| Setting | Description | Tuning Tips | Default |
|---|---|---|---|
max_wait_time
|
Maximum time a consumer will wait for messages before delegating them for processing. |
|
1000 ms (Karafka) |
max_messages
|
Maximum number of messages a consumer processes in a single batch. |
|
100 (Karafka) |
fetch.wait.max.ms
|
Maximum time the consumer waits for the broker to fill the fetch request with fetch.min.bytes worth of messages. |
|
500 ms (librdkafka) |
fetch.min.bytes
|
Minimum amount of data the broker should return for a fetch request. |
|
1 byte (librdkafka) |
fetch.message.max.bytes
|
Initial maximum number of bytes per topic+partition to request when fetching messages from the broker. |
|
1048576 bytes (1 MB) (librdkafka) |
fetch.error.backoff.ms
|
Wait time before retrying a fetch request in case of an error. |
|
500 ms (librdkafka) |
enable.partition.eof
|
Enables the consumer to raise an event when it reaches the end of a partition. |
|
false (librdkafka) |
queued.max.messages.kbytes
|
Maximum number of kilobytes of queued pre-fetched messages in the local consumer queue. |
|
65536 KB (65 MB) (librdkafka) |
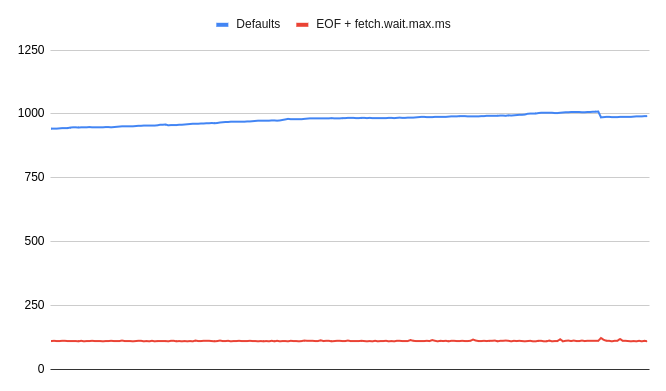
*Latency in ms on low-volume topic with different configurations (less is better).
The presented example illustrates how big of an impact latency configuration can have. Proper configuration tuning can tremendously impact the Karafka data ingestion patterns. #### Latency and Throughput / Consumer Management / Configuration Tuning / Per Topic Configuration In Karafka, you can configure settings per topic. This allows you to tailor the configuration to the specific needs of different topics, optimizing for various use cases and workloads. However, it's important to understand the implications of such configurations. When reconfiguring settings per topic, Karafka will create a distinct subscription group and an independent connection to Kafka for each topic with altered non-default settings. This isolation ensures that the specific configurations are applied correctly but also means that these topics will be managed independently, which can impact resource usage and system behavior. ```ruby class App < Karafka::App setup do |config| config.kafka = { 'bootstrap.servers': 'localhost:9092', 'max.poll.interval.ms': 300_000, } config.shutdown_timeout = 60_000 config.max_wait_time = 5_000 # Default max_wait_time for all topics config.max_messages = 50 # Default max_messages for all topics end routes.draw do # This topic will use only defaults topic :default_topic do consumer DefaultConsumer end # This topic will use defaults that were not overwritten and special kafka level settings topic :custom_topic do consumer CustomConsumer # Custom max_messages for this topic max_messages 200 # It is important to remember that defaults are **not** merged, so things like # `bootstrap.servers` need to be provided again kafka( 'bootstrap.servers': 'localhost:9092', 'fetch.wait.max.ms': 200, 'queued.max.messages.kbytes': 50_000 ) end end end ``` ### Latency and Throughput / Consumer Management / Parallel Processing Aside from the fast polling of data from Kafka, Karafka optimizes the processing phase to reduce latency by processing more data in parallel. Even when data is in the in-process buffer, latency increases if it cannot be processed promptly. Karafka leverages native Ruby threads and supports multiple concurrency features to handle processing efficiently. !!! warning "Polling-Related Factors Affecting Parallel Processing" Various polling-related factors can impact Karafka's ability to distribute and process obtained data in parallel. In some scenarios, the nature of the data or how it is polled from Kafka may prevent or reduce Karafka's ability to effectively distribute and process work in parallel. It's important to consider these factors when configuring and tuning your Karafka setup to ensure optimal performance. Below, you can find a table summarizing the key aspects of Karafka's parallel processing capabilities, along with detailed descriptions and tips for optimizing latency and throughput:| Aspect | Details | Tips |
|---|---|---|
| Concurrent Processing of Messages |
Karafka uses multiple threads to process messages concurrently.
|
|
| Consumer Group Management | Each consumer group is managed by a separate thread allowing for efficient data prefetching and buffering. |
|
| Swarm Mode for Enhanced Concurrency | Forks independent processes to optimize CPU utilization, leveraging Ruby's Copy-On-Write (CoW) mechanism. It may enhance throughput and scalability by distributing the workload across multiple CPU cores. |
|
| Subscription Groups for Kafka Connections | Karafka organizes topics into subscription groups to manage Kafka connections efficiently. Each subscription group operates in a separate background thread, sharing the worker pool for processing. |
|
| Virtual Partitions | The Virtual Partitions feature allows for parallel processing of data from a single partition. |
|
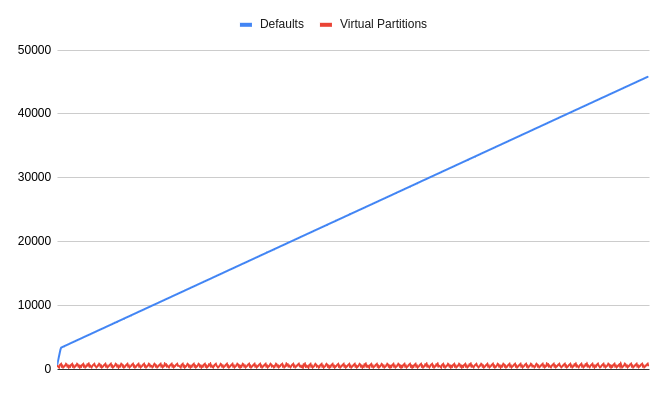
*Latency in ms on a partition with and without Virtual Partitions enabled (same traffic) with around 150ms of IO per message.
The presented example illustrates a growing latency due to the non-virtualized processing's inability to keep up with the steady pace of messages because of the IO cost. Work is distributed across multiple threads in the case of Virtual Partitions so the system can keep up. ### Latency and Throughput / Consumer Management / Prefetching Messages Karafka is designed to prefetch data from Kafka while previously obtained messages are being processed. This prefetching occurs independently for each subscription group, ensuring continuous data flow as long as more data is available in Kafka. Prefetching behavior is governed by several settings mentioned in previous sections, such as `queued.max.messages.kbytes`, `fetch.wait.max.ms`, `fetch.min.bytes`, and `fetch.message.max.bytes`. #### Latency and Throughput / Consumer Management / Prefetching Messages / Prefetching Behavior ##### Latency and Throughput / Consumer Management / Prefetching Messages / Prefetching Behavior / Normal Operations Under normal operations, when there are no significant lags, Karafka prefetches some data from each assigned topic partition. This is because there is little data ahead to process. For example, if 200 messages are available for processing from 10 partitions, Karafka might prefetch these messages in small batches, resulting in 10 independent jobs with 20 messages each.

*This example illustrates the work distribution of prefetched data coming from two partitions.
##### Latency and Throughput / Consumer Management / Prefetching Messages / Prefetching Behavior / Data Spikes and Lags The situation changes when Karafka experiences data spikes or when a significant amount of data is ahead. In such cases, Karafka will prefetch data in larger batches, especially with default settings. This can reduce Karafka's ability to parallelize work, except when using virtual partitions. Karafka may prefetch large chunks of data from a single topic partition during these periods. For instance, it may prefetch 500 messages from one partition, resulting in a single job with 200 messages from that partition, thus limiting parallel processing. This behavior is driven by the need to process data quickly. Still, it can lead to reduced parallelism when large batches from a single partition dominate the internal buffer.

*This example illustrates the lack of work distribution of prefetched data when batch comes from a single partition.
#### Latency and Throughput / Consumer Management / Prefetching Messages / Optimizing Prefetching for Parallelism To mitigate the impact of large batch prefetching under lag conditions and to enhance system utilization, consider the following strategies: 1. **Prefetching Configuration Tuning**: Adjust prefetching-related settings such as `queued.max.messages.kbytes`, `fetch.wait.max.ms`, `fetch.min.bytes`, and `fetch.message.max.bytes` to fine-tune the balance between throughput and latency. Tailoring these settings to your specific workload can optimize prefetching behavior. 1. **Multiple Subscription Groups**: Configure multiple subscription groups to ensure that data from independent partitions (across one or many topics) is prefetching and processing independently. This setup can enhance system utilization, reduce latency, and increase throughput by allowing Karafka to handle more partitions concurrently. 1. **Connection Multiplexing**: Use connection multiplexing to create multiple connections for a single subscription group. This enables Karafka to independently prefetch data from different partitions, improving parallel processing capabilities. 1. **Virtual Partitions**: Implement virtual partitions to parallelize processing within a single partition, maintaining high throughput even under lag conditions. #### Latency and Throughput / Consumer Management / Prefetching Messages / Prefetching with Single Partition Assignments If a Karafka consumer process is assigned only one topic partition, the prefetching behavior is straightforward and consistently fetches data from that single partition. In such cases, there are no concerns about parallelism or the need to distribute the processing load across multiple partitions or subscription groups. Your processing can still greatly benefit by using [Virtual Partitions](https://karafka.io/docs/Pro-Virtual-Partitions.md). #### Latency and Throughput / Consumer Management / Prefetching Messages / Conclusion Understanding and configuring the prefetching behavior in Karafka is crucial for optimizing performance, especially under varying data loads. By adjusting settings and utilizing strategies like multiple subscription groups and connection multiplexing, you can enhance Karafka's ability to parallelize work, reduce latency, and increase throughput. This ensures that your Karafka deployment remains efficient and responsive, even during data spikes and lags recovery. ### Latency and Throughput / Consumer Management / Subscription Group Blocking Polls Karafka is designed to prebuffer data to ensure efficient message processing. Still, it's important to understand that this prefetched data is not utilized until all jobs based on data from the previous batch poll are completed. This behavior is by design and is a common characteristic of Kafka processors, not just in Ruby. This approach prevents race conditions and ensures data consistency. The poll operation in Kafka acts as a heartbeat mechanism governed by the `max.poll.interval.ms` setting. This interval defines the maximum delay between poll invocations before the consumer is considered dead, triggering a rebalance. By ensuring that all jobs from the previous poll are finished before new data is used, Karafka maintains data integrity and avoids processing the same message multiple times. #### Latency and Throughput / Consumer Management / Subscription Group Blocking Polls / Impact of Uneven Work Distribution When a subscription group fetches data from multiple topics with uneven workloads (one topic with a lot of data to process and one with less), the smaller topic can experience increased latency. This happens because the consumer will only start processing new data after completing all jobs from the previous poll, including the large dataset. Consequently, messages from the less busy topic must wait until the more intensive processing is finished. Similarly, uneven work distribution with virtual partitions can lead to similar latency issues. If the partition key or reducer used for virtual partitions is not well balanced, certain virtual partitions may have significantly more data to process than others. This imbalance causes delays, as the consumer will wait for all data from the more loaded partitions to be processed before moving on to the next batch. #### Latency and Throughput / Consumer Management / Subscription Group Blocking Polls / Recommendations for Mitigating Latency Issues To address these issues, consider the following strategies: 1. **Multiplexing**: Use connection multiplexing to create multiple connections for a single subscription group. This allows Karafka to fetch and process data from different partitions independently, improving parallel processing and reducing latency. 2. **Multiple Subscription Groups**: Configure multiple subscription groups to distribute the workload more evenly. By isolating topics with significantly different workloads into separate subscription groups, you can ensure that heavy processing on one topic does not delay processing on another. 3. **Monitoring and Tuning Work Distribution**: Regularly monitor the performance and work distribution of your virtual partitions. Ensure that your partition key and reducer are well-balanced to avoid uneven workloads. Fine-tuning these elements can help maintain efficient and timely processing across all partitions. ### Latency and Throughput / Consumer Management / Summary Managing consumers in Karafka involves numerous internal and external factors. Each case presents unique challenges, requiring a tailored approach to optimization. Consumer management is influenced by data types, infrastructure, processing nature (CPU vs. IO-intensive), data volume, and worker threads. Key Karafka settings like `max_wait_time`, `max_messages`, and `fetch.wait.max.ms` play a crucial role in data fetching and processing efficiency. External factors, such as infrastructure setup, network conditions, and data production patterns, can significantly impact performance. To stay ahead of these potential issues, it's crucial to emphasize the need for regular monitoring of consumption and processing latency. This practice is key to identifying bottlenecks and ensuring the system's responsiveness. Optimization strategies, including multiple subscription groups, connection multiplexing, and virtual partitions, help balance workloads and enhance parallel processing. Each use case demands a unique configuration, underscoring the need for a thorough understanding of the framework and application requirements. In conclusion, effective consumer management in Karafka requires considering various factors and regular adjustments to maintain efficiency and responsiveness. --- ## Latency and Throughput / See Also - [Concurrency and Multithreading](https://karafka.io/docs/Concurrency-and-Multithreading.md) - Understanding threading model and its impact on performance - [Virtual Partitions](https://karafka.io/docs/Pro-Virtual-Partitions.md) - Parallel processing for improved throughput - [Resources Management](https://karafka.io/docs/Resources-Management.md) - Managing memory and CPU resources effectively - [Monitoring and Logging](https://karafka.io/docs/Operations-Monitoring-and-Logging.md) - Tracking performance metrics and identifying bottlenecks --- *Last modified: 2026-02-24 09:34:26*