
Invoking `return` after `#pause` will ensure no consecutive messages are processed. They will be processed after pause has expired:
```ruby
def consume
messages.each do |message|
if message.timestamp >= 1.minute.ago
pause(message.offset, 10.seconds * 1_000)
# After pausing do not continue processing consecutive messages
return
end
save_to_db(message)
end
end
```
**GOOD**:
Another good approach is by using the `#find` on messages to detect if throttling is needed and what was the message that was throttled:
```ruby
def consume
throttled = messages.find do |message|
DispatchViaHttp.call(message).throttled?
end
# Done if nothing was throttled
return unless throttled
# Try again in 5 seconds
pause(throttled.offset, 5_000)
end
```
## Pausing, Seeking and Rate-Limiting / Using the `#seek` API
In the context of Apache Kafka, "seeking" refers to moving the consumer's offset to a specific position within a topic's partition. In essence, it allows you to dictate where in the partition the consumer begins (or resumes) reading messages.
### Pausing, Seeking and Rate-Limiting / Using the `#seek` API / Seeking to an Offset
Inside your consumer's `#consume` method, you can use the `#seek` method to set the offset for a specific partition:
```ruby
def consume
results = []
messages.each do |message|
results << Processor.call(message.payload)
end
return if results.all? { |result| result == true }
# Get back by 100 messages and reprocess data if anything went badly
seek(messages.last.offset - 100)
end
```
### Pausing, Seeking and Rate-Limiting / Using the `#seek` API / Seeking to a Point in Time
In Karafka, aside from the traditional offset-based seeking using #seek, you can seek by timestamp as follows:
```ruby
def consume
results = []
messages.each do |message|
results << Processor.call(message.payload)
end
return if results.all? { |result| result == true }
# Get back by an hour of data and reprocess all
seek(Time.now.utc - 60 * 60)
end
```
### Pausing, Seeking and Rate-Limiting / Using the `#seek` API / Seeking the Earliest and Latest Positions
Karafka provides convenient symbols to seek to special positions within a partition without needing to know specific offsets or timestamps. These symbols allow you to jump to the beginning or end of a partition's message log.
#### Pausing, Seeking and Rate-Limiting / Using the `#seek` API / Seeking the Earliest and Latest Positions / Seeking to `:earliest`
The `:earliest` symbol moves the consumer to the very beginning of the partition, starting from the first available message. This is particularly useful when you must reprocess all available data from the start of the topic's retention period.
```ruby
def consume
# Process current batch of messages
messages.each do |message|
result = ProcessMessage.call(message)
# If we detect data corruption or need full reprocessing
if result.requires_full_reprocess?
# Start from the very beginning of the partition
seek(:earliest)
return
end
end
end
```
#### Pausing, Seeking and Rate-Limiting / Using the `#seek` API / Seeking the Earliest and Latest Positions / Seeking to `:latest`
The `:latest` symbol is more nuanced than it might initially appear. It **does not** seek to the last (most recent) available message in the partition. Instead, it seeks to the **high water mark offset**, which represents the position where the **next new message** will be written.
This means that after seeking to `:latest`, the consumer will wait for new messages to arrive rather than processing existing ones. The high water mark is essentially the "end" of the current log, pointing to a message that doesn't exist yet but will be the first to arrive after seeking.
```ruby
def consume
messages.each do |message|
# Check if we're processing stale data
if message.timestamp < 1.hour.ago
# Skip all existing messages and wait for new ones
# This moves to the high water mark, not the last available message
seek(:latest)
return
end
ProcessRealtimeMessage.call(message)
end
end
```
### Pausing, Seeking and Rate-Limiting / Using the `#seek` API / Seeking vs. Offset Position
When utilizing the `#seek` API in Karafka, it's crucial to understand the behavior of offsets and how this method interacts with them. The `#seek` method lets you move the consumer's offset to a specific position within a topic's partition. This capability is essential for controlling exactly where the consumer begins or resumes reading messages in the partition.
By default, when you invoke the `#seek` method, the in-memory offset position (also known as the seek offset) is not reset. This means that the position to which you're seeking won't automatically update the current offset in memory.
Additionally, Karafka implements a safeguard to ensure data consistency and integrity. By default, it prevents committing offsets earlier than the highest offset committed on a consumer instance. This mechanism helps avoid scenarios where a consumer might read and process messages out of order, potentially leading to data duplication or loss.
To address scenarios where you need to explicitly move the consumer's offset and update the in-memory position, the `#seek` method accepts an additional flag: `reset_offset`. When this flag is set to true, Karafka will move the consumer to the specified location and update the in-memory offset to match this new position.
This is particularly useful in cases where you need to process messages from a specific point, regardless of previous commits, or when managing complex consumer behaviors that require precise control over message processing orders.
```ruby
def consume
results = []
messages.each do |message|
results << Processor.call(message.payload)
end
return if results.all? { |result| result == true }
# Get back by 100 messages and reprocess data if anything went badly
# Move the offset position together so when reprocessing, things can be marked again despite
# the most recent offset committed till this point being ahead
seek(messages.last.offset - 100, reset_offset: true)
end
```
### Pausing, Seeking and Rate-Limiting / Using the `#seek` API / Seeking Use Cases
- **Reprocessing Messages**: If there's a need to reprocess certain messages due to application logic changes or errors, you can seek back to an earlier offset to re-read and reprocess the messages.
- **Skipping Faulty Messages**: In scenarios where specific messages might cause processing issues (e.g., due to data corruption), the consumer can skip these by seeking ahead to a subsequent offset.
- **Time-based Processing**: If your messages have a timestamp and you wish to process or reprocess messages from a specific time, you can seek the offset corresponding to that timestamp.
- **Consumer Recovery**: In the event of consumer crashes or restarts, you can use seek to ensure that the consumer starts processing from where it left off, ensuring no missed messages.
- **Testing and Debugging**: During development or debugging, you might want to read specific messages multiple times. Seeking allows you to jump to those messages easily.
- **Conditional Processing**: Based on some real-time conditions or configurations, you might want to jump over specific messages or go back to previous ones.
### Pausing, Seeking and Rate-Limiting / Using the `#seek` API / Smart Seek Capabilities
At its core, the Smart Seek feature is a mechanism that prevents unnecessary `#seek` operations. In typical Kafka clients, invoking the `#seek` method can lead to the purging of prefetch buffers, which in turn can result in increased network usage as discarded messages are re-fetched. However, not every `#seek` operation results in a change in cursor position.
Karafka's Smart Seek feature checks whether a `#seek` operation would effectively change the cursor position. If the operation doesn't change the position, the `#seek` is ignored. This is not just an optimization to reduce unnecessary operations but also plays a crucial role in preserving the integrity and efficiency of prefetch buffers.
Benefits of Smart Seek:
- **Buffer Integrity**: One of the most significant benefits is preserving prefetched messages. Since unnecessary `#seek` operations are ignored, the prefetch buffers aren't purged without cause. This results in better utilization of fetched messages and reduces the need to re-fetch them, thus saving network resources.
- **Reduced Network Traffic**: By preventing unnecessary #seek operations, Karafka ensures that there's less need to re-fetch messages from the broker, which subsequently leads to reduced network traffic.
- **Efficiency and Performance**: Ignoring #seek operations that don't change the cursor's position means fewer operations for the consumer to handle, leading to more efficient processing and reduced latency.
- **Smart Pausing**: The Smart Seek logic extends to the `#pause` functionality. Just like with seeking, Karafka checks if pausing would be redundant and, if so, ignores the operation. This smart behavior ensures optimal performance even when applications try to pause consumption frequently.
## Pausing, Seeking and Rate-Limiting / `#pause` and `#seek` Usage Potential Networking Impact
When using the `#pause` or `#seek` method in Karafka, you're essentially instructing the system to halt the fetching of messages for a specific topic partition. However, this is not just a simple "pause" in the regular sense of the word.
When one of those methods is invoked, Karafka stops fetching new messages and purges its internal buffer that holds messages from that specific partition. It's essential to recognize that Karafka, by default, pre-buffers 1MB of data per topic partition for efficiency reasons. This buffer ensures that there is always a consistent supply of messages ready for processing without constantly waiting for new fetches.
The challenge arises here: If you use the `#pause` or `#seek` method frequently and for short durations, you might inadvertently create substantial network traffic. Every time you resume from a pause or seek to a location, Karafka will attempt to re-buffer the 1MB of data, which can result in frequently re-fetching the same data, thereby causing redundant network activity.
### Pausing, Seeking and Rate-Limiting / `#pause` and `#seek` Usage Potential Networking Impact / The Impact of Purging Prefetched Messages
- **Network Traffic Increase**: Whenever `#seek` or `#pause` is called, all prefetched messages for the partition are discarded. If a consumer then needs to read messages that were in the now-purged prefetch cache, it has to request them from the broker again, resulting in additional network traffic.
- **Increased Latency**: As previously mentioned, prefetched messages reduce consumer latency. Purging them means the consumer might need to wait for the broker to deliver messages that it once had in its prefetch cache.
- **Wasted Resources**: Messages prefetched but never consumed due to a `#seek` operation represent wasted resources. These messages were fetched from the broker, occupying network bandwidth, and were stored in memory, consuming RAM, all for no benefit.
- **Broker Load**: Continuously bringing messages from the broker due to prefetch purges increases the broker's work. The broker has to handle more fetch requests and serve more data, potentially affecting its performance.
### Pausing, Seeking and Rate-Limiting / `#pause` and `#seek` Usage Potential Networking Impact / Potential Solutions
- **Adjust Buffer Size**: If you're pausing and resuming often, consider adjusting the `fetch.message.max.bytes` setting for affected topics. This will lower the buffer size to reduce the volume of redundant data fetched, but do note that this might affect performance during regular operations.
- **Optimize Pause Usage**: Reevaluate your use cases for the `#pause` method. Perhaps there are ways to minimize its usage or extend the duration of pauses to reduce the frequency of data re-fetches.
- **Monitor and Alert**: Set up alerts to notify you of a spike in network traffic or frequent use of the `#pause` method. This way, you can quickly address any issues or misconfigurations.
### Pausing, Seeking and Rate-Limiting / `#pause` and `#seek` Usage Potential Networking Impact / Cost Implications with Third-party Providers
It's crucial to be aware, especially if you're using a third-party Kafka provider that charges based on the number of messages sent, that frequent pausing and resuming can inflate costs. This is due to the aforementioned frequent prefetching of the same data, which can result in the same messages being counted multiple times for billing purposes. Always ensure alignment and configuration are optimized to prevent unnecessary financial implications.
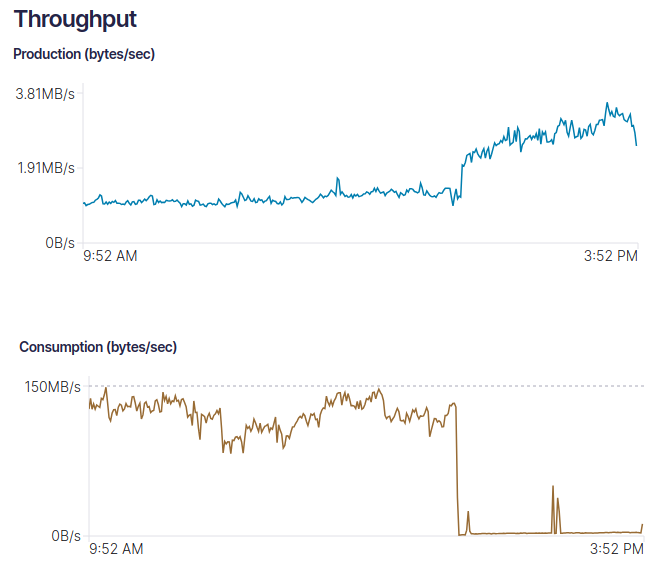
*This example showcases the consequences of improperly using #seek (as seen on the left) versus the improved results after consulting with the Karafka team. The daily network traffic resulting from such misuse came with a hefty price tag of USD 2,500 daily.
### Pausing, Seeking and Rate-Limiting / `#pause` and `#seek` Usage Potential Networking Impact / Summary
In conclusion, while the `#pause` and `#seek` methods in Karafka provide valuable functionalities, it's vital to understand their implications regarding system performance and potential costs. Proper configuration and mindful usage can help leverage its benefits while mitigating downsides.
---
## Pausing, Seeking and Rate-Limiting / See Also
- [Persistent Pausing](https://karafka.io/docs/Operations-Persistent-Pausing.md) - Implementing persistent topic pausing for planned maintenance using Filtering API
- [Filtering API](https://karafka.io/docs/Pro-Filtering-API.md) - Building custom filters with pause and seek capabilities
- [Web UI Commanding: Pause and Resume Partitions](https://karafka.io/docs/Pro-Web-UI-Commanding.md#pause-and-resume-partitions) - Emergency partition pausing via Web UI
- [Rate Limiting](https://karafka.io/docs/Pro-Rate-Limiting.md) - Advanced rate limiting using the Filtering API
---
*Last modified: 2026-02-15 21:11:18*